标签:执行 填充 数据集 复制 port 流程 and tree 第三方库
Numpy 和 scikit-learn 都是python常用的第三方库。numpy库可以用来存储和处理大型矩阵,并且在一定程度上弥补了python在运算效率上的不足,正是因为numpy的存在使得python成为数值计算领域的一大利器;sklearn是python著名的机器学习库,它其中封装了大量的机器学习算法,内置了大量的公开数据集,并且拥有完善的文档,因此成为目前最受欢迎的机器学习学习与实践的工具。
首先导入Numpy库
import numpy as np
a = [1,2,3,4,5,6] # python内置数组结构 b = np.array(a) # numpy数组结构
python有内置数组结构(list),我们为什么还要使用numpy的数组结构呢?为了回答这个问题,我们先来看看python内置的数组结构有什么样的特点。我们在使用list的时候会发现,list数组中保存的数据类型是不用相同的,可以是字符串、可以是整型数据、甚至可以是个类实例。这种存储方式很使用,为我们使用带来了很多遍历,但是它也承担了消耗大量内存的缺陷或不足。为什么这么说呢?实际上list数组中的每个元素的存储都需要1个指针和1个数据,也就是说list中保存的其实是数据的存放地址(指针),它比原生态的数组多了一个存放指针的内存消耗。因此,当我们想去减少内存消耗时,不妨将list替换成np.array,这样会节省不少的空间,并且Numpy数组是执行更快数值计算的优秀容器。
np.array([1,2,3]) # 创建一维数组 np.asarray([1,2,3]) np.array([1,2,3], [4,5,6]) # 创建多维数组 np.zeros((3, 2)) # 3行2列 全0矩阵 np.ones((3, 2)) #全1矩阵 np.full((3, 2), 5) # 3行2列全部填充5
np.array 和 np.asarray 的区别:
def asarray(a, dtype=None, order=None): return array(a, dtype, copy=False, order=order)
可见,它们区别主要在于: array会复制出一个新的对象,占用一份新的内存空间,而asarray不会执行这一操作。array类似深拷贝,array类似浅拷贝。
基础计算
arr1 = np.array([[1,2,3], [4,5,6]]) arr2 = np.array([[6,5], [4,3], [2,1]]) # 查看arr维度 print(arr1.shape) # (2, 3) #切片 np.array([1,2,3,4,5,6])[:3] #array([1,2,3]) arr1[0:2,0:2] # 二维切片 #乘法 np.array([1,2,3]) * np.array([2,3,4]) # 对应元素相乘 array([2,6, 12]) arr1.dot(b) # 矩阵乘法 #矩阵求和 np.sum(arr1) # 所有元素之和 21 np.sum(arr1, axis=0) #列求和 array([5, 7, 9]) np.sum(arr1, axis=1) # 行求和 array([ 6, 15]) # 最大最小 np.max(arr1, axis=0/1) np.min(a, axis=0/1)
进阶计算
