标签:keep name otp 限制 好的 支持 主机 union 解析
组建MySQL集群的几种方案
LVS+Keepalived+MySQL(有脑裂问题?但似乎很多人推荐这个)
DRBD+Heartbeat+MySQL(有一台机器空余?Heartbeat切换时间较长?有脑裂问题?)
MySQL Proxy(不够成熟与稳定?使用了Lua?是不是用了他做分表则可以不用更改客户端逻辑?)
MySQL Cluster (社区版不支持INNODB引擎?商用案例不足?)
MySQL + MHA (如果配上异步复制,似乎是不错的选择,又和问题?)
MySQL + MMM (似乎反映有很多问题,未实践过,谁能给个说法)
回答:
不管哪种方案都是有其场景限制 或说 规模限制,以及优缺点的。
1. 首先反对大家做读写分离,关于这方面的原因解释太多次数(增加技术复杂度、可能导致读到落后的数据等),只说一点:99.8%的业务场景没有必要做读写分离,只要做好数据库设计优化 和配置合适正确的主机即可。
2.Keepalived+MySQL --确实有脑裂的问题,还无法做到准确判断mysqld是否HANG的情况;
3.DRBD+Heartbeat+MySQL --同样有脑裂的问题,还无法做到准确判断mysqld是否HANG的情况,且DRDB是不需要的,增加反而会出问题;
3.MySQL Proxy -- 不错的项目,可惜官方半途夭折了,不建议用,无法高可用,是一个写分离;
4.MySQL Cluster -- 社区版本不支持NDB是错误的言论,商用案例确实不多,主要是跟其业务场景要求有关系、这几年发展有点乱不过现在已经上正规了、对网络要求高;
5.MySQL + MHA -- 可以解决脑裂的问题,需要的IP多,小集群是可以的,但是管理大的就麻烦,其次MySQL + MMM 的话且坑很多,有MHA就没必要采用MMM
建议:
1.若是双主复制的模式,不用做数据拆分,那么就可以选择MHA或 Keepalive 或 heartbeat
2.若是双主复制,还做了数据的拆分,则可以考虑采用Cobar;
3.若是双主复制+Slave,还做了数据的拆分,需要读写分类,可以考虑Amoeba;
高可用性 :比较高
高可扩展性 :无
高一致性 :比较高
延迟性 :比较小
并发性 :无
事务性 :无
吞吐率 :比较高
数据丢失 :不丢失
可切换 :可以切换
高可用性 :比较高
高可扩展性 :无
高一致性 :比较高
延迟性 :比较小
并发性 :无
事务性 :无
吞吐率 :比较高
数据丢失 :不丢失
可切换 :可以切换
高可用性 : 很高
高可扩展性 : 可扩展,不能大规模扩展,也无需大规模扩展
高一致性 : 比较高
延迟性 : 比较大
并发性 : 比较小
事务性 : 有
吞吐率 : 比较小
数据丢失 : 不丢失
可切换 : 无关
高可用性 : 很高
高可扩展性 : 无关 可扩展,不能大规模扩展,也无需大规模扩展
高一致性 : 很高
延迟性 : 比较大
并发性 : 比较小
事务性 : 有
吞吐率 : 比较小
数据丢失 : 不丢失
可切换 : 无关
以上纯属个人理解,如有异议,也是没问题的;
另外按照master是否服务具体业务来分分布式可以分为两类:
基于这些方案的特点,如何设计一个牛逼滴分布式系统 ?
