标签:alt print port image pytho bug www. 原理 方向
今天早上,写的东西掉了。这个烂知乎,有bug,说了自动保存草稿,其实并没有保存。无语
今晚,我们将继续讨论如何分析html文档。
#直接找元素
soup.find_all(‘b‘)
#通过正则找
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
找a 和 b标签
soup.find_all(["a", "b"])
找所有标签
for tag in soup.find_all(True):
print(tag.name)
def has_class_but_no_id(tag):
return tag.has_attr(‘class‘) and not tag.has_attr(‘id‘)
#调用外部方法。只返回方法满足为true的元素
soup.find_all(has_class_but_no_id)
ind_all() 方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件.这里有几个例子:
soup.find_all("title")
#找class=title的p元素
soup.find_all("p", "title")
#找所有元素
soup.find_all("a")
#通过ID找
soup.find_all(id="link2")
#通过内容找
import re
soup.find(text=re.compile("sisters"))
#通过正则:查找元素属性满足条件的
soup.find_all(href=re.compile("elsie"))
#查找包含id的元素
soup.find_all(id=True)
#多条件查找
soup.find_all(href=re.compile("elsie"), id=‘link1‘)
有些tag属性在搜索不能使用,比如HTML5中的 data-* 属性
data_soup = BeautifulSoup(‘<div data-foo="value">foo!</div>‘)
data_soup.find_all(data-foo="value")
但是可以通过 find_all() 方法的 attrs 参数定义一个字典参数来搜索包含特殊属性的tag:
data_soup.find_all(attrs={"data-foo": "value"})
#按CSS搜索 注意class的用法
按照CSS类名搜索tag的功能非常实用,但标识CSS类名的关键字 class 在Python中是保留字,使用 class 做参数会导致语法错误.从Beautiful Soup的4.1.1版本开始,可以通过 class_ 参数搜索有指定CSS类名的tag
soup.find_all("a", class_="sister")
class_ 参数同样接受不同类型的 过滤器 ,字符串,正则表达式,方法或 True :
soup.find_all(class_=re.compile("itl"))
def has_six_characters(css_class):
return css_class is not None and len(css_class) == 6
soup.find_all(class_=has_six_characters)
tag的 class 属性是 多值属性 .按照CSS类名搜索tag时,可以分别搜索tag中的每个CSS类名:
css_soup = BeautifulSoup(‘<p class="body strikeout"></p>‘)
css_soup.find_all("p", class_="strikeout")
css_soup.find_all("p", class_="body")
搜索 class 属性时也可以通过CSS值完全匹配
css_soup.find_all("p", class_="body strikeout")
完全匹配 class 的值时,如果CSS类名的顺序与实际不符,将搜索不到结果
soup.find_all("a", attrs={"class": "sister"})
通过 text 参数可以搜搜文档中的字符串内容.
与 name 参数的可选值一样, text 参数接受 字符串 , 正则表达式 , 列表, True .
soup.find_all(text="Elsie")
soup.find_all(text=["Tillie", "Elsie", "Lacie"])
soup.find_all(text=re.compile("Dormouse"))
def is_the_only_string_within_a_tag(s):
return (s == s.parent.string)
soup.find_all(text=is_the_only_string_within_a_tag)
虽然 text 参数用于搜索字符串,还可以与其它参数混合使用来过滤tag.Beautiful Soup会找到 .string 方法与 text 参数值相符的tag.下面代码用来搜索内容里面包含“Elsie”的<a>标签
soup.find_all("a", text="Elsie")
find_all() 方法返回全部的搜索结构,如果文档树很大那么搜索会很慢.如果我们不需要全部结果,可以使用 limit 参数限制返回结果的数量.效果与SQL中的limit关键字类似,当搜索到的结果数量达到 limit 的限制时,就停止搜索返回结果
soup.find_all("a", limit=2)
调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点,如果只想搜索tag的直接子节点,可以使用参数 recursive=False .
