标签:它的 时间 变化 分享 但我 支持 目标 很多 分类算法
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~
作者:林浩威
随着人工智能的大热,越来越多的小伙伴们开始投身到机器学习的大潮中。作为其中的一员,我对此也是极有兴趣的。当然我更感兴趣的,是怎么利用这些有趣的算法,来实现脑海里各种奇奇怪怪的点子。写这篇文章的契机,是我在某天看完腾讯指数的推送后,突发奇想,想自己实现类似这样的一个东西,感觉蛮好玩的。然后就在上周末,利用了一些空余时间,写了一个简单的舆情监控系统。
基于机器学习的舆情监控,这样的一个想法,其实可以有很大的想象空间,可以做很多有意思的事情。比如可以关注你喜欢的明星或电影的口碑情况,或者了解你所关注股票的舆论变化,甚至预测其未来的走向等等。但我决定先从最简单的例子入手:就是从新浪微博中,识别出关于腾讯的正面或负面的新闻。本文的论述也将围绕这个场景展开,不会涉及太多复杂难懂的东西,可以说是很简单的一个东西,请放心阅读。
技术上的实现,主要是用sklearn对采集到的微博文本做分类训练,关于sklearn就不需要介绍了,很有名的一个python机器学习工具,如果想详细地了解可以移步它的官网:http://scikit-learn.org 。
下面是我们接下来需要做的所有工作:
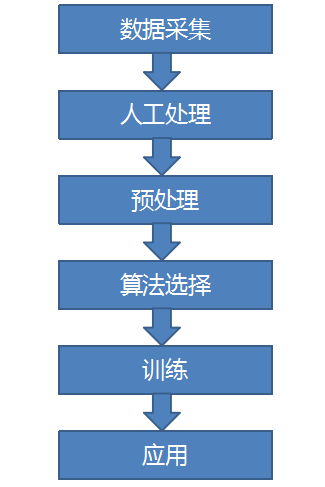
机器:mac
语言:python
第三方库:sklearn、jieba、pyquery 等
数据采集是对我来说是最好做的一步,其实就是写爬虫从各大网站收集大量的信息,存起来,以便我们后续分析处理。如下图:
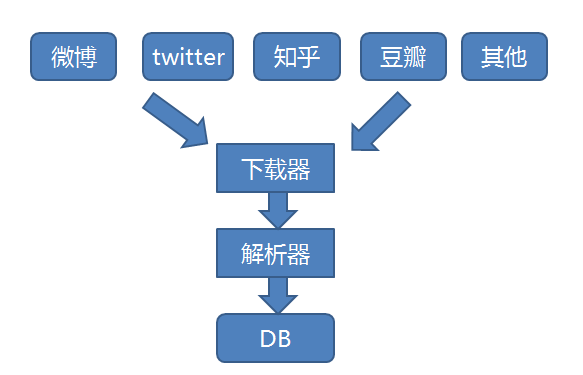
因为这只是一个试验性的兴趣项目,没办法花太多时间投入,所以我这次只打算从微博的搜索结果中,取1000条数据来分析。当然如果有可能的话,数据越多越好,训练出来的模型就越准确。
采集的页面是百度的微博搜索结果页:https://www.baidu.com/s?wd=腾讯&pn=0&tn=baiduwb&ie=utf-8&rtt=2
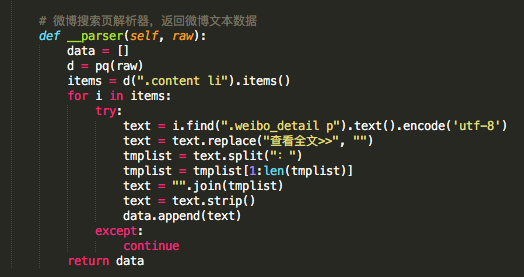