这里的牛逼包括
好了 你可以开始喷了 , 怎么可能。
paxos一致性协议,可用性很高,一致性很高,事务性很不错 , 那么涉及到各种服务都可以用他,非常好。
master和metadata元数据采用paxos一致性协议,所有节点也采用paxos一致性协议 , 客户端保持这些信息。架构如下所示 ,master, metadata, node 都实现了paxos协议,也即通过paxos接口访问
分布式数据库就是一个例子,貌似目前流行的数据库都还没有支持paxos协议的,有谁可以开发下。节点采用paxos的话,有个问题没想清楚,paxos如何sql结合使用?另外节点的性能会受一点影响。降低一点要求吧,节点采用主主复制,或者环形复制吧。master检查节点存活,并且做切换,通知客户端。
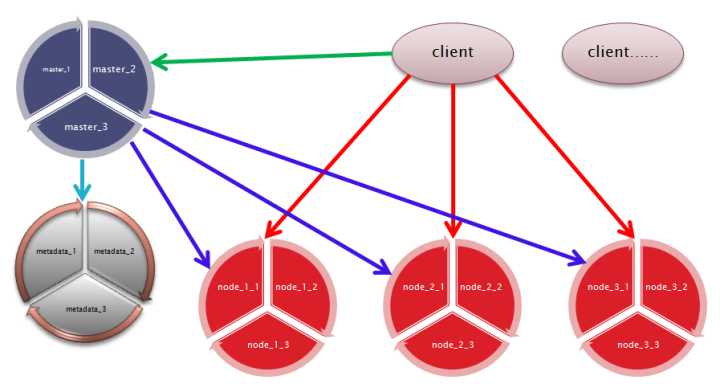
架构如下所示 ,master, metadata,实现了paxos协议,也即通过paxos接口访问;node的各个节点是复制关系,服务节点挂掉的时候,需要master检测,并且做切换处理。
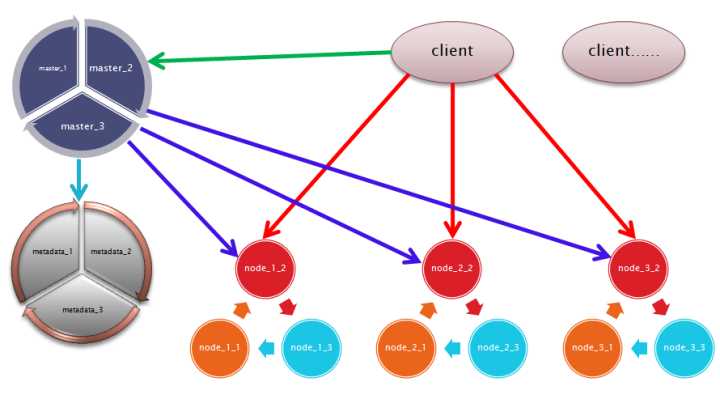
如果是分布式系统,比如文件系统,或者自己开发的系统, 那节点可以考虑用paxos协议哦。 每个节点采用3个实例,或者你有资源,采用5个实例。
分布式数据库的sql实现
也是一个难点,即一个复杂的sql,如何实现?
子句的处理逻辑和处理顺序 :
连接,包括内连接,左连接,右连接,半连接,外连接
以如下sql为例:
某一注册时间范围内的用户的所有登录信息
select t1.u_id,t1.u_name,t2.login_product
from tab_user_info t1 join tab_login_info t2
on (t1.u_id=t2.u_id and t1.u_reg_dt>=? and t1.u_reg_dt<=?)
生成的执行计划为:
由于是join,所有的表都要进行查询操作,并且为每张表打上自己的标签,具体实施的时候可以加个表名字字段,在所有存储节点上执行
select u_id,u_name from tab_user_info t where u_reg_dt>=? and t1.u_reg_dt<=?
select u_id, login_product from tab_login_info t
执行完成之后,这种情况下由于需要按照u_id进行数据洗牌,考虑到u_id的唯一值比较多,所以各个存储节点上需要按照u_id进行划分,
例如有N个计算节点,那么按照(最大u_id-最小u_id)/N平均划分,将不同存储节点上的同一范围的u_id,划分到同一个计算节点上
然后在计算节点上执行如下操作
select t1.u_id,t1.u_name,t2.login_product
from tab_user_info t1 join tab_login_info t2
on (t1.u_id=t2.u_id)
关于分布式sql如何实现的问题,有很多未尽事宜。有兴趣的可以相互讨论。欢迎切磋
几点补充:
1.对于需要严格保证强一致的场合来说,至少在 MySQL 5.7 之前,DRBD 还是有意义的。5.7 据说能实现真同步复制,若真能实现,就不再需要 DRBD 了。
2.网络分区时的脑裂问题必须避免,应使用基于多数派的选举算法来推选 Master。方案很多,比如用 ZooKeeper、etcd、Consul 等进行服务选举,推选出 Master。
3.MHA 没深入了解过,但印象里其 Master(Arbiter)节点貌似有单点问题?没记错的话此节点用于完成 MySQL 的主节点选举工作,它自己不 HA 还是有隐患。MySQL大型分布式集群1、主要解决针对大型网站架构中持久化部分中,大量数据存储以及高并发访问所带来是数据读写问题。分布式是将一个业务拆分为多个子业务,部署在不同的服务器上。集群是同一个业务,部署在多个服务器上。
2、着重对数据切分做了细致丰富的讲解,从数据切分的原理出发,一步一步深入理解数据的切分,通过深入理解各种切分策略来设计和优化我们的系统。这部分中我们还用到了数据库中间件和客户端组件来进行数据的切分,让广大网友能够对数据的切分从理论到实战都会有一个质的飞跃。
标签:keep name otp 限制 好的 支持 主机 union 解析
原文地址:http://www.cnblogs.com/timdes1/p/7747420.html