soup.html.find_all("title")
soup.html.find_all("title", recursive=False)
find_all() 几乎是Beautiful Soup中最常用的搜索方法,所以我们定义了它的简写方法. BeautifulSoup 对象和 tag 对象可以被当作一个方法来使用,这个方法的执行结果与调用这个对象的 find_all() 方法相同,下面两行代码是等价的
soup.find_all("a")
soup("a")
soup.title.find_all(text=True)
soup.title(text=True)
soup.find_all(‘title‘, limit=1)与soup.find(‘title‘)一样
find就是找到满足条件的第一个就返回。all返回列表,find返回一个对象
find_all() 方法没有找到目标是返回空列表, find() 方法找不到目标时,返回 None
soup.head.title 是 tag的名字 方法的简写.这个简写的原理就是多次调用当前tag的 find() 方法
soup.head.title与soup.find("head").find("title")
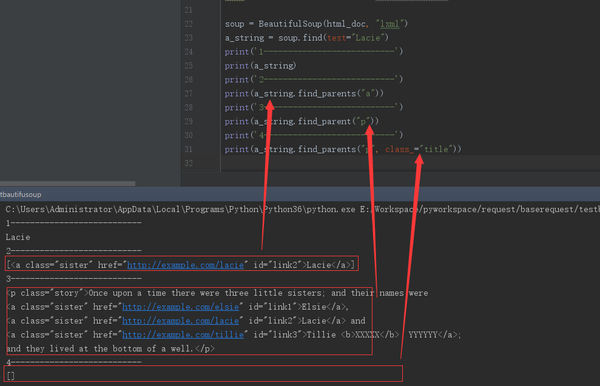
soup = BeautifulSoup(html_doc, "lxml")
a_string = soup.find(text="Lacie")
print(‘1---------------------------‘)
print(a_string)
print(‘2---------------------------‘)
#找直接父节点
print(a_string.find_parents("a"))
print(‘3---------------------------‘)
#迭代找父节点
print(a_string.find_parent("p"))
print(‘4---------------------------‘)
#找直接父节点
print(a_string.find_parents("p", class_="title"))
soup = BeautifulSoup(html_doc, "lxml")
a_string = soup.find(text="Lacie")
print(‘1---------------------------‘)
first_link = soup.a
print(first_link)
print(‘2---------------------------‘)
#找当前元素的所有后续元素
print(first_link.find_next_siblings("a"))
print(‘3---------------------------‘)
first_story_paragraph = soup.find("p", "story")
#找当前元素的紧接着的第一个元素
print(first_story_paragraph.find_next_sibling("p"))

和第9点方向相反
last_link = soup.find("a", id="link3")
last_link
last_link.find_previous_siblings("a")
first_story_paragraph = soup.find("p", "story")
first_story_paragraph.find_previous_sibling("p")
这2个方法通过 .next_elements 属性对当前tag的之后的tag和字符串进行迭代, find_all_next() 方法返回所有符合条件的节点, find_next() 方法返回第一个符合条件的节点:
first_link.find_all_next(text=True)
first_link.find_next("p")
这2个方法通过 .previous_elements 属性对当前节点前面 的tag和字符串进行迭代, find_all_previous() 方法返回所有符合条件的节点, find_previous() 方法返回第一个符合条件的节点
first_link.find_all_previous("p")
first_link.find_previous("title")
查找class=title的元素
soup.select("title")
soup.select("p nth-of-type(3)")
通过元素层级查找
soup.select("body a")
soup.select("html head title")
找直接子元素
soup.select("head > title")
soup.select("p > a")
soup.select("p > a:nth-of-type(2)")
oup.select("p > #link1")
up.select("body > a")
找到兄弟节点标签
soup.select("#link1 ~ .sister")
soup.select("#link1 + .sister")
通过CSS的类名查找
soup.select(".sister")
这里的class没有加 _
soup.select("[class~=sister]")
通过tag的id查找
soup.select("#link1")
通过是否存在某个属性来查找
oup.select(‘a[href]‘)
通过属性的值来查找
soup.select(‘a[href="http://example.com/elsie"]‘)
#以title结尾
soup.select(‘a[href$="tillie"]‘)
#包含.com
soup.select(‘a[href*=".com/el"]‘)
通过语言设置来查找:就是通过元素属性来查找
multilingual_markup = """
<p lang="en">Hello</p>
<p lang="en-us">Howdy, y‘all</p>
<p lang="en-gb">Pip-pip, old fruit</p>
<p lang="fr">Bonjour mes amis</p>
"""
multilingual_soup = BeautifulSoup(multilingual_markup)
multilingual_soup.select(‘p[lang|=en]‘)
这一部分内容,了解jquery的人一眼就看明白了
作为程序员,一定要学会触类旁通
标签:alt print port image pytho bug www. 原理 方向
原文地址:http://www.cnblogs.com/zijiyanxi/p/7726212.html