用python对该页面逐页抓取,然后用pyquery模块对抓取到的页面进行解析,得到一条条的微博文本。下面贴下这个页面的解析代码:
这一步是最苦逼也是最花时间的一步,我们需要把采集到的数据,一条条精确地人工分类整理好,才能给后续的算法训练使用。如果你的场景在网上能找到现成的训练数据集,那么恭喜你已经节省了大把时间,但大多数情况还得自己来,所有脏活累活都在这了。而且人工分类的准确性,也决定了训练出来的模型的准确性,所以这一步的工作也是至关重要的。
我们的目标是把消息分为“正面”、“负面”和“中性”三个类别。首先我们要先给这三个类别下一个明确的定义,这样在分类的时候才不会迷茫。我个人给它们下的定义是:
正面:有利的新闻、积极正面的用户言论;
负面:不利的新闻、消极反面的用户言论;
中性:客观提及的新闻、不带感情色彩的用户言论。
按照上面的标准,我们把采集到的1000条微博一一分类标记好。
采集过来的微博文本,带有很多无效的信息,在开始训练之前,我们需要对这些文本做预处理,并保存为sklearn能接收的数据,主要工作包括:
1、去杂质,包括表情符号、特殊符号、短链接等无效信息,这里用正则过滤掉即可,不再详细描述;
2、保存为文本文件,因为sklearn要求训练数据以特定的格式存放在本地目录,所以我们需要用脚本对原数据进行处理,目录格式如下:
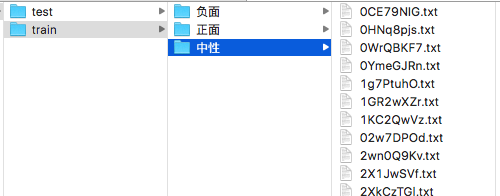
train:存放待训练的数据,子目录名称为分类名,子目录下存放训练文本文件,文件名随意,内容为单条微博文本;
test:存放带测试的数据,子目录名称随意,在子目录下存放测试文本文件。
建议训练集和测试集按8:2的比例划分,用python自动生成以上的本地文件。
3、分词,因为微博的数据大部分都是中文,所以推荐用jieba分词,对中文的支持比较给力,效果也很好。支持自定义词典,支持返回指定词性的分词结果,可以去除一些停用词和语气助词等。使用起来也很简单,这里不详细介绍,有需要可以访问它的github地址:https://github.com/fxsjy/jieba
