标签:encode 读取 span 字符 orm super code logger image
目录:
1.集合
2.文件操作
3.编码转换
4.函数
集合是无序的
list_1 = [1,4,5,7,3,6,7,9] list_1 = set(list_1) list_2 =set([2,6,0,66,22,8,4]) print(list_1,list_2)
执行结果:
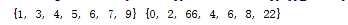
#交集 print(list_1 & list_2) #union print(list_2 | list_1) #difference print(list_1 - list_2) # in list 1 but not in list 2 #对称差集 print(list_1 ^ list_2)
执行结果:
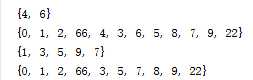
#添加一个 list_1.add(999) #添加多个 list_1.update([888,777,555]) print(list_1)
执行结果:
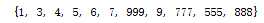
#删除一个值 print(list_1.pop()) print(list_1.pop()) #删除指定值 list_1.discard(999) print(list_1)
执行结果:

open文件的读写追加参数:
r :读模式
w:写模式(清空原内容,在写入)
a:末尾追加模式
f = open(‘test‘,‘r+‘,encoding=‘utf-8‘) date = f.read() print(date) f.close()
注意with open() 和上面打开读取文件的open() 都是 打开文件的方法,区别在于 with open()打开的文件在 with open()的子代码结束后会自动关闭文件
而open()打开的文件需要手动close()关闭
import time
time_format=‘%Y-%m-%d %X‘ #时间的格式%Y年 %m月 %d日 %X时分秒
time_current=time.strftime(time_format) #赋值当前时间到变量
with open(‘log‘,‘a‘) as f:
f.write(‘%s hehehehe\n‘ %(time_current))
执行结果(类似于写日志):

f = open("test","r",encoding="utf-8")
f_new = open("test_new","w",encoding="utf-8")
for line in f: #逐行读取文件内容
if "楚风" in line: #比对 楚风 是否在内容中
line = line.replace("楚风","水银灯") #replace 字符串的替换
f_new.write(line) #把内容写入新的文件
f.close() #关闭文件
f_new.close() #关闭文件
执行结果:

一句话:非Unicode编码要想转换成其他编码 需要先decode()成Unicode,然后在encode()成要转换的编码
def 定义过程或者函数
#过程 = 没有return的函数,在ptyhon中过程会有一个隐式的返回值 return none def func1(): "双引号内写用途描述,可写可不写,建议写" print(‘you are super star...‘) #函数 def func2(x): "双引号内写用途描述,可写可不写,建议写" print(x) return 0 def func3(y,z): print(‘you are %s %s...‘ %(y,z)) return 1,‘syd‘,[‘a‘,1],{‘福州‘:[‘仓山‘,‘鼓楼‘]} def func4(d,e): print(‘you are %s %s...‘ %(d,e)) return d #默认参数 ,调用的时候不传g的值 则取默认值g=2 如果调用的时候传递g的值 则以传递的值为准 def func5(f,g=2): print(f,g) return 0 a = func1() b = func2(‘hehed‘) c = func3(‘super‘,1) s = func4(e=‘super‘,d=1) print(a) print(b) print(c) print(s) func5(6) func5(6,99)
执行结果:

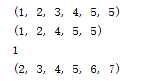
#参数组 #*args:接受N个位置参数,转换成元组形式 def test(*args): print(args) test(1,2,3,4,5,5) #建议使用这种写法 test(*[1,2,4,5,5])# args=tuple([1,2,3,4,5]) def test1(x,*args): print(x) print(args) test1(1,2,3,4,5,6,7)
执行结果:
#**kwargs:接受N个关键字参数(格式:a=b),转换成字典的方式 def test2(**kwargs): print(kwargs) print(kwargs[‘name‘]) print(kwargs[‘age‘]) print(kwargs[‘sex‘]) test2(name=‘alex‘,age=8,sex=‘F‘) #建议这种写法 test2(**{‘name‘:‘alex‘,‘age‘:8,‘sex‘:‘f‘}) def test3(name,**kwargs): print(name) print(kwargs) test3(‘alex‘,age=18,sex=‘m‘) def test4(name,age=18,**kwargs): print(name) print(age) print(kwargs) test4(‘alex‘,age=34,sex=‘m‘,hobby=‘tesla‘)
执行结果:

def test4(name,age=18,*args,**kwargs): print(name) print(age) print(args) print(kwargs) logger("TEST4") def logger(source): print("from %s" % source) test4(‘alex‘,age=34,sex=‘#m‘,hobby=‘tesla‘)
执行结果:

标签:encode 读取 span 字符 orm super code logger image
原文地址:http://www.cnblogs.com/syd-cmr/p/7588563.html