标签:效果 pack font 准则 需要 poster 简化 信息 应该
判别分析(discriminant analysis)是一种分类技术。它通过一个已知类别的“训练样本”来建立判别准则,并通过预测变量来为未知类别的数据进行分类。判别分析的方法大体上有三类,即Fisher判别、Bayes判别和距离判别。
线性判别式分析(Linear Discriminant Analysis,简称为LDA)是模式识别的经典算法,在1996年由Belhumeur引入模式识别和人工智能领域。LDA的基本思想是将高维的模式样本投影到最佳鉴别矢量空间,以达到抽取分类信息和压缩特征空间维数的效果,投影后保证模式样本在新的子空间有最大的类间距离和最小的类内距离,即模式在该空间中有最佳的可分离性。
特征选择(亦即降维)是数据预处理中非常重要的一个步骤。对于分类来说,特征选择可以从众多的特征中选择对分类最重要的那些特征,去除原数据中的噪音。主成分分析(PCA)与线性判别式分析(LDA)是两种最常用的特征选择算法。但是他们的目标基本上是相反的,如下列示LDA与PCA之间的区别。
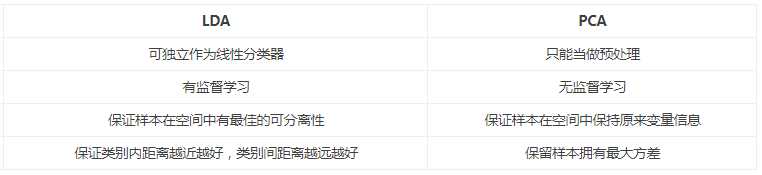
同一样例两种降维方法很直观的不同对比结果:
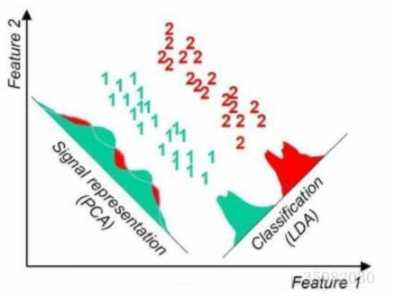
线性判别分析LDA算法由于其简单有效性在多个领域都得到了广泛地应用,是目前机器学习、数据挖掘领域经典且热门的一个算法;但是算法本身仍然存在一些局限性:
LDA的应用应用场景:
MASS::lda
R中使用MASS包的lda函数实现线性判别。lda函数以Bayes判别思想为基础。当分类只有两种且总体服从多元正态分布条件下,Bayes判别与Fisher判别、距离判别是等价的。代码示例:
> if (require(MASS) == FALSE) + { + install.packages("MASS") + } > > model1=lda(Species~.,data=iris) > table <- table(iris$Species,predict(model1)$class) > table setosa versicolor virginica setosa 50 0 0 versicolor 0 48 2 virginica 0 1 49 > sum(diag(prop.table(table)))###判对率 [1] 0.98
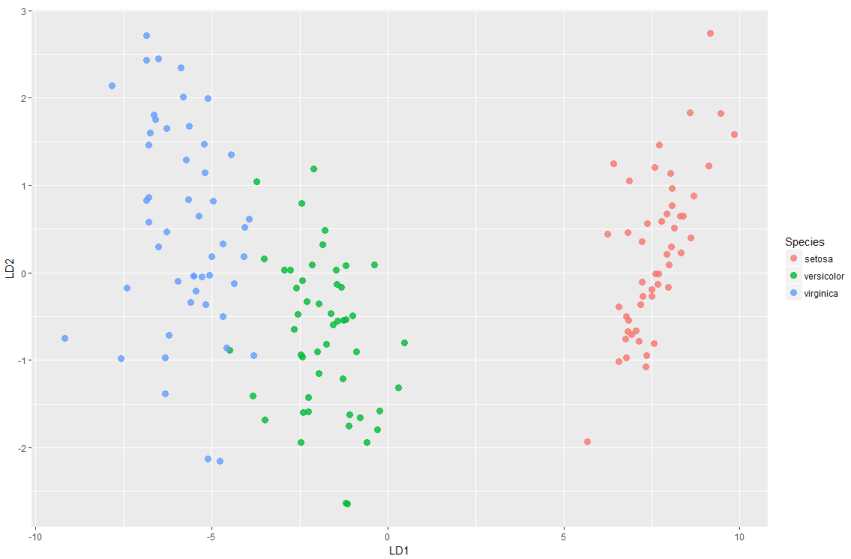
结果可观察到判断错误的样本只有三个。在判别函数建立后,还可以类似主成分分析那样对判别得分进行绘图
> ld <- predict(model1)$x #表示映射到模型中的向量上的值;即score值 > ds <- cbind(iris,as.data.frame(ld)) > head(ds) Sepal.Length Sepal.Width Petal.Length Petal.Width Species LD1 LD2 1 5.1 3.5 1.4 0.2 setosa 8.061800 0.3004206 2 4.9 3.0 1.4 0.2 setosa 7.128688 -0.7866604 3 4.7 3.2 1.3 0.2 setosa 7.489828 -0.2653845 4 4.6 3.1 1.5 0.2 setosa 6.813201 -0.6706311 5 5.0 3.6 1.4 0.2 setosa 8.132309 0.5144625 6 5.4 3.9 1.7 0.4 setosa 7.701947 1.4617210 > p=ggplot(ds,mapping = aes(x=LD1,y=LD2)) > p+geom_point(aes(colour=Species),alpha=0.8,size=3)
再看一组基于主成份预测数据
> model2 <- lda(Species~LD1+LD2,ds) > table(iris$Species,predict(model2)$class) setosa versicolor virginica setosa 50 0 0 versicolor 0 48 2 virginica 0 1 49
当不同类样本的协方差矩阵不同时,则应该使用二次判别。在使用lda和qda函数时注意:其假设是总体服从多元正态分布,若不满足的话则谨慎使用二次判别。
> iris.qda=qda(Species~.,data=iris,cv=T) > table<-table(iris$Species,predict(iris.qda,iris)$class) > table setosa versicolor virginica setosa 50 0 0 versicolor 0 48 2 virginica 0 1 49 > sum(diag(prop.table(table)))###判对率 [1] 0.98
CV参数设置为T,是使用留一交叉检验(leave-one-out cross-validation),并自动生成预测值。这种条件下生成的混淆矩阵较为可靠。此外还可以使用predict(model)$posterior提取后验概率
标签:效果 pack font 准则 需要 poster 简化 信息 应该
原文地址:http://www.cnblogs.com/tgzhu/p/7383872.html