标签:需要 tween 扫描 swa rar 数据文件 组合 索引 长度
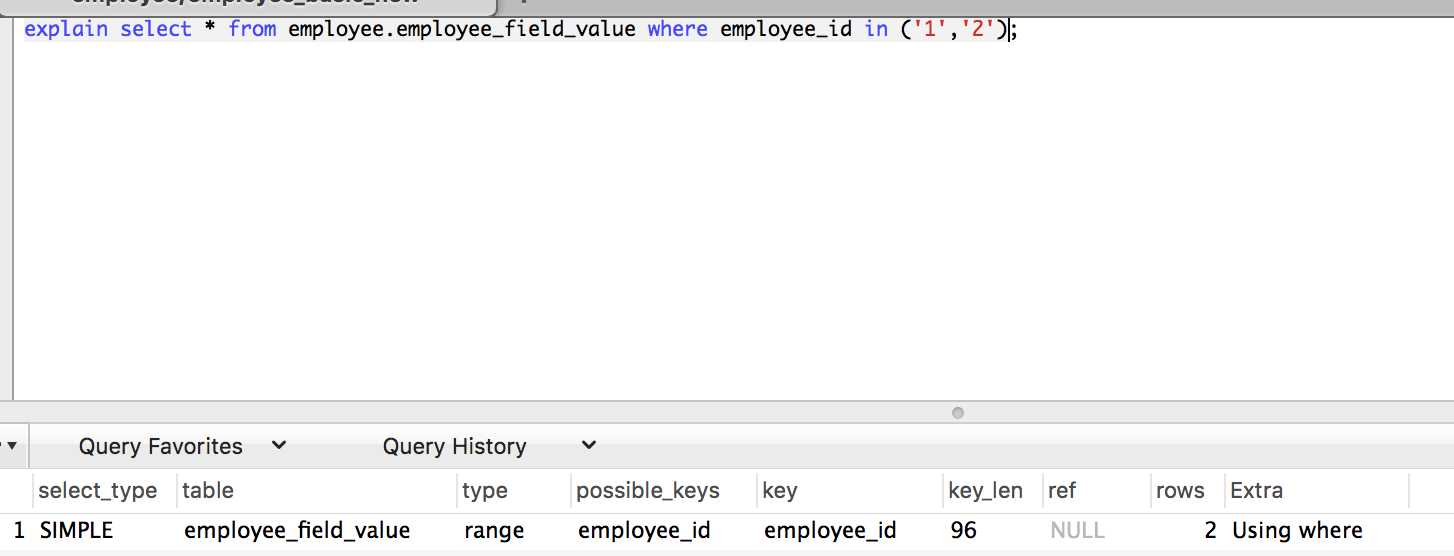
explain {sql}; // 分析查询语句
(1) id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行
(2) select_type查询类型:simple、primary、dependent subquery等
(3) table表名
(4) type
从上到下性能依次下降:
system:表中只有一行数据或者是空表,且只能用于myisam和memory表
const:使用唯一索引或者主键,返回记录一定是1行记录的等值where条件时,通常type是const
eq_ref:对于每个来自于前面的表的行组合,从该表中读取一行,这可能是最好的联接类型
ref:对于每个来自于前面的表的行组合,从该表中读取多行,如果使用的键仅仅匹配少量行,该联接类型是不错的
range:索引范围扫描,常见于使用>, <, between ,in ,like等运算符的查询中
all:全表扫描数据文件,然后再在server层进行过滤返回符合要求的记录
(5) possible_keys:可能用到的索引
(6) key:实际用到的索引
(7) key_len
用于处理查询的索引长度,如果是单列索引,那就整个索引长度算进去,如果是多列索引,那么查询不一定都能使用到所有的列,具体使用到了多少个列的索引,这里就会计算进去,没有使用到的列,这里不会计算进去。key_len只计算where条件用到的索引长度,而排序和分组就算用到了索引,也不会计算到key_len中。
(8) ref:如果是使用的常数等值查询,这里会显示const;如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段
(9) rows:预估的扫描行数
(10) Extra
using index:出现这个说明mysql使用了覆盖索引,避免访问了表的数据行,效率不错!
using where:说明服务器在存储引擎收到行后将进行过滤。有些where中的条件会有属于索引的列,当它读取使用索引的时候,就会被过滤,所以会出现有些where语句并没有在extra列中出现using where这么一个说明
using index condition:mysql5.6以后的新特性,会先条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行
using temporary:using temporary:这意味着mysql对查询结果进行排序的时候使用了一张临时表
using filesort:排序时无法使用索引,需要用到内存或磁盘进行排序
MySQL 的 Query Profiler 是一个使用非常方便的 Query 诊断分析工具,通过该工具可以获取一条Query 在整个执行过程中多种资源的消耗情况,如 CPU,IO,IPC,SWAP 等,以及发生的 PAGE FAULTS,CONTEXT SWITCHE 等等,同时还能得到该 Query 执行过程中 MySQL 所调用的各个函数在源文件中的位置。
操作如下:
set profiling=1; // 打开profiling分析
select @@profiling; // 确认profiling分析打开
{sql}; // 执行查询语句
show profiles; // 查询刚刚被执行的语句的Query_ID
show profile for query {Query_ID}; // 分析sql
set profiling=0; // 关闭profiling分析(关闭会话会自动关闭)
标签:需要 tween 扫描 swa rar 数据文件 组合 索引 长度
原文地址:http://www.cnblogs.com/leemumu/p/7740190.html