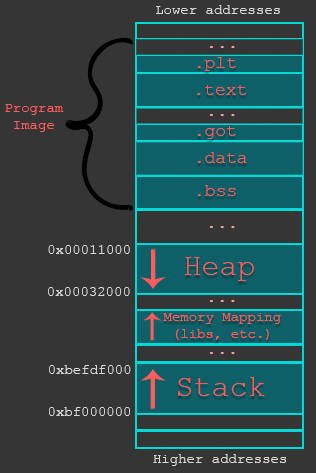
缓冲区溢出是最普遍的内存损坏类之一,通常是由于编程错误导致用户提供的数据多于目标变量(缓冲区)的数据量。例如,在使用易受攻击的函数(如get,strcpy,memcpy等)以及用户提供的数据时,会发生这种情况。这些函数不会检查用户数据的长度,这可能会导致写入(溢出)分配的缓冲区。为了更好地理解,我们将研究 基于堆栈和堆的缓冲区溢出的基础知识。
堆栈溢出
正如名称所示,堆栈溢出是影响堆栈的内存破坏。尽管在大多数情况下,堆栈的任意损坏很可能导致程序崩溃,但精心设计的堆栈缓冲区溢出会导致任意代码执行。下图显示了堆栈如何被损坏的抽象概述。
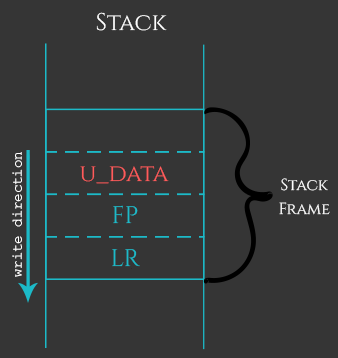
如上图所示,堆栈帧(整个堆栈专用于特定功能的一小部分)可以具有各种组件:用户数据,先前的帧指针,先前的链接寄存器等。如果用户也提供控制变量的大部分数据,FP和LR字段可能会被覆盖。这会中断程序的执行,因为用户破坏了当前函数完成后应用程序将返回/跳转的地址。
为了检查它在实践中的样子,我们可以使用这个例子:
/ * azeria @ labs:?/ exp $ gcc stack.c -o stack * /
