标签:chain webdriver return html reading int 构造函数 and mon
以下载官场风月小说为例:
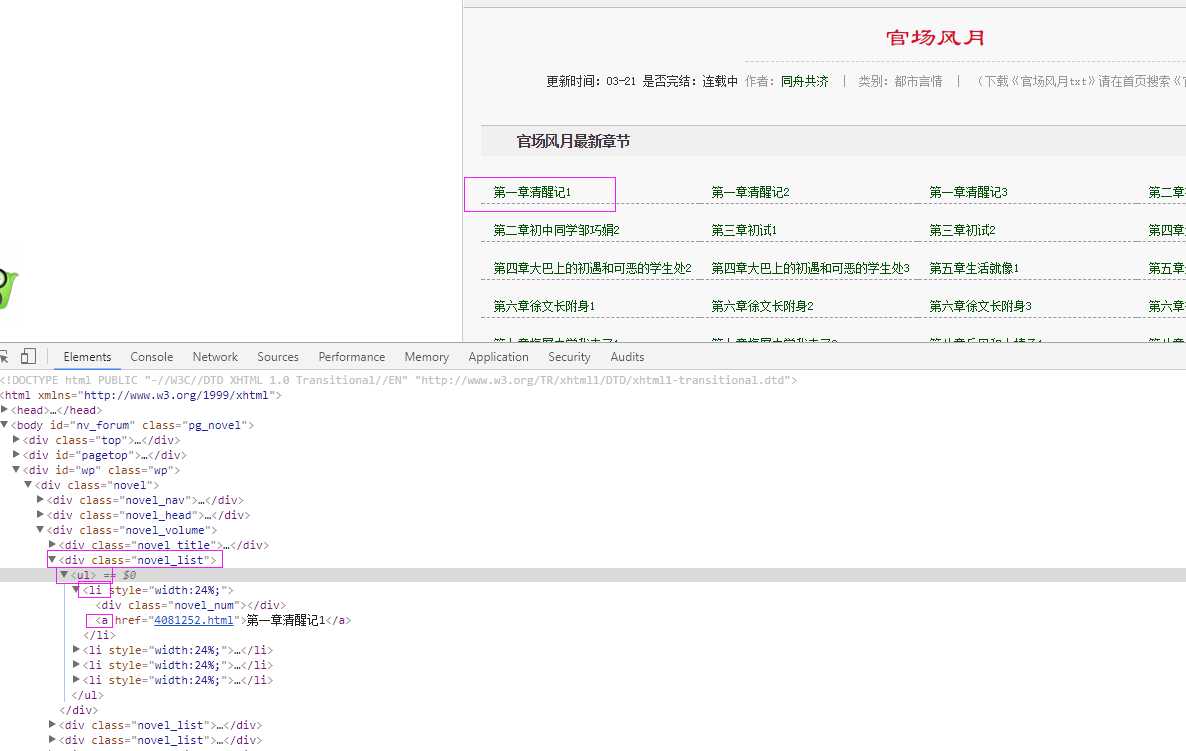
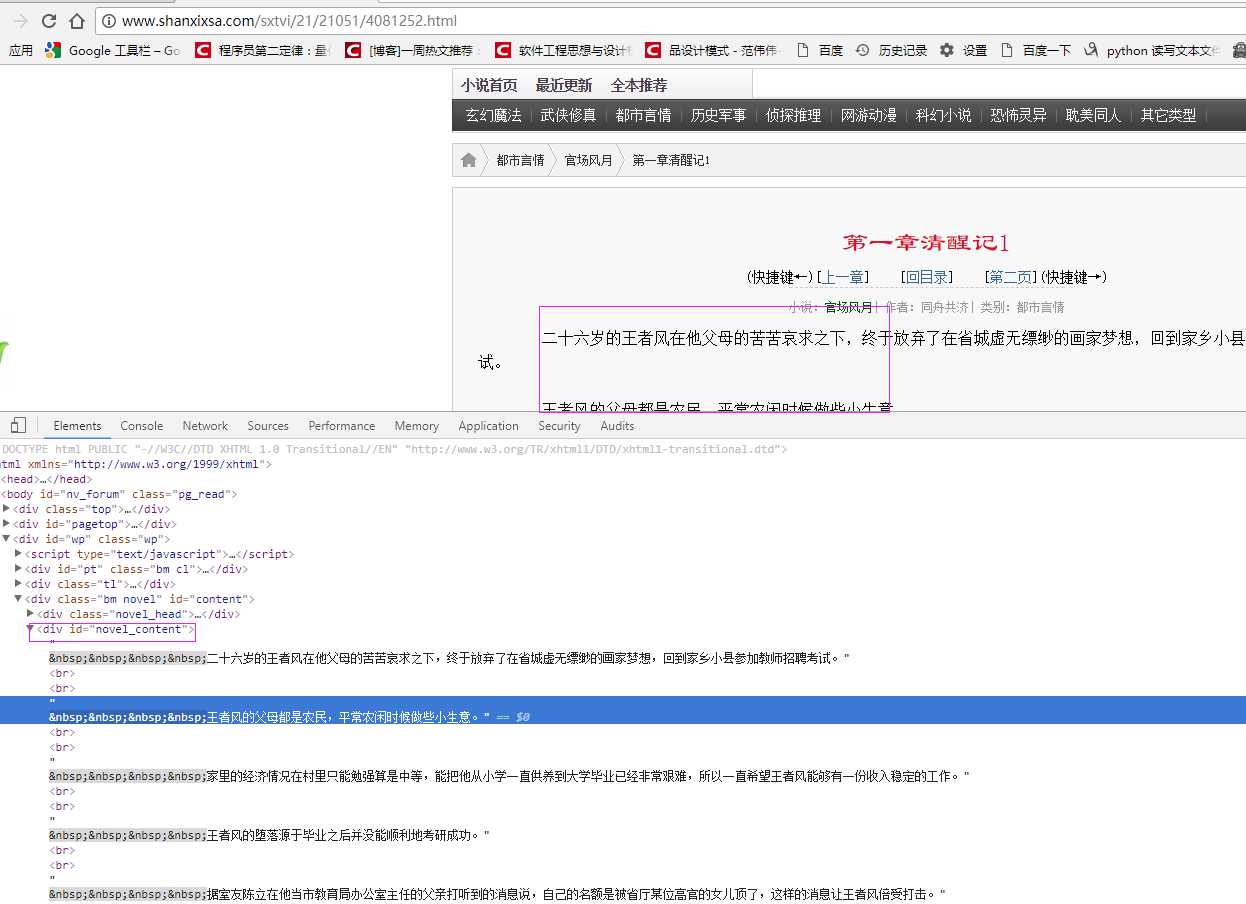
具体代码:
# coding=utf-8 import os import re from selenium import webdriver from selenium.common.exceptions import TimeoutException import selenium.webdriver.support.ui as ui import time from datetime import datetime from selenium.webdriver.common.action_chains import ActionChains # from threading import Thread from pyquery import PyQuery as pq import LogFile import urllib class downfile(object): def __init__(self,websearch_url,novelname): self.driver = webdriver.PhantomJS() # self.driver.set_page_load_timeout(10) self.driver.maximize_window() novel_name = unicode(novelname,‘utf8‘) logfile = os.path.join(os.getcwd(), ‘novel\\‘ + novel_name + ‘.txt‘) self.log = LogFile.LogFile(logfile) self.websearch_url = websearch_url def scroll_foot(self): ‘‘‘ 滚动条拉到底部 :return: ‘‘‘ js = "" # 如何利用chrome驱动或phantomjs抓取 if self.driver.name == "chrome" or self.driver.name == ‘phantomjs‘: js = "var q=document.body.scrollTop=10000" # 如何利用IE驱动抓取 elif self.driver.name == ‘internet explorer‘: js = "var q=document.documentElement.scrollTop=10000" return self.driver.execute_script(js) def scrapy_date(self): self.driver.get( self.websearch_url) htext = self.driver.execute_script("return document.documentElement.outerHTML") dochtml = pq(htext) Elements = dochtml(‘div[class="novel_list"]‘).find(‘ul‘).find(‘li‘).find(‘a‘) for e in Elements.items(): url = ‘http://www.shanxixsa.com/sxtvi/21/21051/‘+e.attr(‘href‘) txt = e.text().encode(‘utf8‘).strip() print txt self.log.WriteLog(txt) self.driver.get(url) shtext = self.driver.execute_script("return document.documentElement.outerHTML") sdochtml = pq(shtext) sElements = sdochtml(‘div[ID="novel_content"]‘) for se in sElements.items(): stxt = se.text().encode(‘utf8‘).strip() self.log.WriteLog(stxt) obj = downfile(‘http://www.shanxixsa.com/sxtvi/21/21051/index.html‘,‘官场风月‘) obj.scrapy_date() # -*- coding: utf-8 -*- import os import codecs import datetime import time import logging #封装logging日志 class LogFile: # def __init__(self,fileName): # self.fileName = os.path.join(os.getcwd(), fileName) # def WriteLog(self,message): # strMessage = ‘\r\n%s: %s‘ % (time.strftime(‘%Y-%m-%d_%H-%M-%S‘), message) # with open(self.fileName, ‘a‘) as f: # f.write(strMessage) #构造函数 fileName:文件名 def __init__(self,fileName,level=logging.INFO): fh = logging.FileHandler(fileName) self.logger = logging.getLogger() self.logger.setLevel(level) # formatter = logging.Formatter(‘%(asctime)s : %(message)s‘,‘%Y-%m-%d %H:%M:%S‘) formatter = logging.Formatter(‘%(message)s‘, ‘%Y-%m-%d %H:%M:%S‘) fh.setFormatter(formatter) self.logger.addHandler(fh) def WriteLog(self,message): self.logger.info(message) def WriteErrorLog(self,message): self.logger.setLevel(logging.ERROR) self.logger.error(message)
标签:chain webdriver return html reading int 构造函数 and mon
原文地址:http://www.cnblogs.com/shaosks/p/7749621.html