标签:nand net before 解决方案 xxx 更新 failure float dfa
1、不安全:大家都知道HashMap不是线程安全的,在多线程环境下,对HashMap进行put操作会导致死循环。是因为多线程会导致Entry链表形成环形数据结构,这样Entry的next节点将永远不为空,就会产生死循环获取Entry。具体内容见HashMap随笔。
2、不高效:Collections.synchronizedMap(hashMap)和HashTable的线程安全原理都是对方法进行同步,所有操作竞争同一把锁,性能比较低。
如何构造一个线程安全且高效的HashMap?ConcurrentHashMap登场。
ConcurrentHashMap将数据分为很多段(Segment),Segment继承了ReentrantLock,每个段都是一把锁。每个Segment都包含一个HashEntry数组,HashEntry数组存放键值对数据。当一个线程要访问Entry数组时,需要获取所在Segment锁,保证在同一个Segment的操作是线程安全的,但其他Segment的数据的访问不受影响,可以实现并发的访问不同的Segment。
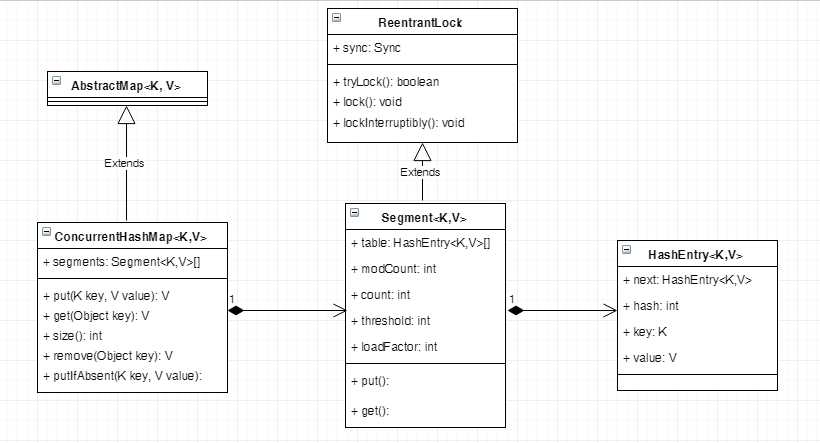
segmentShift和segmentMask的作用是定位Segment索引。以默认值为例,concurrencyLevel为16,需要移位4次(sshift为4),segmentShift就等于28,segmentMask等于15。
1 //initialCapacity:初始容量,默认16。 2 //loadFactor:负载因子,默认0.75。当元素个数大于loadFactor*最大容量时需要扩容(rehash) 3 //concurrencyLevel:并发级别,默认16。确定Segment的个数,Segment的个数为大于等于concurrencyLevel的第一个2^n。 4 public ConcurrentHashMap(int initialCapacity, 5 float loadFactor, int concurrencyLevel) { 6 //判断参数是否合法 7 if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0) 8 throw new IllegalArgumentException(); 9 //Segment最大个数MAX_SEGMENTS = 1 << 16,即65536; 10 if (concurrencyLevel > MAX_SEGMENTS) 11 concurrencyLevel = MAX_SEGMENTS; 12 13 // Find power-of-two sizes best matching arguments 14 int sshift = 0; 15 int ssize = 1; 16 //使用循环找到大于等于concurrencyLevel的第一个2^n。ssize就表示Segment的个数。 17 while (ssize < concurrencyLevel) { 18 ++sshift; //记录移位的次数, 19 ssize <<= 1;//左移1位 20 } 21 this.segmentShift = 32 - sshift; //用于定位hash运算的位数,之所以用32是因为ConcurrentHashMap里的hash()方法输出的最大数是32位的 22 this.segmentMask = ssize - 1; //hash运算的掩码,ssize为2^n,所以segmentMask每一位都为1。目的是之后可以通过key的hash值与这个值做&运算确定Segment的索引。 23 //最大容量MAXIMUM_CAPACITY = 1 << 30; 24 if (initialCapacity > MAXIMUM_CAPACITY) 25 initialCapacity = MAXIMUM_CAPACITY; 26 //计算每个Segment所需的大小,向上取整 27 int c = initialCapacity / ssize; 28 if (c * ssize < initialCapacity) 29 ++c; 30 int cap = MIN_SEGMENT_TABLE_CAPACITY;//每个Segment最小容量MIN_SEGMENT_TABLE_CAPACITY = 2; 31 //cap表示每个Segment的容量,也是大于等于c的2^n。 32 while (cap < c) 33 cap <<= 1; 34 //创建一个Segment实例,作为Segment数组ss的第一个元素 35 // create segments and segments[0] 36 Segment<K,V> s0 = 37 new Segment<K,V>(loadFactor, (int)(cap * loadFactor), 38 (HashEntry<K,V>[])new HashEntry[cap]); 39 Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize]; 40 UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0] 41 this.segments = ss; 42 }
可以分为三步:
1、定位Segment:通过Hash值与segmentShift、segmentMask的计算定位到对应的Segment;
2、锁获取:获取对应Segment的锁,如果获取锁失败,需要自旋重新获取锁;如果自旋超过最大重试次数,则阻塞。
3、插入元素:如果key已经存在,直接更新;如果key不存在,先判断是否需要扩容,若需要则执行rehash()后插入原因,否则直接存入元素。
为了高效,ConcurrentHashMap不会对整个容器进行扩容,而只对某个segment进行扩容。
Segment的扩容判断比HashMap更恰当,因为HashMap是在插入元素后判断元素是否已经到达容量的,如果到达了就进行扩容,但是很有可能扩容之后没有新元素插入,这时HashMap就进行了一次无效的扩容。
