标签:自己的 性能 进程锁 判断 async 技术 状态 服务 模式
多进程,进程queue,pipe管道,进程锁,进程池,协程,5种网络模式(阻塞io,非阻塞io,信号驱动io,io多路复用,异步io)
多进程
import multiprocessing

每个进程都会由他的父进程进行启动
windows中是pycharm
linux中是 multiprocessing
获得进程id
import os
#获取子进程id
print(os.getppid())
#获取父进程id
print(os.getpid())
输出
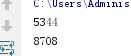
进程queue 数据不是共享
同一个进程中的线程 内存是共享的 用之前的线程队列传输数据
但是进程之间内存不是共享的,进程之间的数据通信就用到了
进程queue,它和线程queue不一样,它是相当于复制了一份在其他进程中。
from multiprocessing import Process, Queue
def f(qq):
#在子进程中给 进程queue添加数据
qq.put([42, None, ‘hello‘])
if __name__ == ‘__main__‘:
#在父进程中创建一个进程queue队列
q = Queue()
#创建一个进程对象,进程queue作为参数放入进去
p = Process(target=f, args=(q,))
#启动一个进程
p.start()
print(q.get())
p.join()
输出如下:
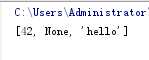
pipe管道 数据不是共享,只是复制一份
两个进程之间的通信 还可以用到管道 pipe 类似于scoket一个发一个收
manager进程数据共享
from multiprocessing import Process, Manager
def f(d, l):
‘‘‘此方法用于被进程执行‘‘‘
d[1] = ‘1‘
d[‘2‘] = "wwwww"
l=["A","B"]
print(l,d)
if __name__ == ‘__main__‘:
#等于 manager= Manager()
with Manager() as manager:
d = manager.dict() #创建一个字典用于进程之间的数据共享
l = manager.list()#创建一个列表用于进程之间的数据共享
p_list = [] #为了循环join的列表
for i in range(10):#循环10次创建10个进程
p = Process(target=f, args=(d, l))#创建进程 把字典和列表传进去
p.start()
p_list.append(p)
for res in p_list:
res.join()
print(d)
print(l)
进程锁
进程锁存在的目的是为了 多个进程打印数据时不会乱
保证每个进程同一时间单独占一块屏幕
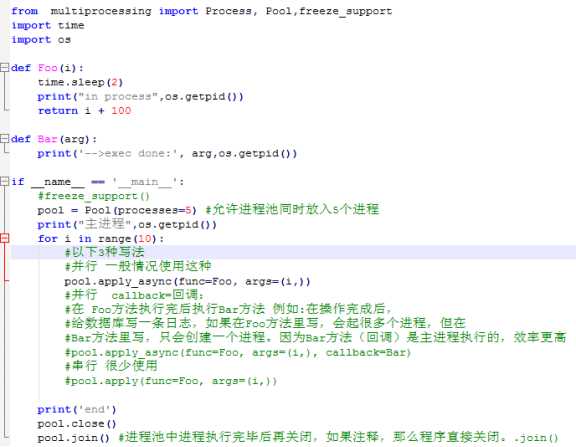
进程池
进程池的作用 多进程时机器开销很大 进程池保证在这段代码在同一时间
运行进程的个数,避免系统开销过大而挂掉
线程是没有线程池的,因为它的开销很小。需要可以用信号量自己写一个
协程
协程被称为微线程,是一种用户级的轻量级线程,拥有自己的寄存器上下文和栈
可以对任务不停的上下切换。并独立保存上次离开的位置,避免串行 阻塞 造成的时间浪费,从而大幅度提高效率。
效果类似于多线程,却又不同
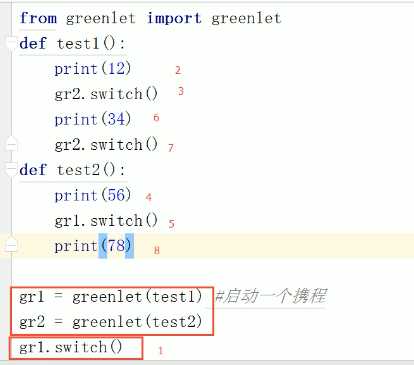
1.在切换时
不管进程或者线程 每次阻塞 切换都需要系统调用,先让cpu跑操作系统的调用程序,然后再由调度程序判断跑那个 线程或进程
但协程是程序自身控制的,就没有了线程切换的开销。和多线程比,线程的数量越多,协程的优势就越明显。
2.线程锁(互斥锁)
协程因为只有一个线程,所以也不存在同时写变量冲突,在协程中不需要加锁,只判断状态就好,说以效率比多线程高很多。
利于cpu多核时 可以多进程+协程 充分利用了多核,又发挥了协程的高效率。
手动协程 greenlet
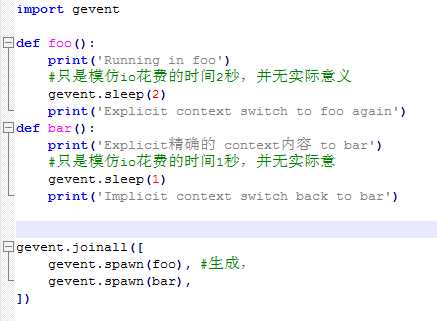
协程 超级自动版 gevent 最常用
封装了手动协程(greenlet),在遇到io操作时,会自动切换到下一个方法,当下一个方法遇到io操作时,又切换回去。这就避免了因为等待io执行而造成的时间浪费。
如下图 线程正常串行遇到io就等待 总共需要3秒,而协程只需要2秒
如果协程方法需要参数,参照如下 f是方法,后边是参数