#include“stdio.h”
int main(int argc,char ** argv)
{
字符缓冲区[8];
得到(缓冲液);
}
我们的示例程序使用变量“buffer”,长度为8个字符,并为用户输入一个函数“gets”,它简单地将变量“buffer”的值设置为用户提供的任何输入。这个程序的反汇编代码如下所示:
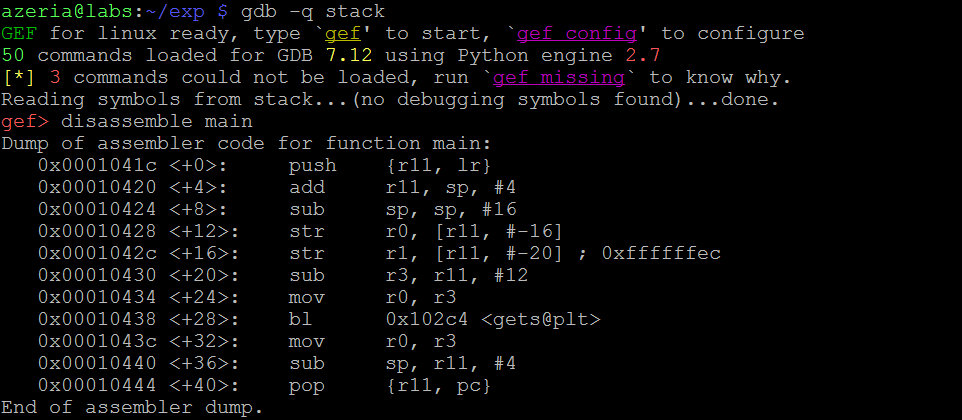
在这里,我们怀疑在“gets”函数完成后,内存损坏可能会发生。为了调查这一点,我们在调用“gets”函数的分支指令之后放置一个断点 - 在我们的例子中,地址为0x0001043c。为了减少噪音,我们配置GEF的布局,只显示代码和堆栈(见下图中的命令)。一旦设置了断点,我们继续执行程序,并提供7个A作为用户的输入(我们使用7个A,因为空字节将被函数“gets”自动附加)。
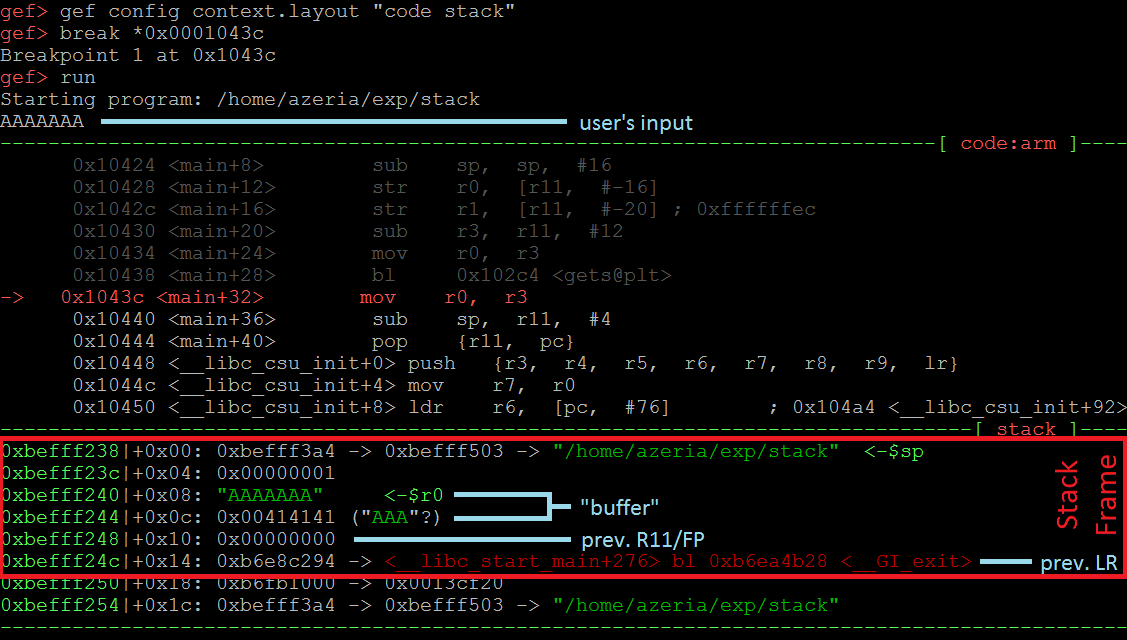
当我们调查我们的例子的堆栈时,我们看到(上图)堆栈帧没有被破坏。这是因为用户提供的输入符合预期的8字节缓冲区,并且堆栈帧中的前一个FP和LR值没有被破坏。现在我们提供16个A,看看会发生什么。