准备好训练数据之后,我们就可以开始训练了,为此我们需要选择一个合适的分类算法。但机器学习算法那么多,如果一个个去测试对比,将花费我们不少精力。幸好sklearn已经考虑到了这个问题,并提供了一个算法选择方案。通过把多个算法的运行结果进行图形化对比,可以很直观的看到哪个算法比较合适。
这个是官方提供的测试代码:http://scikit-learn.org/stable/auto_examples/text/document_classification_20newsgroups.html#example-text-document-classification-20newsgroups-py
把这个官方案例的数据输入部分替换成自己的即可。结果如下图:
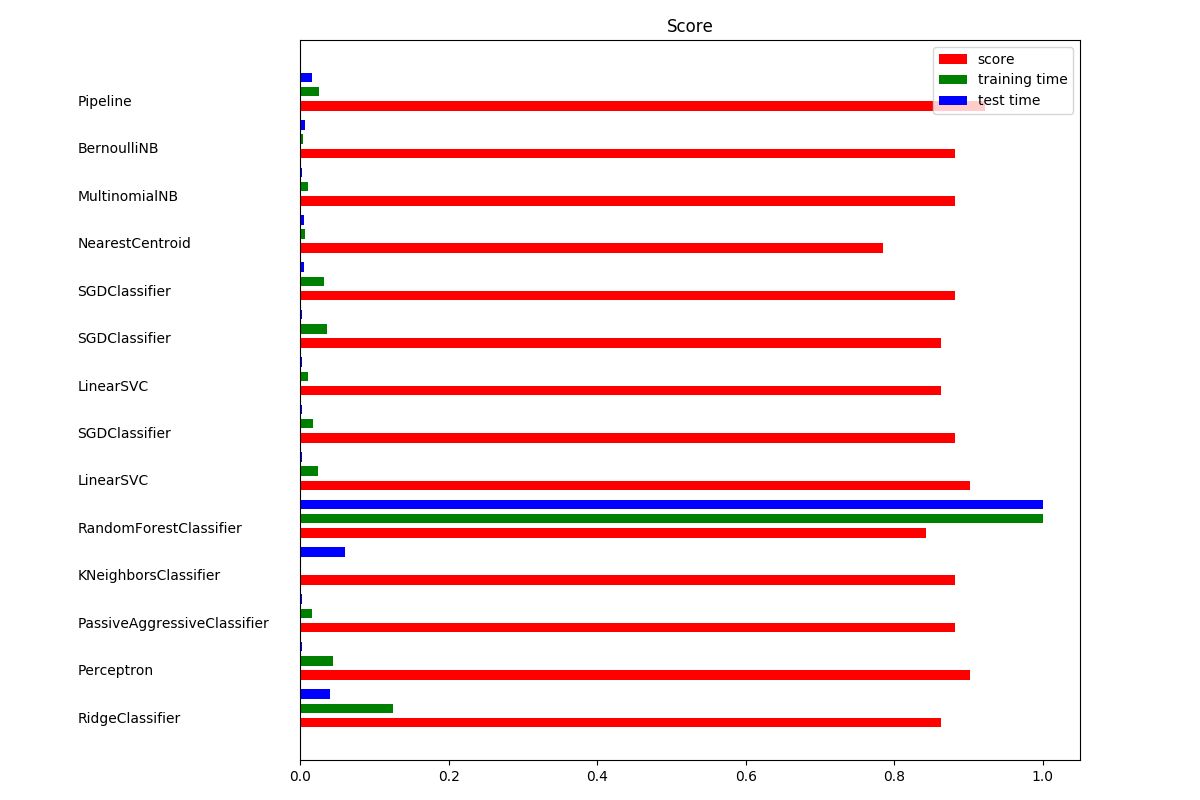
综合运算效率和得分情况,我选择了LinearSVC算法(SVM)来作为我的训练算法。
文本分类的训练主要有以下4个步骤:

这4个步骤 sklearn都已封装了相应的方法,所以使用起来极其方便。参考如下代码:
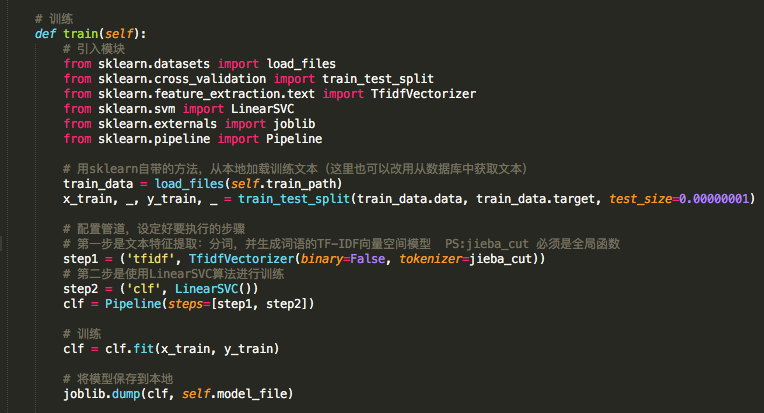
注:以上代码为了方便展示,把模块引入也放到方法内部了,仅作参考
最后就是对训练好的模型进行测试和应用。
通过已有的模型,对新的数据进行预测,代码如下:
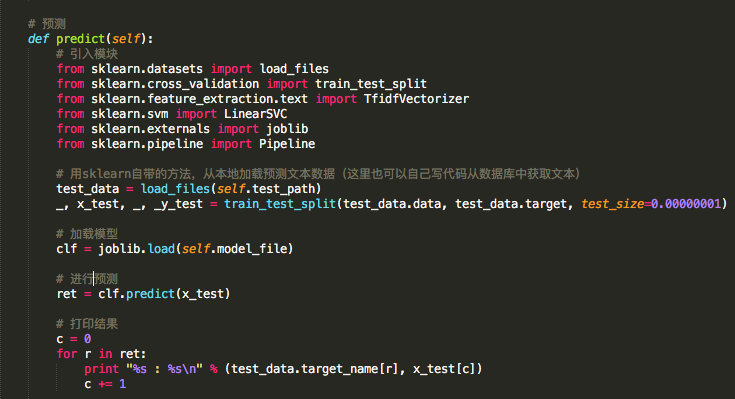
注:本代码只是展示用,仅作参考
打印出来的部分结果见下图:
经统计,预测的准确率为95%,该模型算出的当天腾讯相关的舆情如下:
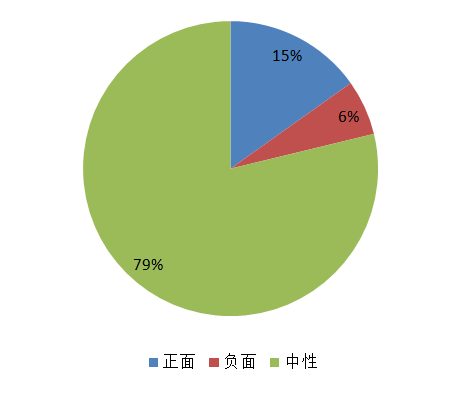
本文只是记录下我这两天的一些想法和试验过程,没有涉及太多代码实现或者其他高深的算法,相信不难看懂。如果有人感兴趣的话,后面我可以把源码整理完发布出来。
感谢阅读!
更快更准的异常检测?交给分布式的 Isolation Forest 吧
此文已由作者授权腾讯云技术社区发布,转载请注明文章出处
原文链接:https://cloud.tencent.com/community/article/515228
标签:它的 时间 变化 分享 但我 支持 目标 很多 分类算法
原文地址:http://www.cnblogs.com/qcloud1001/p/7699646.html