标签:please lam 分布图 load() otl info exe 上下 ril
参考书籍《Python自然语言处理》,书籍中的版本是Python2和NLTK2,我使用的版本是Python3和NLTK3
实验环境Windows8.1,已有Python3.4,并安装了NumPy, Matplotlib,参考:http://blog.csdn.net/monkey131499/article/details/50734183
安装NLTK3,Natural Language Toolkit,自然语言工具包,地址:http://www.nltk.org/
安装命令:pip install nltk
代码:
SaintKings-Mac-mini:~ saintking$ sudo pip install nltk
Password:
The directory ‘/Users/saintking/Library/Caches/pip/http‘ or its parent directory is not owned by the current user and the cache has been disabled. Please check the permissions and owner of that directory. If executing pip with sudo, you may want sudo‘s -H flag.
The directory ‘/Users/saintking/Library/Caches/pip‘ or its parent directory is not owned by the current user and caching wheels has been disabled. check the permissions and owner of that directory. If executing pip with sudo, you may want sudo‘s -H flag.
Collecting nltk
Requirement already satisfied: six in /Library/Python/2.7/site-packages (from nltk)
Installing collected packages: nltk
Successfully installed nltk-3.2.5
SaintKings-Mac-mini:~ saintking$
安装完成后测试:import nltk
SaintKings-Mac-mini:~ saintking$ python
Python 2.7.10 (default, Jul 30 2016, 18:31:42)
[GCC 4.2.1 Compatible Apple LLVM 8.0.0 (clang-800.0.34)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import nltk
>>> nltk.download()
showing info https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/index.xml
没有报错即表明安装成功。
NLTK包含大量的软件、数据和文档,可以进行文本分析和语言结构分析等。数据资源可以自行下载使用。地址:http://www.nltk.org/data.html,数据列表:http://www.nltk.org/nltk_data/
下载NLTK-Data,在Python中输入命令:
>>>import nltk
>>>nltk.download()
弹出新的窗口,用于选择下载的资源
双击行后安装.
>>> import nltk
>>> nltk.download()
showing info https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/index.xml
True
>>>
点击File可以更改下载安装的路径。all表示全部数据集合,all-corpora表示只有语料库和没有语法或训练的模型,book表示只有书籍中例子或练习的数据。需要注意一点,就是数据的保存路径,要么在C盘中,要么在Python的根目录下,否则后面程序调用数据的时候会因为找不到而报错。
【注意:软件安装需求:Python、NLTK、NLTK-Data必须安装,NumPy和Matplotlin推荐安装,NetworkX和Prover9可选安装】
简单测试NLTK分词功能:
---
下面看一下NLTK数据的几种方法:
1.加载数据
>>> from nltk.book import *
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: ‘texts()‘ or ‘sents()‘ to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908
>>>
2.搜索文本
>>> print(text1.concordance(‘monstrous‘))
Displaying 11 of 11 matches:
ong the former , one was of a most monstrous size . ... This came towards us ,
ON OF THE PSALMS . " Touching that monstrous bulk of the whale or ork we have r
ll over with a heathenish array of monstrous clubs and spears . Some were thick
d as you gazed , and wondered what monstrous cannibal and savage could ever hav
that has survived the flood ; most monstrous and most mountainous ! That Himmal
they might scout at Moby Dick as a monstrous fable , or still worse and more de
th of Radney .‘" CHAPTER 55 Of the Monstrous Pictures of Whales . I shall ere l
ing Scenes . In connexion with the monstrous pictures of whales , I am strongly
ere to enter upon those still more monstrous stories of them which are to be fo
ght have been rummaged out of this monstrous cabinet there is no telling . But
of Whale - Bones ; for Whales of a monstrous size are oftentimes cast up dead u
None
>>>
3.相似文本
>>> print(text1.similar(‘monstrous‘))
imperial subtly impalpable pitiable curious abundant perilous
trustworthy untoward singular lamentable few determined maddens
horrible tyrannical lazy mystifying christian exasperate
None
>>>
4.共用词汇的上下文
>>> print(text2.common_contexts([‘monstrous‘,‘very‘]))
a_pretty is_pretty a_lucky am_glad be_glad
None
>>>
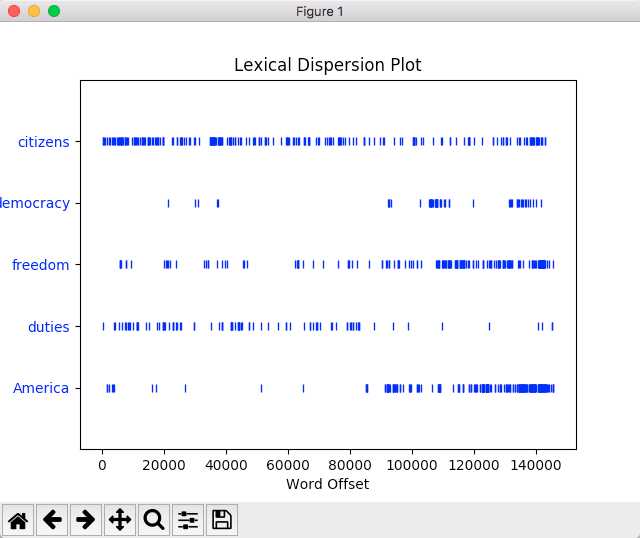
5.词汇分布图
>>> text4.dispersion_plot([‘citizens‘,‘democracy‘,‘freedom‘,‘duties‘,‘America‘])
6.词汇统计
#encoding=utf-8 import nltk from nltk.book import * print(‘~~~~~~~~~~~~~~~~~~~~~~~~~‘) print(‘文档text3的长度:‘,len(text3)) print(‘文档text3词汇和标识符排序:‘,sorted(set(text3))) print(‘文档text3词汇和标识符总数:‘,len(set(text3))) print(‘单个词汇平均使用次数:‘,len(text3)*1.0/len(set(text3))) print(‘单词 Abram在text3中使用次数:‘,text3.count(‘Abram‘)) print(‘单词Abram在text3中使用百分率:‘,text3.count(‘Abram‘)*100/len(text3))
标签:please lam 分布图 load() otl info exe 上下 ril
原文地址:http://www.cnblogs.com/kylinsblog/p/7755843.html