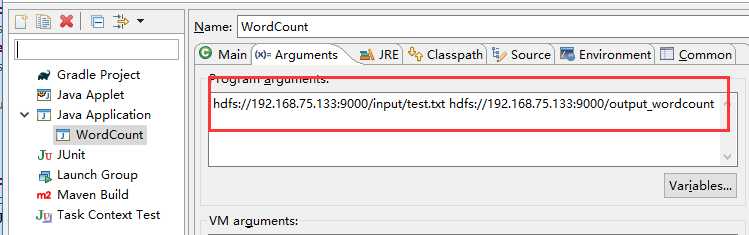
标签:3.2 throws package window 输出 hdf intern cli xxx

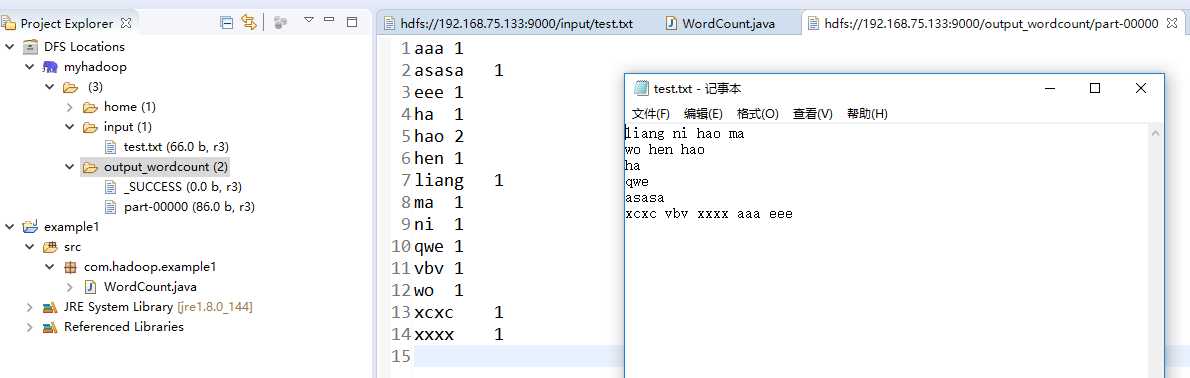
liang ni hao ma
wo hen hao
ha
qwe
asasa
xcxc vbv xxxx aaa eee
package com.hadoop.example1; import java.io.IOException; import java.util.Iterator; import java.util.StringTokenizer; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapred.FileInputFormat; import org.apache.hadoop.mapred.FileOutputFormat; import org.apache.hadoop.mapred.JobClient; import org.apache.hadoop.mapred.JobConf; import org.apache.hadoop.mapred.MapReduceBase; import org.apache.hadoop.mapred.Mapper; import org.apache.hadoop.mapred.OutputCollector; import org.apache.hadoop.mapred.Reducer; import org.apache.hadoop.mapred.Reporter; import org.apache.hadoop.mapred.TextInputFormat; import org.apache.hadoop.mapred.TextOutputFormat; public class WordCount { public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); output.collect(word, one); } } } public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum)); } } public static void main(String[] args) throws Exception { JobConf conf = new JobConf(WordCount.class); conf.setJobName("wordcount"); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(Map.class); conf.setCombinerClass(Reduce.class); conf.setReducerClass(Reduce.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf); } }
14/05/29 13:49:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 14/05/29 13:49:16 ERROR security.UserGroupInformation: PriviledgedActionException as:ISCAS cause:java.io.IOException: Failed to set permissions of path: \tmp\hadoop-ISCAS\mapred\staging\ISCAS1655603947\.staging to 0700 Exception in thread "main" java.io.IOException: Failed to set permissions of path: \tmp\hadoop-ISCAS\mapred\staging\ISCAS1655603947\.staging to 0700 at org.apache.hadoop.fs.FileUtil.checkReturnValue(FileUtil.java:691) at org.apache.hadoop.fs.FileUtil.setPermission(FileUtil.java:664) at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:514) at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:349) at org.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:193) at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:126) at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:942) at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:936) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Unknown Source) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1190) at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:936) at org.apache.hadoop.mapreduce.Job.submit(Job.java:550) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:580) at org.apache.hadoop.examples.WordCount.main(WordCount.java:82)
private static void checkReturnValue(boolean rv, File p, FsPermission permission) throws IOException { /** * comment the following, disable this function if (!rv) { throw new IOException("Failed to set permissions of path: " + p + " to " + String.format("%04o", permission.toShort())); } */ }
windows下eclipse远程连接hadoop集群开发mapreduce
标签:3.2 throws package window 输出 hdf intern cli xxx
原文地址:http://www.cnblogs.com/liangjf/p/7710789.html