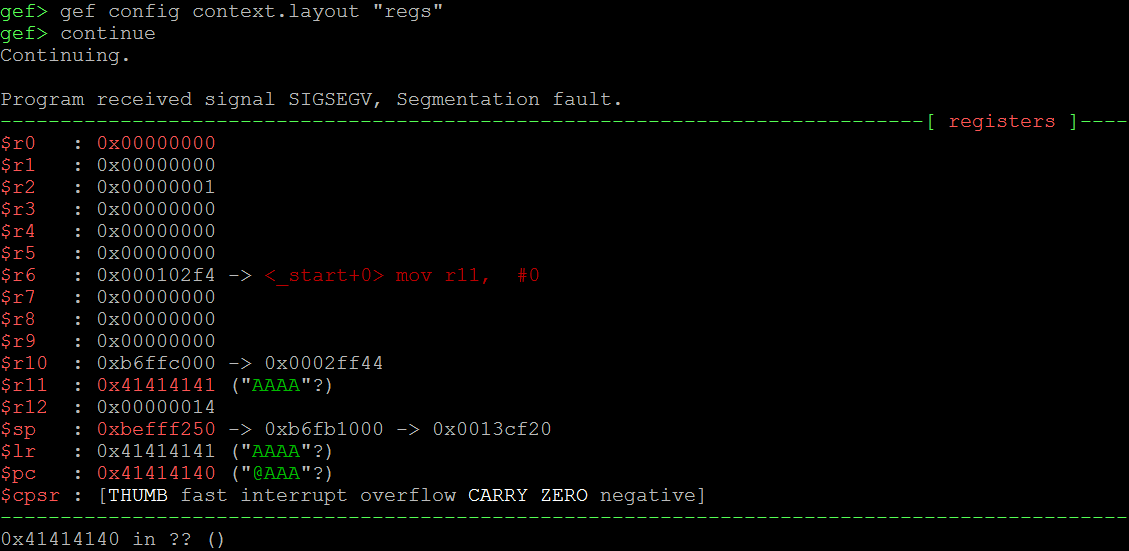
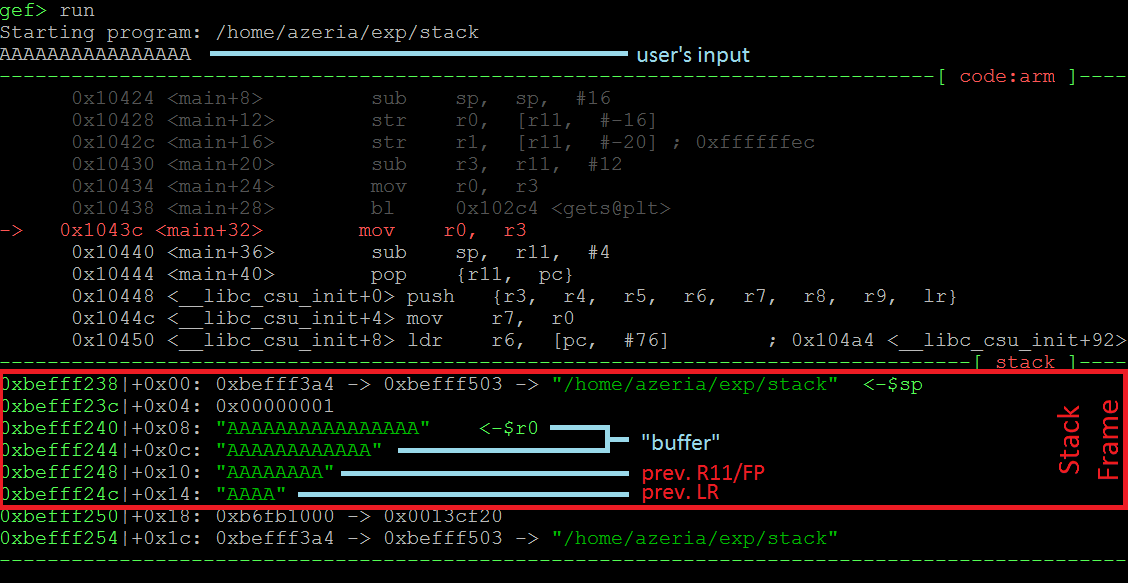 在第二个例子中,我们看到(上图),当我们为函数“gets”提供太多的数据时,它不会停留在目标缓冲区的边界处,而是一直写下“堆栈”。这导致我们以前的FP和LR值被破坏。当我们继续运行程序时,程序崩溃(导致“分段错误”),因为在当前函数的结尾处,FP和LR的先前值被“堆栈”到R11和PC寄存器中,迫使程序跳转到地址0x41414140(由于切换到Thumb模式,最后一个字节自动转换为0x40),在这种情况下,这是非法地址。下面的图片显示了在崩溃时寄存器的值(看看$ pc)。
在第二个例子中,我们看到(上图),当我们为函数“gets”提供太多的数据时,它不会停留在目标缓冲区的边界处,而是一直写下“堆栈”。这导致我们以前的FP和LR值被破坏。当我们继续运行程序时,程序崩溃(导致“分段错误”),因为在当前函数的结尾处,FP和LR的先前值被“堆栈”到R11和PC寄存器中,迫使程序跳转到地址0x41414140(由于切换到Thumb模式,最后一个字节自动转换为0x40),在这种情况下,这是非法地址。下面的图片显示了在崩溃时寄存器的值(看看$ pc)。