1 /**ConcurrentHashMap中方法**/ 2 public V put(K key, V value) { 3 Segment<K,V> s; 4 if (value == null) 5 throw new NullPointerException(); 6 int hash = hash(key); //计算hash值,hash值是一个32位的整数 7 //计算Segment索引 8 //在默认情况下,concurrencyLevel为16,segmentShift为28,segmentMask为15。 9 //先右移28位,hash值变为0000 0000 0000 0000 0000 0000 0000 xxxx, 10 //与segmentMask做&运算,就是取最后四位的值。这个值就是Segment的索引 11 int j = (hash >>> segmentShift) & segmentMask; 12 //通过UNSAFE的方式获取索引j对应的Segment对象。 13 if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck 14 (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment 15 s = ensureSegment(j); 16 //向Segment中put元素 17 return s.put(key, hash, value, false); 18 } 19 20 /**ConcurrentHashMap$Segment中方法**/ 21 //向Segment中put元素 22 final V put(K key, int hash, V value, boolean onlyIfAbsent) { 23 //获取锁。如果获取锁成功,插入元素,和普通的hashMap差不多。 24 //如果获取锁失败,执行scanAndLockForPut进行重试。重试设计见scanAndLockForPut方法源码。 25 HashEntry<K,V> node = tryLock() ? null : 26 scanAndLockForPut(key, hash, value); 27 V oldValue; 28 try { 29 HashEntry<K,V>[] tab = table; 30 int index = (tab.length - 1) & hash;//计算HashEntry数组索引 31 HashEntry<K,V> first = entryAt(tab, index); 32 for (HashEntry<K,V> e = first;;) { 33 if (e != null) { //该索引处已经有元素 34 K k; 35 36 //如果key相同,替换value。 37 if ((k = e.key) == key || 38 (e.hash == hash && key.equals(k))) { 39 oldValue = e.value; 40 //onlyIfAbsent=true参数表示如果key存在,则不更新value值,只有在key不存在的情况下,才更新。 41 //在putIfAbsent方法中onlyIfAbsent=true 42 //在put方法中onlyIfAbsent=false 43 if (!onlyIfAbsent) {Scans 44 e.value = value; 45 ++modCount;//修改次数 46 } 47 break; 48 } 49 e = e.next;//继续找下一个元素 50 } 51 else { 52 if (node != null) 53 node.setNext(first); 54 else 55 node = new HashEntry<K,V>(hash, key, value, first); 56 int c = count + 1; //count为ConcurrentHashMap$Segment中的域 57 if (c > threshold && tab.length < MAXIMUM_CAPACITY) 58 //如果元素数量超过阈值且表长度小于MAXIMUM_CAPACITY,扩容 59 rehash(node); 60 else 61 setEntryAt(tab, index, node);//将node节点更新到table中 62 ++modCount; 63 count = c; 64 oldValue = null; 65 break; 66 } 67 } 68 } finally { 69 unlock(); 70 } 71 return oldValue; 72 } 73 74 /**ConcurrentHashMap$Segment中方法**/ 75 //自旋获取锁 76 private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) { 77 //entryForHash根据hash值找到当前segment中对应的HashEntry数组索引。 78 HashEntry<K,V> first = entryForHash(this, hash); 79 HashEntry<K,V> e = first; 80 HashEntry<K,V> node = null; 81 int retries = -1; // negative while locating node 82 //自旋获取锁。若获取到锁,则跳出循环;否则一直循环直到获取到锁或retries大于MAX_SCAN_RETRIES。 