标签:beautiful desc use 修改 log data article let imp
from bs4 import BeautifulSoup with open(‘C:/Users/michael/Desktop/Plan-for-combating-master/week1/1_2/1_2code_of_video/web/new_index.html‘,‘r‘) as web_data: Soup = BeautifulSoup(web_data,‘lxml‘) print(Soup)

浏览器右键-》审查元素-》copy-》seletor
""" body > div.main-content > ul > li:nth-child(1) > div.article-info > h3 > a body > div.main-content > ul > li:nth-child(1) > div.article-info > p.meta-info > span:nth-child(2) body > div.main-content > ul > li:nth-child(1) > div.article-info > p.description body > div.main-content > ul > li:nth-child(1) > div.rate > span body > div.main-content > ul > li:nth-child(1) > img """
images = Soup.select(‘body > div.main-content > ul > li:nth-child(1) > img‘) print(images)

修改成:
images = Soup.select(‘body > div.main-content > ul > li:nth-of-type(1) > img‘) print(images)

这时候能获取到一个
images = Soup.select(‘body > div.main-content > ul > li > img‘) print(images)

获取到了所有图片
titles = Soup.select(‘body > div.main-content > ul > li > div.article-info > h3 > a‘) descs = Soup.select(‘body > div.main-content > ul > li > div.article-info > p.description‘) rates = Soup.select(‘ body > div.main-content > ul > li > div.rate > span‘) cates = Soup.select(‘ body > div.main-content > ul > li > div.article-info > p.meta-info > span‘) print(images,titles,descs,rates,cates,sep=‘\n-----------\n‘)

获取到了其他信息
for title in titles: print(title.get_text())
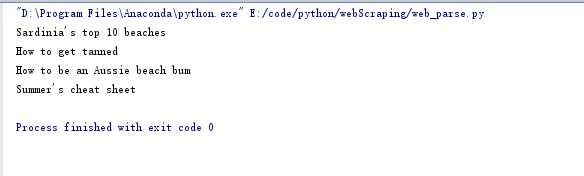
封装成字典:
for title,image,desc,rate,cate in zip(titles,images,descs,rates,cates): data = { ‘title‘:title.get_text(), ‘rate‘:rate.get_text(), ‘desc‘:desc.get_text(), ‘cate‘:cate.get_text(), ‘image‘:image.get(‘src‘) } print(data)

因为cates有多个属性,需要上升到父节点
cates = Soup.select(‘ body > div.main-content > ul > li > div.article-info > p.meta-info‘)
for title,image,desc,rate,cate in zip(titles,images,descs,rates,cates): data = { ‘title‘:title.get_text(), ‘rate‘:rate.get_text(), ‘desc‘:desc.get_text(), ‘cate‘:list(cate.stripped_strings), ‘image‘:image.get(‘src‘) } print(data)

#找到评分大于3的文章 for i in info: if float(i[‘rate‘])>3: print(i[‘title‘],i[‘cate‘])
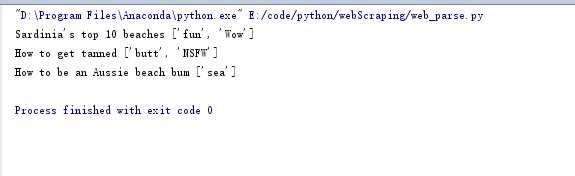
from bs4 import BeautifulSoup info =[] with open(‘C:/Users/michael/Desktop/Plan-for-combating-master/week1/1_2/1_2code_of_video/web/new_index.html‘,‘r‘) as web_data: Soup = BeautifulSoup(web_data,‘lxml‘) # print(Soup) """ body > div.main-content > ul > li:nth-child(1) > div.article-info > h3 > a body > div.main-content > ul > li:nth-child(1) > div.article-info > p.meta-info > span:nth-child(2) body > div.main-content > ul > li:nth-child(1) > div.article-info > p.description body > div.main-content > ul > li:nth-child(1) > div.rate > span body > div.main-content > ul > li:nth-child(1) > img """ images = Soup.select(‘body > div.main-content > ul > li > img‘) titles = Soup.select(‘body > div.main-content > ul > li > div.article-info > h3 > a‘) descs = Soup.select(‘body > div.main-content > ul > li > div.article-info > p.description‘) rates = Soup.select(‘ body > div.main-content > ul > li > div.rate > span‘) cates = Soup.select(‘ body > div.main-content > ul > li > div.article-info > p.meta-info‘) # print(images,titles,descs,rates,cates,sep=‘\n-----------\n‘) for title,image,desc,rate,cate in zip(titles,images,descs,rates,cates): data = { ‘title‘:title.get_text(), ‘rate‘:rate.get_text(), ‘desc‘:desc.get_text(), ‘cate‘:list(cate.stripped_strings), ‘image‘:image.get(‘src‘) } #添加到列表中 info.append(data) #找到评分大于3的文章 for i in info: if float(i[‘rate‘])>3: print(i[‘title‘],i[‘cate‘])
标签:beautiful desc use 修改 log data article let imp
原文地址:http://www.cnblogs.com/Michael2397/p/7747231.html