堆溢出
首先,堆是一个更复杂的内存位置,主要是因为它的管理方式。为了简单起见,我们坚持这样一个事实,即放在堆内存部分的每个对象都被“打包”成一个包含头部和用户数据(有时用户完全控制)两部分的“块”。在堆的情况下,当用户能够写入比预期更多的数据时,会发生内存损坏。在这种情况下,损坏可能发生在块的边界内(块内堆溢出),或跨两个(或更多)块的边界(块间堆溢出)发生。为了更好地理解,下面我们来看看下面的插图。
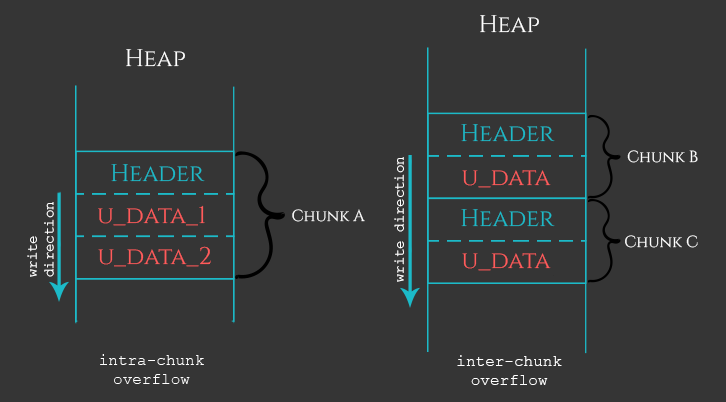
如上图所示,当用户有能力向u_data_1提供更多数据并跨越u_data_1和u_data_2之间的边界时,会发生块内堆溢出。这样当前对象的字段/属性就会被破坏。如果用户提供的数据比当前堆大小可容纳的数据多,则溢出会变成块间并导致相邻块的损坏。
块内堆溢出
为了演示块内堆溢出在实际中的样子,我们可以使用下面的例子,并用“-O”(优化标志)编译它,使其具有更小的(二进制)程序(更易于查看)。
/ * azeria @ labs:?/ exp $ gcc intra_chunk.c -o intra_chunk -O * /