83 while (!tryLock()) { 84 HashEntry<K,V> f; // to recheck first below 85 if (retries < 0) {//第一次循环retries < 0 86 if (e == null) { 87 //如果key不存在构造node,进入下一个循环 88 if (node == null) // speculatively create node 89 node = new HashEntry<K,V>(hash, key, value, null); 90 retries = 0; 91 } 92 else if (key.equals(e.key)) 93 //如果key存在直接进入下一个循环 94 retries = 0; 95 else 96 e = e.next; //遍历该Segment的HashEntry数组中hash对应的链表 97 } 98 else if (++retries > MAX_SCAN_RETRIES) { 99 //每次循环,retries加1,判断是否大于最大重试次数MAX_SCAN_RETRIES. 100 //static final int MAX_SCAN_RETRIES = Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1; 101 //为了防止自旋锁大量消耗CPU的缺点。如果超过MAX_SCAN_RETRIES,使用lock方法获取锁。如果获取不到锁则当前线程阻塞并跳出循环。 102 //ReentrantLock的lock()和tryLock()方法的区别。 103 lock(); 104 break; 105 } 106 else if ((retries & 1) == 0 && 107 (f = entryForHash(this, hash)) != first) { 108 //每隔一次循环,检查所在数组索引的链表有没有变化(其他线程有更新)。 109 //如果改变,retries更新为-1,重新遍历 110 e = first = f; // re-traverse if entry changed 111 retries = -1; 112 } 113 } 114 return node; 115 } 116 117 /**ConcurrentHashMap$Segment中方法**/ 118 //rehash 119 private void rehash(HashEntry<K,V> node) { 120 HashEntry<K,V>[] oldTable = table; 121 int oldCapacity = oldTable.length; 122 int newCapacity = oldCapacity << 1; //新容量为旧容量的2倍 123 threshold = (int)(newCapacity * loadFactor); //新阈值 124 HashEntry<K,V>[] newTable = 125 (HashEntry<K,V>[]) new HashEntry[newCapacity]; //新表 126 int sizeMask = newCapacity - 1; //新掩码 127 //对旧表做遍历 128 for (int i = 0; i < oldCapacity ; i++) { 129 HashEntry<K,V> e = oldTable[i]; 130 if (e != null) { 131 HashEntry<K,V> next = e.next; 132 int idx = e.hash & sizeMask; 133 if (next == null) // Single node on list 链表中只存在一个节点 134 newTable[idx] = e; 135 else { // Reuse consecutive sequence at same slot 136 //链表中存在多个节点. 137 /* 138 相对于HashMap的resize,ConcurrentHashMap的rehash原理类似,但是Doug Lea为rehash做了一定的优化,避免让所有的节点都进行复制操作:
由于扩容是基于2的幂指来操作,假设扩容前某HashEntry对应到Segment中数组的index为i,数组的容量为capacity,那么扩容后该HashEntry对应到新数组中的index只可能为i或者i+capacity,
因此大多数HashEntry节点在扩容前后index可以保持不变。基于此,rehash方法中会定位第一个后续所有节点在扩容后index都保持不变的节点,然后将这个节点之前的所有节点重排即可 139 */ 140 HashEntry<K,V> lastRun = e; 141 int lastIdx = idx; 142 //找到第一个在扩容后index都保持不变的节点lastRun 143 for (HashEntry<K,V> last = next; 144 last != null; 145 last = last.next) { 146 int k = last.hash & sizeMask; 147 if (k != lastIdx) { 148 lastIdx = k; 149 lastRun = last; 150 } 151 } 152 newTable[lastIdx] = lastRun; 153 // Clone remaining nodes 154 //将这个节点之前的所有节点重排 155 for (HashEntry<K,V> p = e; p != lastRun; p = p.next) { 156 V v = p.value; 157 int h = p.hash; 158 int k = h & sizeMask; 159 HashEntry<K,V> n = newTable[k]; 160 newTable[k] = new HashEntry<K,V>(h, p.key, v, n); 161 } 162 } 163 } 164 } 165 int nodeIndex = node.hash & sizeMask; // add the new node 166 node.setNext(newTable[nodeIndex]); 167 newTable[nodeIndex] = node; 168 table = newTable; 169 }
