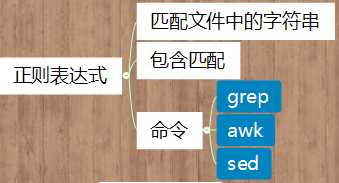
标签:a* unix cas 条件判断 输出 amp 关系运算 txt 没有

~ grep "a*" test_rule.txt # 匹配所有内容,包括空白行
~ grep "aa*" test_rule.txt # 匹配至少包含两个连续 a 的字符串
~ grep "aaa*" test_rule.txt # 匹配最少包含两个连续a的字符串
~ grep "aaaa*" test_rule.txt # 匹配最少包含四个个连续a的字符串
~ grep "s..d" test_rule.txt # “ s..d ”会匹配在 s 和 d 这两个字母之间一定有两个字符的单词
~ grep "s.*d" test_rule.txt # 匹配在 s 和 d 字母之间有任意字符
~ grep ".*" test_rule.txt # 匹配所有内容
~ grep "^M" test_rule.txt # 匹配以大写“ M ”开头的行
~ grep "n$" test_rule.txt # 匹配以小写“ n ”结尾的行
~ grep -n "^$" test_rule.txt # 会匹配空白行
~ grep " s[ao]id " test_rule.txt # 匹配 s 和 i 字母中,要不是 a 、要不是
~ grep "[0-9]" test_rule.txt # 匹配任意一个数字
~ grep "[a-z]" test_rule.txt # 匹配用小写字母开头的行
~ grep "^[^a-z]" test_rule.txt # 匹配不用小写字母开头的行
~ grep "^[^a-zA-Z]" test_rule.txt # 匹配不用字母开头的行
~ grep "\.$" test_rule.txt # 匹配使用“ . ”结尾的行
~ grep "a\{3\}" test_rule.txt # 匹配 a 字母连续出现三次的字符串
~ grep "[0-9]\{3\}" test_rule.txt # 匹配包含连续的三个数字的字符串
~ grep "^[0-9]\{3,\}[a-z]" test_rule.txt # 匹配最少用连续三个数字开头的行
~ grep "sa\{1,3\}i" test_rule.txt # 匹配在字母 s 和字母 i 之间有最少一个 a ,最多三a
[options]
-f 行号: 提取第几列
-d 分隔符: 按照指定分隔符分割列

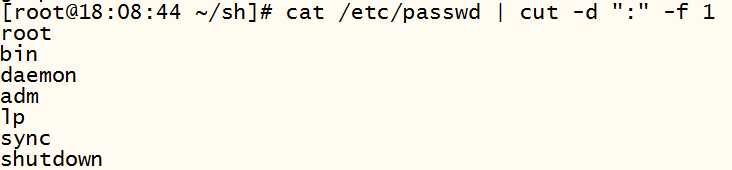

4)example局限性(无法匹配空格)

print ‘ 输出类型 输出格式 ’ 输出内容


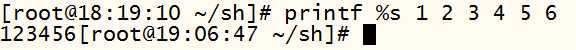



print : print 会在每个输入之后自动加入一个换行符(linux 默认没有 print 命令)
printf :是标准格式输出命令,并不会手动加入换行符,如果需要换行,需要手工加入换行符
example:
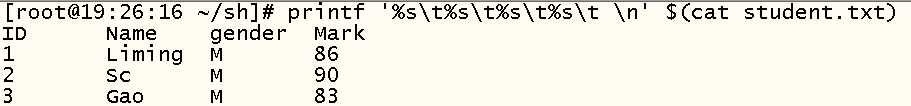

条件:一般使用关系表达式作为条件
x>=10 大于等于
x > 10 判断变量 x是否大于10
x<=10 小于等于
动作
格式化输出
流程控制语句





1)、简介:
sed 是一种几乎包括在所有 UNIX 平台 (包括 linux)的轻量级流编辑器。
sed 主要是用来将数据进行选取,替换,删除,新增的命令。
2)、用法:
sed【options】【actions】文件名
【options】
- n :
- e :
- i :
【actions】
a \ :
c \ :
i \ :
标签:a* unix cas 条件判断 输出 amp 关系运算 txt 没有
原文地址:http://www.cnblogs.com/-cjzsr-/p/7755165.html