#include“stdlib.h”
#include“stdio.h”
struct u_data //对象模型:名称为8个字节,数字为4个字节
{
char name [8];
int数字
};
int main(int argc,char * argv [])
{
struct u_data * objA = malloc(sizeof(struct u_data)); //在堆中创建对象
objA-> number = 1234; //将我们的对象的数量设置为一个静态值
得到(objA->名); //根据用户的输入设置我们的对象的名字
if(objA-> number == 1234)//检查静态值是否完整
{
puts(“Memory valid”);
}
否则//在静态值被破坏的情况下继续
{
放(“内存损坏”);
}
}
上述程序执行以下操作:
- 用两个字段定义数据结构(u_data)
- 创建类型为u_data的对象(在堆内存区域中)
- 将静态值分配给对象的数字字段
- 提示用户为对象的名称字段提供一个值
- 根据数字字段的值打印字符串
所以在这种情况下,我们也怀疑贪污可能发生在“获取”功能之后。我们分解目标程序的主要功能来获取断点的地址。
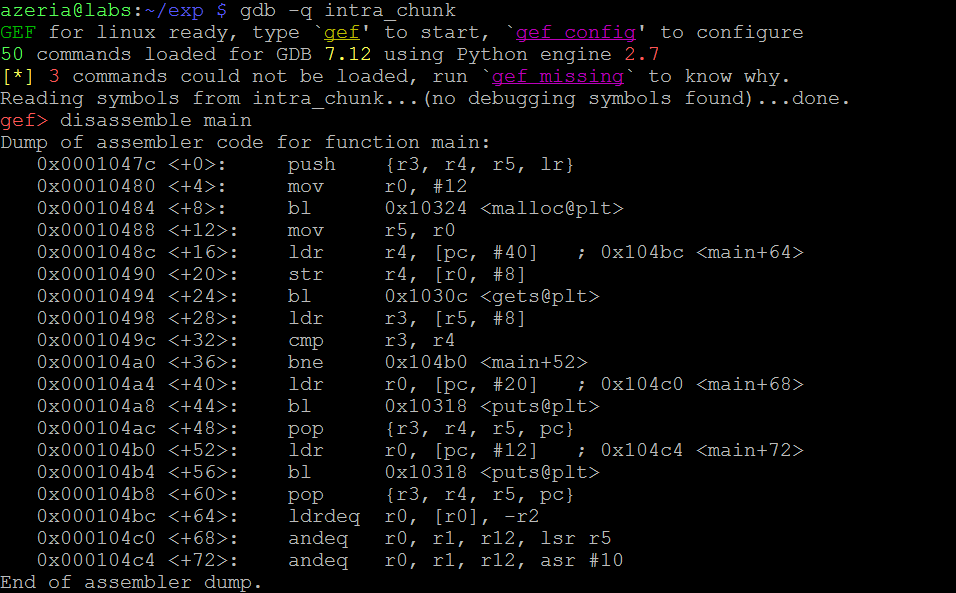
在这种情况下,我们在地址0x00010498处设置断点 - 在函数“gets”完成之后。我们配置GEF只显示我们的代码。然后我们运行该程序并提供7个A作为用户输入。
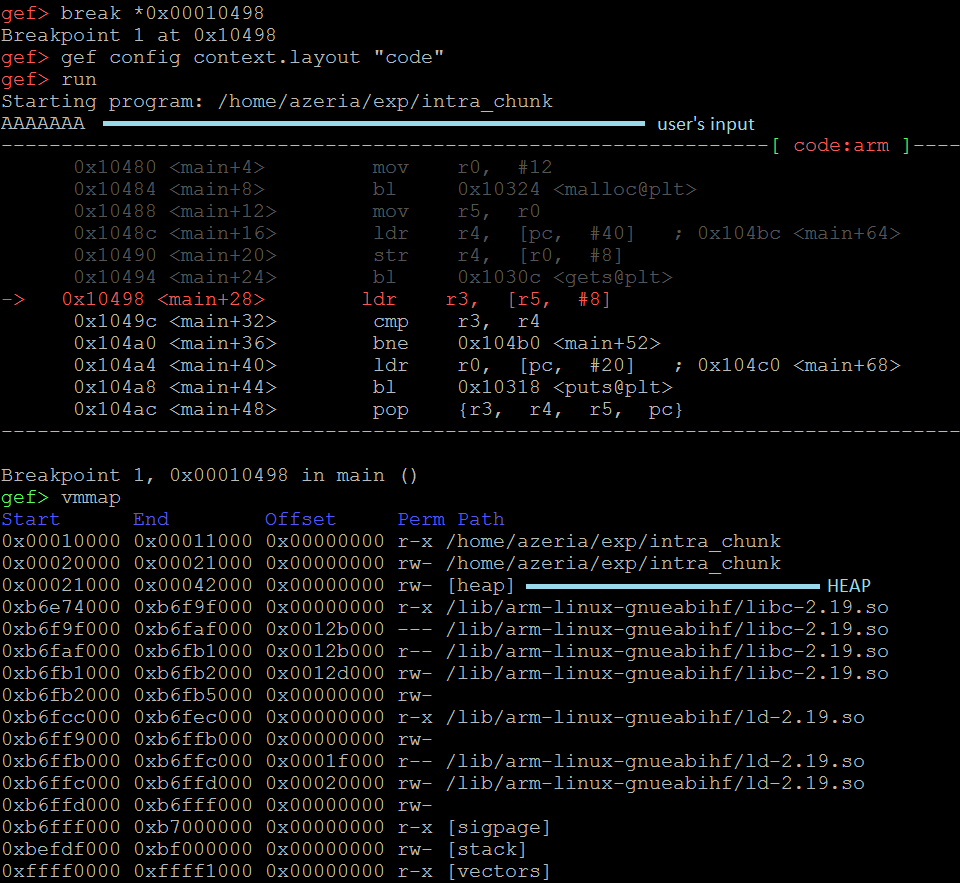
一旦中断点被击中,我们快速查找我们的程序的内存布局,以找到我们的堆是在哪里。我们使用vmmap命令,看到我们的Heap从地址0x00021000开始。考虑到我们的对象(objA)是程序创建的第一个也是唯一的对象,我们将从头开始分析堆。
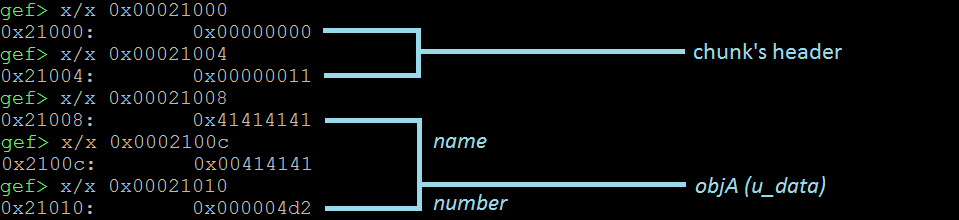
上面的图片向我们展示了与我们的对象相关的Heap块的详细分解。该块有一个头(8字节)和用户的数据部分(12字节)存储我们的对象。我们看到name字段正确存储了提供的7个字符串,以空字节结尾。数字字段存储0x4d2(十进制数1234)。到现在为止还挺好。让我们重复这些步骤,但在这种情况下输入8个A的。
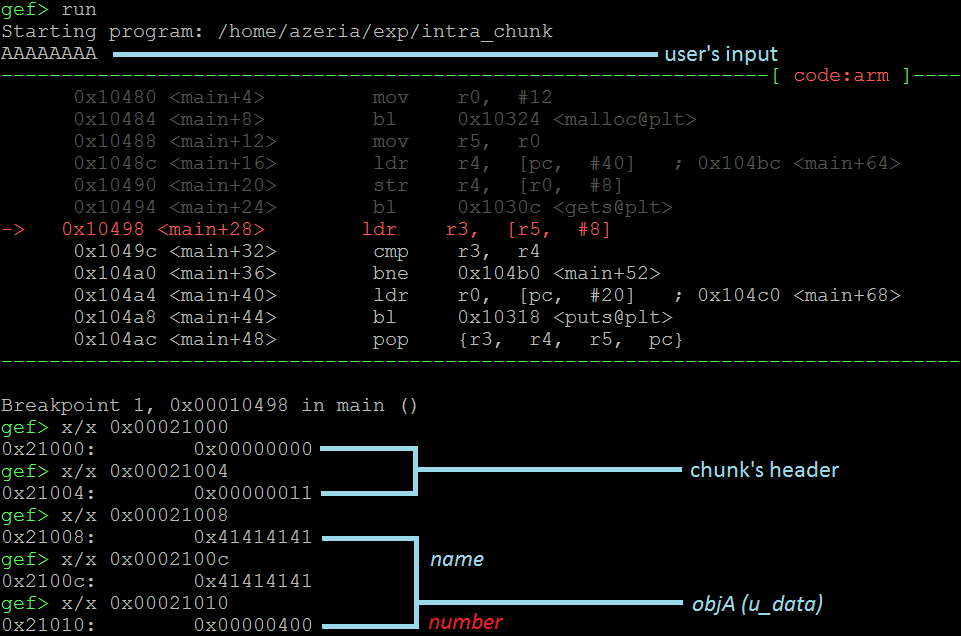
