标签:删除 类设计 sorted 删除元素 ref ortmap 它的 [] 相等
参考博客:
http://www.jianshu.com/p/63e76826e852
http://www.cnblogs.com/LittleHann/p/3690187.html
https://github.com/pzxwhc/MineKnowContainer/issues/18
参数书籍
《java编程思想》 第十一章
一张图说明java集合类的组织关系 其中加粗的为常用集合类
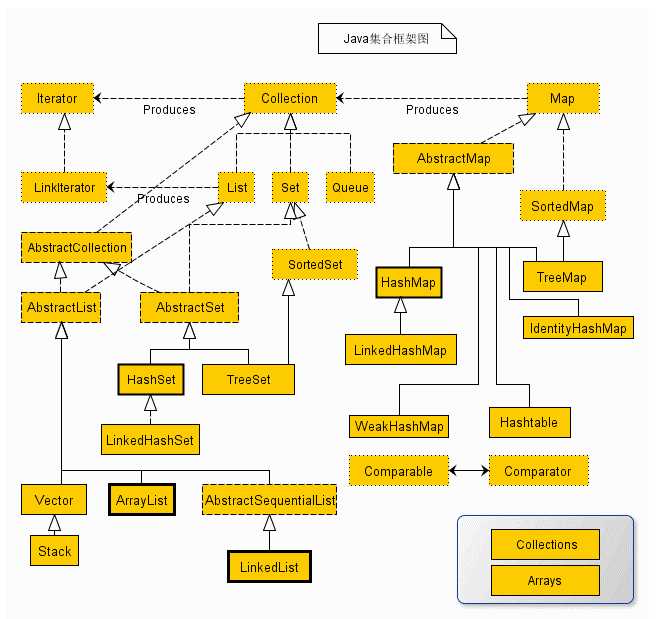
一:List集合
List 接口是Collection 接口的一个子类,在Collection 基础上扩充了方法。同时可以对每个元素插入的位置进行精确的控制,它的主要实现类有 ArrayList,Vector,LinkedList。
1.1 ArrayList
ArrayList 实现了 List 接口,意味着可以插入空值,也可以插入重复的值,非同步 ,它是 基于数组 的一个实现。从源码中的 DEFAULT_CAPACITY = 10 看出,其默认分配带下是长度为10的数组
ArrayList 不适合 增删操作非常多的操作, 首先可以看到这句话: elementData = Arrays.copyOf(elementData, newCapacity); 需要知道的是, Arrays.copyOf 函数的内部实现是再创建一个数组,然后把旧的数组的值一个个复制到新数组中。当经常增加操作的时候,容量不够的时候,就会进行上述的扩容操作,这样性能自然就下来了。 或者说,当我们在固定位置进行增删的时候,都会进行 System.arraycopy(elementData, index, elementData, index + 1, size - index); 也是非常低效的。
分析了低效出现的原因,那么我们就可以知道:如果我们需要经常进行特定位置的增删操作,那么最好还是不要用这个了,但是,如果我们基本上没有固定位置的增删操作,最好是要预估数据量的大小,然后再初始化最小容量,这样可以有效的避免扩容。如下代码:
ArrayList<Integer> arrayList = new ArrayList<Integer>(20);
ArrayList总结:
1.2 Vector
也是实现了 List 接口,所以也是 可以插入空值,可以插入重复的值。 它和 HashTable 一样,是属于一种同步容器,而不是一种并发容器。(参考《Java并发编程实战》,类似CopyOnWriteArrayList,ConcurrentHashMap这种就属于并发容器)
内部成员变量:
protected Object[] elementData;
public Vector() {
this(10);
}
可以看到,也是基于 数组的实现,初始化也是 10 个容量。 那么,再来看看 add()方法是否和 ArrayList 相同。
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
可以看到,和 ArrayList 也是一样的,只是加了 synchronized 进行同步, 其实很多其他方法都是通过加 synchronized 来实现同步。
Vector总结:
1.3 LinkedList
LinkedList 实现了 List 接口,所以LinkedList 也可以放入重复的值,也可以放入空值。LinkedList不支持同步。LinkedList 不同于ArrayList 和Vector,它是使用链表的数据结构,不再是数组。
当进行增删的时候,只需要改变指针,并不会像数组那样出现整体数据的大规模移动,复制等消耗性能的操作。
在学习数据结构的时候,我们知道链表和数组的最大区别在于它们对元素的存储方式的不同导致它们在对数据进行不同操作时的效率不同,ArrayList在做添加或者删除的时候 效率要低于linkedList
但在做遍历操作的时候,ArrayList要好于LinkedList
二:Set
set判断两个对象相同不是使用"=="运算符,而是根据equals方法
2.1 HashSet HashSet是Set接口的典型实现,HashSet使用HASH算法来存储集合中的元素,因此具有良好的存取和查找性能。当向HashSet集合中存入一个元素时,HashSet会调用该对象的