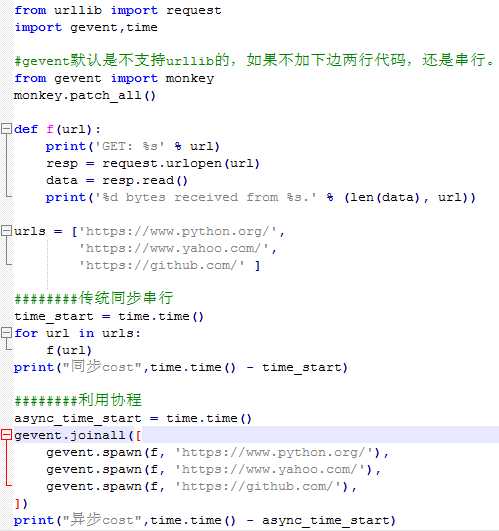
最简单的爬取网页 相当于下载
利用了协程
协程实现socekt
客户端

服务端

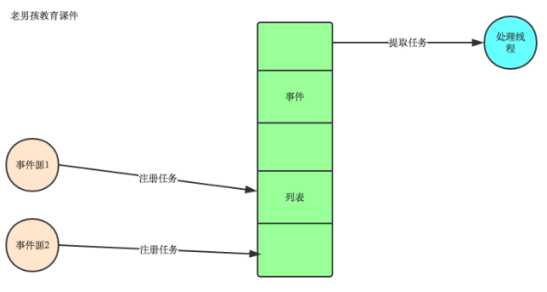
事件驱动型
现在的ui编程都是事件驱动型的
点击一个任务,比如打开一个文本。会把这个事件放入一个队列中去,
然后有一个线程去处理队列中的事件。这样就避免了 鼠标或者键盘引起的阻塞。
linux举例
内存空间分为
内核空间 操作系统内核运行的空间
独立于普通的应用程序 可以访问底层硬件 受保护的内存空间
用户空间
运行程序运行的空间
内核空间的内存 和 用户空间的内存不是共享的
在写scoket,发送数据时,发现程序不是立刻发送,而是等待缓存的阈值满了之后才发送。这是因为 内核空间 需要把数据拷贝到 用户空间,这些数据拷贝操作所带来的 CPU 以及内存开销是非常大的,所以才有了缓存。数据攒多了,一起发送。
一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。所以说,当一个read操作发生时,它会经历两个阶段:
1. 等待数据准备 (Waiting for the data to be ready)
2. 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
因为以上两种方式,所以产生了以下5种网络模式
阻塞io 单线程下,只能维护一个scoket链接 等待数据和拷贝数据两个阶段都属于阻塞状态
非阻塞io 单线程下,当用户进程发出reav操作的时候,如果内核的数据没有准备好,不会阻塞,而是返回error。
信号驱动io
IO多路复用
特点:在单线程成下,可以循环维护多个scoket连接,任意一个数据准备就绪,就会返回给用户 拷贝数据于阻塞状态
io多路复用的三种模式:
select()几乎在所有的平台都支持,默认只能维护1024个scoke t。
另外有如果有1000个连接,只有最后一个连接返回数据。那么会循环9999次,很浪费性能。
poll()属于过度阶段
epoll()不支持windows 支持linux
nigix 说是异步io 其实是io多路复用 epoll模式
有点 如果有1000个连接,有一个连接有数据,内核会告诉哪个连接有数据,用户直接获取即可。
异步io 不会对用户进程产生阻塞,内核会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,内核才会给用户发送信号,告诉read操作完成了。没有任何阻塞。
异步io用的很少 有个专门的模块asyncio
标签:自己的 性能 进程锁 判断 async 技术 状态 服务 模式
原文地址:http://www.cnblogs.com/HL-blog/p/7687797.html