在这次检查堆时,我们看到数字的字段被破坏了(现在等于0x400而不是0x4d2)。空字节终结符覆盖了数字字段的一部分(最后一个字节)。这会导致内部块堆内存损坏。在这种情况下,这种腐败的影响并不是破坏性的,而是可见的。从逻辑上讲,代码中的else语句永远不会达到,因为数字的字段是静态的。但是,我们刚刚观察到的内存损坏使得可能达到这部分代码。这可以通过下面的示例轻松确认。

块间??堆溢出
为了说明在实际中如何实现块间堆溢出,我们可以使用下面的例子,我们现在编译时没有优化标记。
/ * azeria @ labs:?/ exp $ gcc inter_chunk.c -o inter_chunk * /
#include“stdlib.h”
#include“stdio.h”
int main(int argc,char * argv [])
{
char * some_string = malloc(8); //在堆中创建some_string“对象”
int * some_number = malloc(4); //在堆中创建some_number“object”
* some_number = 1234; //为some_number分配一个静态值
得到(some_string); //请求用户输入some_string
如果(* some_number == 1234)//检查(some_number的)静态值是否有效
{
puts(“Memory valid”);
}
否则//在静态some_number被破坏的情况下继续
{
放(“内存损坏”);
}
}
这里的过程和以前的过程类似:在函数“gets”之后设置一个断点,运行程序,提供7个A,调查Heap。
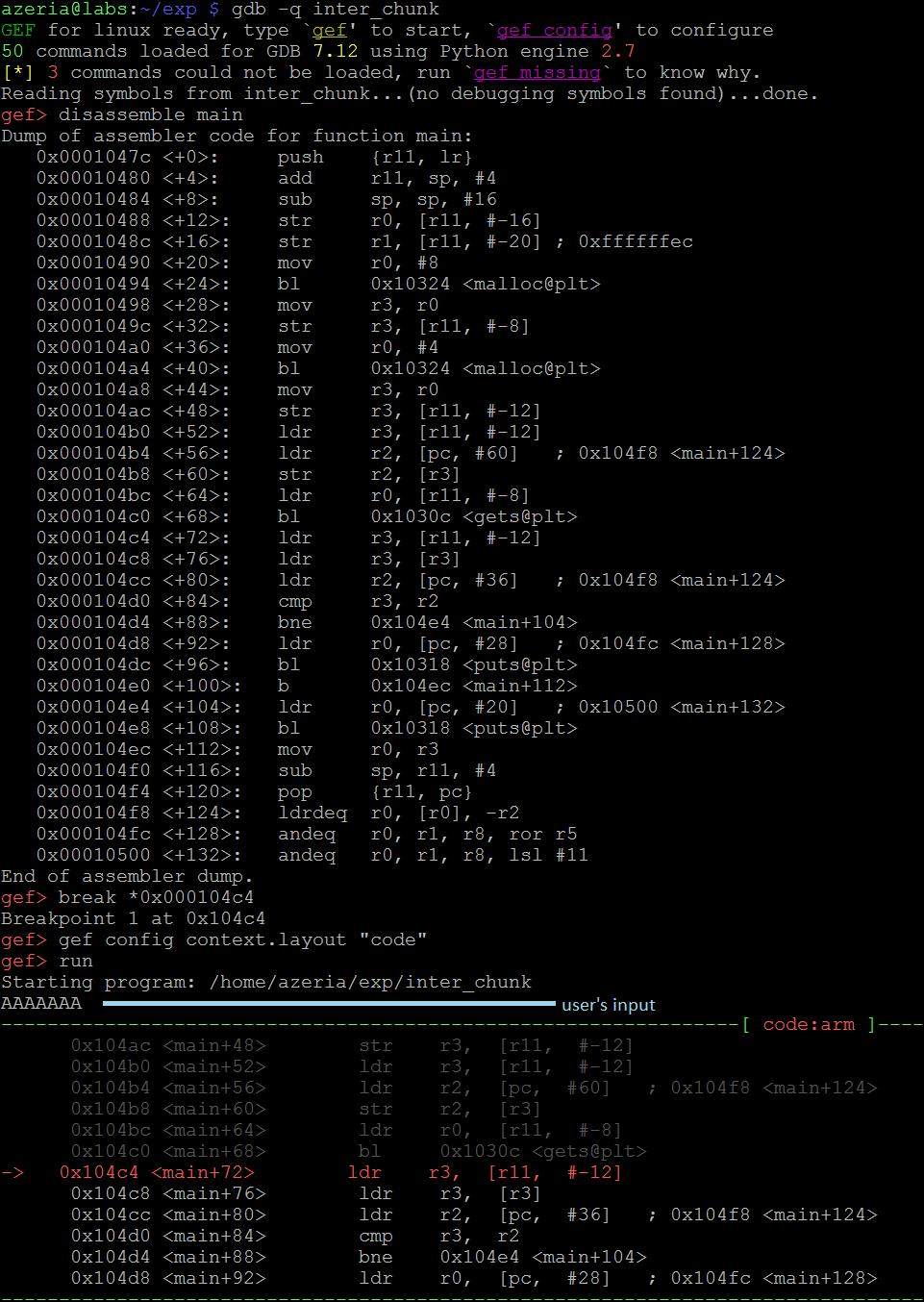
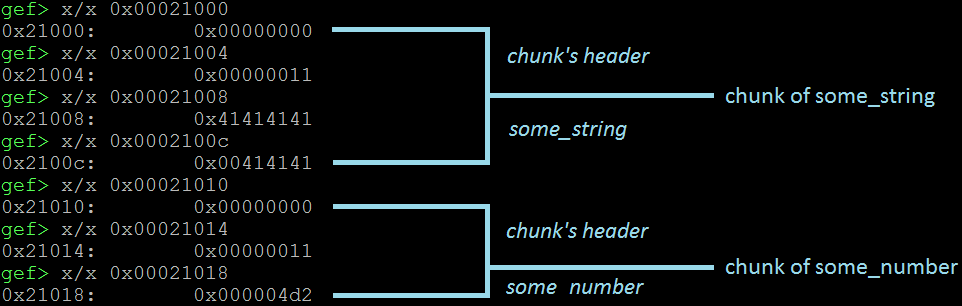
一旦中断点被击中,我们检查堆。在这种情况下,我们有两个块。我们看到(下图),它们的结构是一致的:some_string在其边界内,some_number等于0x4d2。
现在,我们提供16个A,看看会发生什么。
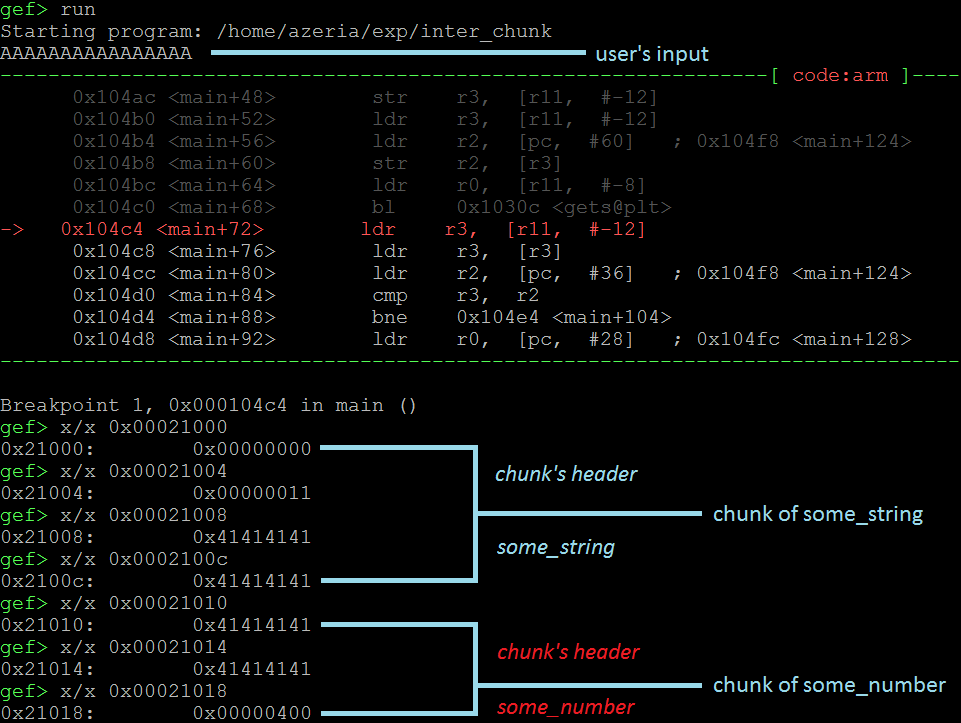
正如您可能已经猜到的那样,提供太多的输入会导致溢出导致相邻块的损坏。在这种情况下,我们看到我们的用户输入损坏了头部和some_number字段的第一个字节。再次,通过破坏some_number我们设法达到逻辑上永远不应该达到的代码部分。