hashCode()方法来得到该对象的hashCode值,然后根据该HashCode值决定该对象在HashSet中的存储位置。 值得主要的是,HashSet集合判断两个元素相等的标准是两个对象通过equals()方法比较相等,并且两个对象的hashCode()方法的返回值相等 2.2 LinkedHashSet LinkedHashSet集合也是根据元素的hashCode值来决定元素的存储位置,但和HashSet不同的是,它同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的。
当遍历LinkedHashSet集合里的元素时,LinkedHashSet将会按元素的添加顺序来访问集合里的元素。 LinkedHashSet需要维护元素的插入顺序,因此性能略低于HashSet的性能,但在迭代访问Set里的全部元素时(遍历)将有很好的性能(链表很适合进行遍历) 2.3 SortedSet 此接口主要用于排序操作,即实现此接口的子类都属于排序的子类 2.4 TreeSet
2.5 EnumSet EnumSet是一个专门为枚举类设计的集合类,EnumSet中所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建EnumSet时显式、或隐式地指定。EnumSet的集合元素也是有序的,
它们以枚举值在Enum类内的定义顺序来决定集合元素的顺序
三:Queue
ueue用于模拟"队列"这种数据结构(先进先出 FIFO)。队列的头部保存着队列中存放时间最长的元素,队列的尾部保存着队列中存放时间最短的元素。新元素插入(offer)到队列的尾部,
访问元素(poll)操作会返回队列头部的元素,队列不允许随机访问队列中的元素。结合生活中常见的排队就会很好理解这个概念 3.1PriorityQueue PriorityQueue并不是一个比较标准的队列实现,PriorityQueue保存队列元素的顺序并不是按照加入队列的顺序,而是按照队列元素的大小进行重新排序,这点从它的类名也可以
看出来 3.2 Deque Deque接口代表一个"双端队列",双端队列可以同时从两端来添加、删除元素,因此Deque的实现类既可以当成队列使用、也可以当成栈使用 3.2.1) ArrayDeque 是一个基于数组的双端队列,和ArrayList类似,它们的底层都采用一个动态的、可重分配的Object[]数组来存储集合元素,当集合元素超出该数组的容量时,系统会在底层重
新分配一个Object[]数组来存储集合元素 3.2.2) LinkedList
四:map
实现类:HashMap、Hashtable、LinkedHashMap和TreeMap
HashMap
HashMap是最常用的Map,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度,遍历时,取得数据的顺序完全是随机的。因为键对象不可以重复,所以HashMap最多只允许一条记录的键为Null,允许多条记录的值为null,是非同步的。
Hashtable
Hashtable与HashMap类似,是HashMap的线程安全版,它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢,他继承自Dictionary类,不同的是它不允许记录的键或者值为null,同时效率较低。
ConcurrentHashMap
线程安全,并且锁分离。ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hashtable,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。
LinkedHashMap
LinkedHashMap保存了记录的插入顺序,在用Iteraor遍历LinkedHashMap时,先得到的记录肯定是先插入的,在遍历的时候会比HashMap慢,有HashMap的全部特性。
TreeMap
TreeMap实现了SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序(自然顺序),也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。不允许key值为空,非同步的。
标签:删除 类设计 sorted 删除元素 ref ortmap 它的 [] 相等
原文地址:http://www.cnblogs.com/luffyu/p/7762923.html