get操作不需要加锁,当拿到的值为空时才会加锁重读。不用加锁的原因是它的get方法里将要使用的共享变量都定义成volatile类型,如volatile V value。定义成volatile的变量,能够在线程之间保持可见性,能够被多线程同时读,并且保证不会读到过期的值,但是只能被单线程写(有一种情况可以被多线程写,就是写入的值不依赖于原值)。
1 public V get(Object key) { 2 Segment<K,V> s; // manually integrate access methods to reduce overhead 3 HashEntry<K,V>[] tab; 4 int h = hash(key); 5 long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE; 6 //通过Hash值找到相应的Segment 7 if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null && 8 (tab = s.table) != null) { 9 //找到HashEntry链表的索引,遍历链表找到对应的key 10 for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile 11 (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE); 12 e != null; e = e.next) { 13 K k; 14 if ((k = e.key) == key || (e.hash == h && key.equals(k))) 15 return e.value; 16 } 17 } 18 return null; 19 }
统计Map的大小需要统计所有Segment的大小然后求和。
问题:累加的过程中Segment的大小可能会发生变化,导致统计的结果不准确。
解决方案:1)简单的方法就是对所有的Segment加锁,但方法低效。
2)考虑到累加的过程中Segment的大小变化的可能性很小,作者给出了更高效的方案,首先尝试几次在不对Segment加锁的情况下统计各个Segment的大小,如果累加期间Map的大小发生了变化,再使用加锁的方式统计各个Segment的大小。判断Map的大小是否发生了变化,需要通过Segment的modCount变量实现。modCount表示对Segment的修改次数。相同的思想也用在了containsValue操作。
1 public int size() { 2 // Try a few times to get accurate count. On failure due to 3 // continuous async changes in table, resort to locking. 4 final Segment<K,V>[] segments = this.segments; 5 int size; 6 boolean overflow; // true if size overflows 32 bits 7 long sum; // sum of modCounts 8 long last = 0L; // previous sum 9 int retries = -1; // first iteration isn‘t retry 10 try { 11 for (;;) { 12 //static final int RETRIES_BEFORE_LOCK = 2; 13 //判断是否到达无锁统计map大小的最大次数,若达到最大次数需要锁所有Segment 14 if (retries++ == RETRIES_BEFORE_LOCK) { 15 for (int j = 0; j < segments.length; ++j) 16 ensureSegment(j).lock(); // force creation 17 } 18 sum = 0L; 19 size = 0; 20 overflow = false; 21 for (int j = 0; j < segments.length; ++j) { 22 Segment<K,V> seg = segmentAt(segments, j); 23 if (seg != null) { 24 sum += seg.modCount; 25 int c = seg.count; 26 if (c < 0 || (size += c) < 0) 27 overflow = true; 28 } 29 } 30 //判断前后两次统计的modCount之和是否相等,若相等则说明没有被修改郭 31 //由于last初始值为0,如果该Map从创建到现在都没有被修改过,即所有Segment的modCount都为0,则只执行一次循环;否则至少执行两次循环,比较两次统计的sum有没有发生变化。又因为retries初始值-1,所以可以说重试无锁统计大小的次数为3次。 32 if (sum == last) 33 break; 34 last = sum; 35 } 36 } finally { 37 //重试次数大于最大次数,需要释放锁 38 if (retries > RETRIES_BEFORE_LOCK) { 39 for (int j = 0; j < segments.length; ++j) 40 segmentAt(segments, j).unlock(); 41 } 42 } 43 return overflow ? Integer.MAX_VALUE : size; 44 }
《java并发编程的艺术》
(ConcurrentHashMap原理分析)https://my.oschina.net/hosee/blog/639352
(ConcurrentHashMap总结)http://www.importnew.com/22007.html
标签:nand net before 解决方案 xxx 更新 failure float dfa
原文地址:http://www.cnblogs.com/zaizhoumo/p/7709755.html