标签:pre 查看 程序 实现类 splay width eve record textinput
前言
前面一篇博文写的是Combiner优化MapReduce执行,也就是使用Combiner在map端执行减少reduce端的计算量。
MapReduce程序的默认配置
1)概述
在我们的MapReduce程序中有一些默认的配置。所以说当我们程序如果要使用这些默认配置时,可以不用写。

我们的一个MapReduce程序一定会有Mapper和Reducer,但是我们程序中不写的话,它也有默认的Mapper和Reducer。
当我们使用默认的Mapper和Reducer的时候,map和reducer的输入和输出都是偏移量和数据文件的一行数据,所以就是相当于原样输出!
2)默认的MapReduce程序
/** * 没有指定Mapper和Reducer的最小作业配置 */ public class MinimalMapReduce { public static void main(String[] args) throws Exception{ // 构建新的作业 Configuration conf=new Configuration(); Job job = Job.getInstance(conf, "MinimalMapReduce"); job.setJarByClass(MinimalMapReduce.class); // 设置输入输出路径 FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // ?交作业运行 System.exit(job.waitForCompletion(true)?0:1); } }
输入是:

输出是:
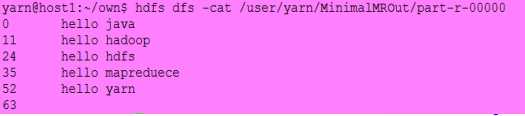
MapReduce的类型配置
1)用于配置类型的属性


在命令行中,怎么去配置呢?
比如说mapreduce.job.inputformat.class。首先我们要继承Configured实现Tool工具才能这样去指定:
-Dmapreduce.job.inputformat.class = 某一个类的类全名(一定要记得加报名)
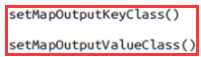 这是Map端的输出类型控制
这是Map端的输出类型控制
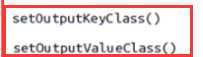 这是整个MapReduce程序输出类型控制,其实就是reduce的类型格式控制
这是整个MapReduce程序输出类型控制,其实就是reduce的类型格式控制
2)No Reducer的MapReduce程序--Mapper
第一步:写一个TokenCounterMapper继承Mapper

/** * 将输入的文本内容拆分为word,做一个简单输出的Mapper */ public class TokenCounterMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ private Text word=new Text(); private static final IntWritable one=new IntWritable(1); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { // TODO Auto-generated method stub StringTokenizer itr=new StringTokenizer(value.toString()); while(itr.hasMoreTokens()){ word.set(itr.nextToken()); context.write(word, one); } } }
第二步:写一个NoReducerMRDriver完成作业配置
/** *没有设置Reducer的MR程序 */ public class NoReducerMRDriver { public static void main(String[] args) throws Exception { // 构建新的作业 Configuration conf=new Configuration(); Job job = Job.getInstance(conf, "NoReducer"); job.setJarByClass(NoReducerMRDriver.class); // 设置Mapper job.setMapperClass(TokenCounterMapper.class); // 设置reducer的数量为0 job.setNumReduceTasks(0); // 设置输出格式 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 设置输入输出路径 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // ?交运行作业 System.exit(job.waitForCompletion(true)?0:1); } }
输入:
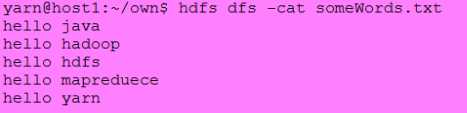
结果:
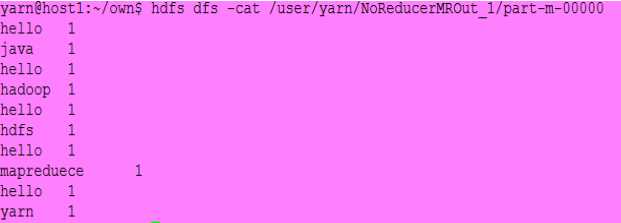
注意:如果作业拥有0个Reducer,则Mapper结果直接写入OutputFormat而不经key值排序。
3)No Mapper的MapReduce程序--Reducer
第一步:写一个TokenCounterReducer继承Reducer
/** * 将reduce输入的values内容拆分为word,做一个简单输出的Reducer */ public class TokenCounterReducer extends Reducer<LongWritable, Text, Text, IntWritable>{ private Text word=new Text(); private static final IntWritable one=new IntWritable(1); @Override protected void reduce(LongWritable key, Iterable<Text> values,Reducer<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { // TODO Auto-generated method stub for(Text value:values){ StringTokenizer itr=new StringTokenizer(value.toString()); while(itr.hasMoreTokens()){ word.set(itr.nextToken()); context.write(word, one); } } } }
第二步:写一个NoMapperMRDrive完成作业配置
/** *没有设置Mapper的MR程序 */ public class NoMapperMRDriver { public static void main(String[] args) throws Exception { // 构建新的作业 Configuration conf=new Configuration(); Job job = Job.getInstance(conf, "NoMapper"); job.setJarByClass(NoMapperMRDriver.class); // 设置Reducer job.setReducerClass(TokenCounterReducer.class); // 设置输出格式 job.setMapOutputKeyClass(LongWritable.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 设置输入输出路径 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // ?交运行作业 System.exit(job.waitForCompletion(true)?0:1); } }
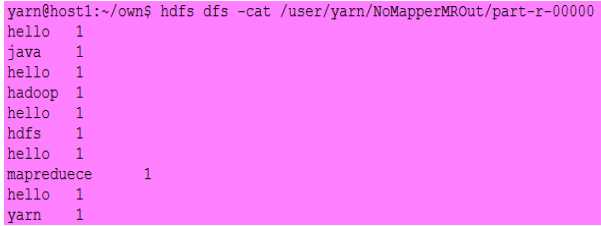
输入:

输出:
Mapper:封装了应用程序Mapper阶段的数据处理逻辑
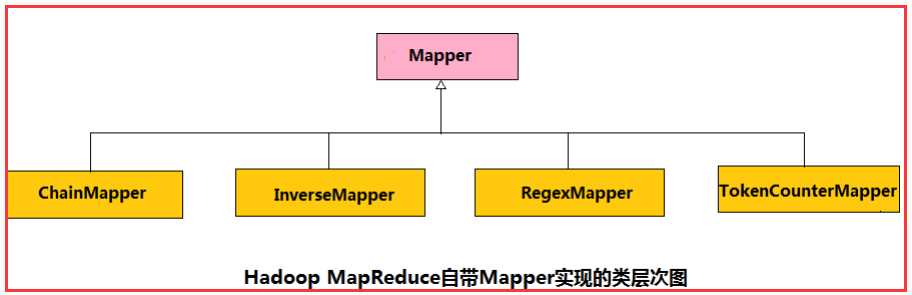
1)ChainMapper
方便用户编写链式Map任务, 即Map阶段包含多个Mapper,即可以别写多个自定义map去参与运算。
2)InverseMapper
一个能交换key和value的Mapper
3)RegexMapper
检查输入是否匹配某正则表达式, 输出匹配字符串和计数器(用的很少)
4)TockenCounterMapper
将输入分解为独立的单词, 输出个单词和计数器(以空格分割单词,value值为1)
Mapper:封装了应用程序Mapper阶段的数据处理逻辑
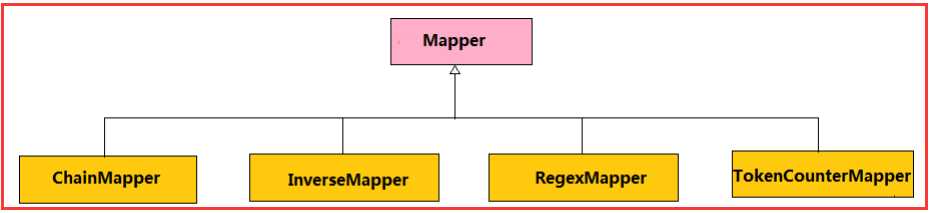
1)ChainMapper:
方便用户编写链式Map任务, 即Map阶段只能有一个Reducer,后面还可以用ChainMapper去多加Mapper。
2)IntSumReducer/LongSumReducer
对各key的所有整型值求和
注意:这里用到了一个输入格式为KeyValueTextInputFormat,我们查看源码注释:

我们需要用mapreduce.input.keyvaluelinerecordreader.key.value.separator去指定key和value的分隔符是什么,它的默认分隔符是"\t"也就是tab键。
这个需要在配置文件中去指定,但是我们知道在配置文件中能设置的在程序中也是可以设置的。
conf.set("mapreduce.input.keyvaluelinerecordreader.key.value.separator",",");
代码实现:
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.chain.ChainMapper; import org.apache.hadoop.mapreduce.lib.chain.ChainReducer; import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat; import org.apache.hadoop.mapreduce.lib.map.InverseMapper; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.mapreduce.lib.reduce.IntSumReducer; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class PatentReference_0010 extends Configured implements Tool{ static class PatentReferenceMapper extends Mapper<Text,Text,Text,IntWritable>{ private IntWritable one=new IntWritable(1); @Override protected void map(Text key,Text value,Context context) throws IOException, InterruptedException{ context.write(key,one); } } @Override public int run(String[] args) throws Exception{ Configuration conf=getConf(); Path input=new Path(conf.get("input")); Path output=new Path(conf.get("output")); conf.set("mapreduce.input.keyvaluelinerecordreader.key.value.separator",","); Job job=Job.getInstance(conf,this.getClass().getSimpleName()); job.setJarByClass(this.getClass()); ChainMapper.addMapper(job,InverseMapper.class, // 输入的键值类型由InputFormat决定 Text.class,Text.class, // 输出的键值类型与输入的键值类型相反 Text.class,Text.class,conf); ChainMapper.addMapper(job,PatentReferenceMapper.class, // 输入的键值类型由前一个Mapper输出的键值类型决定 Text.class,Text.class, Text.class,IntWritable.class,conf); ChainReducer.setReducer(job,IntSumReducer.class, Text.class,IntWritable.class, Text.class,IntWritable.class,conf); ChainReducer.addMapper(job,InverseMapper.class, Text.class,IntWritable.class, IntWritable.class,Text.class,conf); job.setInputFormatClass(KeyValueTextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); KeyValueTextInputFormat.addInputPath(job,input); TextOutputFormat.setOutputPath(job,output); return job.waitForCompletion(true)?0:1; } public static void main(String[] args) throws Exception{ System.exit(ToolRunner.run(new P00010_PatentReference_0010(),args)); } }
在Job job=Job.getInstance(conf,this.getClass().getSimpleName());设置中,job把conf也就是配置文件做了一个拷贝,因为hadoop要重复利用一个对象,如果是引用的话,发现值得改变就都改变了。
喜欢就点个“推荐”哦!
Hadoop(十七)之MapReduce作业配置与Mapper和Reducer类
标签:pre 查看 程序 实现类 splay width eve record textinput
原文地址:http://www.cnblogs.com/zhangyinhua/p/7740888.html
