标签:朋友 rip 网络请求 是什么 ring 根据 工具 dict 符号
一年一度的虐狗节将至,朋友圈各种晒,晒自拍,晒娃,晒美食,秀恩爱的。程序员在晒什么,程序员在加班。但是礼物还是少不了的,送什么好?作为程序员,我准备了一份特别的礼物,用以往发的微博数据打造一颗“爱心”,我想她一定会感动得哭了吧。哈哈
有了想法之后就开始行动了,自然最先想到的就是用 Python 了,大体思路就是把微博数据爬下来,数据经过清洗加工后再进行分词处理,处理后的数据交给词云工具,配合科学计算工具和绘图工具制作成图像出来,涉及到的工具包有:
requests 用于网络请求爬取微博数据,结巴分词进行中文分词处理,词云处理库 wordcloud,图片处理库 Pillow,科学计算工具 NumPy ,类似于 MATLAB 的 2D 绘图库 Matplotlib
安装这些工具包时,不同系统平台有可能出现不一样的错误,wordcloud,requests,jieba 都可以通过普通的 pip 方式在线安装,
pip install wordcloud
pip install requests
pip install jieba
在Windows 平台安装 Pillow,NumPy,Matplotlib 直接用 pip 在线安装会出现各种问题,推荐的一种方式是在一个叫 Python Extension Packages for Windows 1 的第三方平台下载 相应的 .whl 文件安装。可以根据自己的系统环境选择下载安装 cp27 对应 python2.7,amd64 对应 64 位系统。下载到本地后进行安装
pip install Pillow-4.0.0-cp27-cp27m-win_amd64.whl
pip install scipy-0.18.0-cp27-cp27m-win_amd64.whl
pip install numpy-1.11.3+mkl-cp27-cp27m-win_amd64.whl
pip install matplotlib-1.5.3-cp27-cp27m-win_amd64.whl
其他平台可根据错误提示 Google 解决。或者直接基于 Anaconda 开发,它是 Python 的一个分支,内置了大量科学计算、机器学习的模块 。
新浪微博官方提供的 API 是个渣渣,只能获取用户最新发布的5条数据,退而求其次,使用爬虫去抓取数据,抓取前先评估难度,看看是否有人写好了,在GitHub逛了一圈,基本没有满足需求的。倒是给我提供了一些思路,于是决定自己写爬虫。使用 http://m.weibo.cn/ 移动端网址去爬取数据。发现接口 http://m.weibo.cn/index/my?format=cards&page=1 可以分页获取微博数据,而且返回的数据是 json 格式,这样就省事很多了,不过该接口需要登录后的 cookies 信息,登录自己的帐号就可以通过 Chrome 浏览器 找到 Cookies 信息。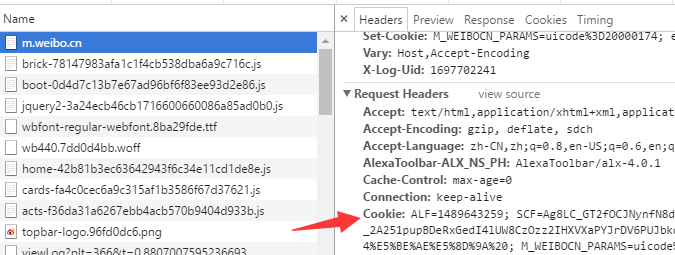
实现代码:
def fetch_weibo():
api = "http://m.weibo.cn/index/my?format=cards&page=%s"
for i in range(1, 102):
response = requests.get(url=api % i, cookies=cookies)
data = response.json()[0]
groups = data.get("card_group") or []
for group in groups:
text = group.get("mblog").get("text")
text = text.encode("utf-8")
text = cleanring(text).strip()
yield text
查看微博的总页数是101,考虑到一次性返回一个列表对象太费内存,函数用 yield 返回一个生成器,此外还要对文本进行数据清洗,例如去除标点符号,HTML 标签,“转发微博”这样的字样。
数据获取之后,我们要把它离线保存起来,方便下次重复使用,避免重复地去爬取。使用 csv 格式保存到 weibo.csv 文件中,以便下一步使用。数据保存到 csv 文件中打开的时候可能为乱码,没关系,用 notepad++查看不是乱码。
def write_csv(texts):
with codecs.open(‘weibo.csv‘, ‘w‘) as f:
writer = csv.DictWriter(f, fieldnames=["text"])
writer.writeheader()
for text in texts:
writer.writerow({"text": text})
def read_csv():
with codecs.open(‘weibo.csv‘, ‘r‘) as f:
reader = csv.DictReader(f)
for row in reader:
yield row[‘text‘]
从 weibo.csv 文件中读出来的每一条微博进行分词处理后再交给 wordcloud 生成词云。结巴分词适用于大部分中文使用场景,使用停止词库 stopwords.txt 把无用的信息(比如:的,那么,因为等)过滤掉。
def word_segment(texts):
jieba.analyse.set_stop_words("stopwords.txt")
for text in texts:
tags = jieba.analyse.extract_tags(text, topK=20)
yield " ".join(tags)
数据分词处理后,就可以给 wordcloud 处理了,wordcloud 根据数据里面的各个词出现的频率、权重按比列显示关键字的字体大小。生成方形的图像,如图:

是的,生成的图片毫无美感,毕竟是要送人的也要拿得出手才好炫耀对吧,那么我们找一张富有艺术感的图片作为模版,临摹出一张漂亮的图出来。我在网上搜到一张“心”型图:
生成图片代码:
def generate_img(texts):
data = " ".join(text for text in texts)
mask_img = imread(‘./heart-mask.jpg‘, flatten=True)
wordcloud = WordCloud(
font_path=‘msyh.ttc‘,
background_color=‘white‘,
mask=mask_img
).generate(data)
plt.imshow(wordcloud)
plt.axis(‘off‘)
plt.savefig(‘./heart.jpg‘, dpi=600)
需要注意的是处理时,需要给 matplotlib 指定中文字体,否则会显示乱码,找到字体文件夹:C:\Windows\Fonts\Microsoft YaHei UI复制该字体,拷贝到 matplotlib 安装目录:C:\Python27\Lib\site-packages\matplotlib\mpl-data\fonts\ttf 下
差不多就这样。

当我自豪地把这张图发给她的时候,出现了这样的对话:
这是什么?
我:爱心啊,亲手做的
这么专业,好感动啊,你的眼里只有 python ,没有我 (哭笑)
我:明明是“心”中有 python 啊
标签:朋友 rip 网络请求 是什么 ring 根据 工具 dict 符号
原文地址:http://www.cnblogs.com/yangshunde/p/7742883.html