arr = np.array([[1,2], [3,4], [5,6]]) #布尔型数组访问方式 print((arr>2)) """ [[False False] [ True True] [ True True]] """ print(arr[arr>2]) # [3 4 5 6] #修改形状 arr.reshape(2,3) """ array([[1, 2, 3], [4, 5, 6]]) """ arr.flatten() # 摊平 array([1, 2, 3, 4, 5, 6]) arr.T # 转置
sklearn是python的重要机器学习库,其中封装了大量的机器学习算法,如:分类、回归、降维以及聚类;还包含了监督学习、非监督学习、数据变换三大模块。sklearn拥有完善的文档,使得它具有了上手容易的优势;并它内置了大量的数据集,节省了获取和整理数据集的时间。因而,使其成为了广泛应用的重要的机器学习库。下面简单介绍一下sklearn下的常用方法。
sklearn.neighbors #近邻算法 sklearn.svm #支持向量机 sklearn.kernel_ridge #核-岭回归 sklearn.discriminant_analysis #判别分析 sklearn.linear_model #广义线性模型 sklearn.ensemble #集成学习 sklearn.tree #决策树 sklearn.naive_bayes #朴素贝叶斯 sklearn.cross_decomposition #交叉分解 sklearn.gaussian_process #高斯过程 sklearn.neural_network #神经网络 sklearn.calibration #概率校准 sklearn.isotonic #保守回归 sklearn.feature_selection #特征选择 sklearn.multiclass #多类多标签算法
以上的每个模型都包含多个算法,在调用时直接import即可,譬如:
from sklearn.linear_model import LogisticRefression lr_model = LogisticRegression()
sklearn.decomposition #矩阵因子分解 sklearn.cluster # 聚类 sklearn.manifold # 流形学习 sklearn.mixture # 高斯混合模型 sklearn.neural_network # 无监督神经网络 sklearn.covariance # 协方差估计
sklearn.feature_extraction # 特征提取 sklearn.feature_selection # 特征选择 sklearn.preprocessing # 预处理 sklearn.random_projection # 随机投影 sklearn.kernel_approximation # 核逼近
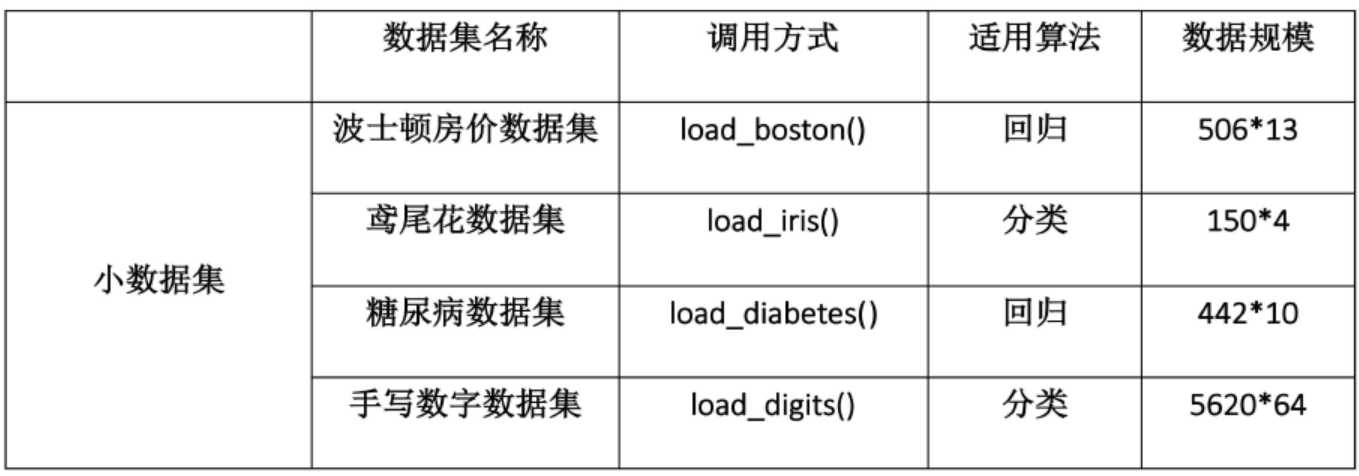
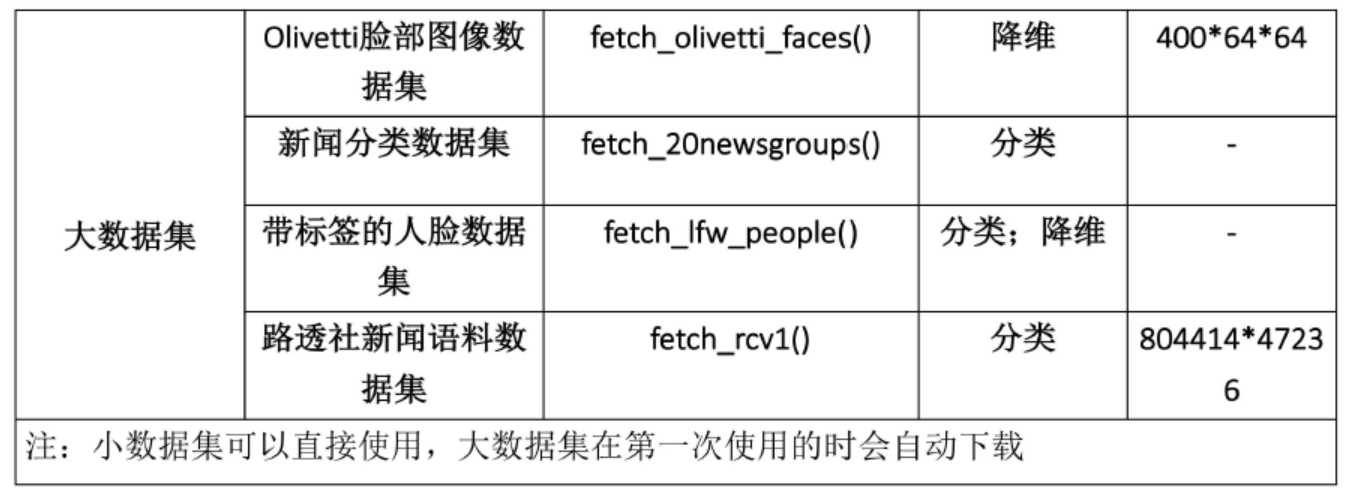
此外,sklearn还有统一的API接口,我们通常可以通过使用完全相同的接口来实现不同的机器学习算法,一般实现流程:
step1. 数据加载和预处理
step2. 定义分类器, 比如: lr_model = LogisticRegression()
step3. 使用训练集训练模型 : lr_model.fit(X,Y)
step4. 使用训练好的模型进行预测: y_pred = lr_model.predict(X_test)
step5. 对模型进行性能评估:lr_model.score(X_test, y_test)
标签:执行 填充 数据集 复制 port 流程 and tree 第三方库
原文地址:http://www.cnblogs.com/lianyingteng/p/7749609.html