标签:col .com level read let dex sample 其他 down
PS:作为一个新手如果你不想使用IDE又想使用Python中的自动补全,可以下载使用ipython。下面实例中也大多是ipython输入和输出的内容。
安装ipython:pip3 install ipython
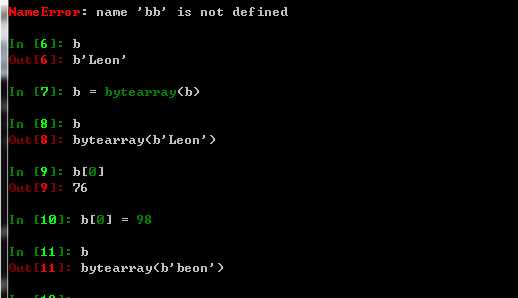
概念:列表生成式可以简单理解成是将原来的列表转换成一个有规律的新列表;这里比方将原来的列表a中的所有大于5的数据全部加一。这时候你肯定会想到直接用for循环做这件事,事实上也是可以的;但是由于为了更加节省代码,也有以下这几种策略。
- 最熟悉的for循环
1 a = [0,1,2,3,4,5,6,7,8,9,10] 2 3 for i in a: 4 a[i] = i + 1 5 6 print(a) 7 8 9 #这个实例如果想将生成好的列表赋值到原来的列表中其实是有很多限制的比如说当前的列表必须是用0开始,第二每个直接的数值相差也必须是1
- 活学活用的enumerate
1 a = [1,2,3,5,7,7,9,10,11] 2 3 for index,i in enumerate(a): 4 a[index] += 1 5 6 print(a)
- 列表生成器

1 #简单实现功能 so easy 2 3 4 a = [1,2,3,5,7,7,9,10,11] 5 6 a = [i + 1 for i in a] 7 print(a) 8 9 #支持三元运算 10 11 a = [1,2,3,5,7,7,9,10,11] 12 13 a = [i * i if i > 5 else i for i in a] 14 15 print(a) 16 #这里我们将列表中所有的数据只要大于5,都自乘
- 列表生成器直接的步骤
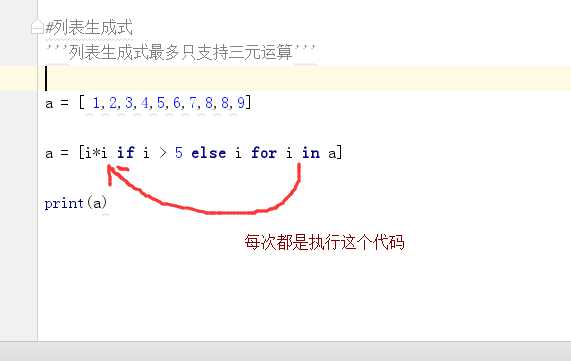
通过列表生成器,我们可以直接得到一个新列表,但是我们知道列表是有长度的,而且之间创建一个大的列表是很消耗内存的。如果当我们创建一个列表的时候我们仅需要前面的某些元素,后面的空间也会白白浪费。这时我们就可以让这个列表一个一个生成,这就是生成器(generator)
- 创建一个生成器也很简单只需要吧中括号改成小括号就行
a = [1,3,5,6,7,8,9,11,13,15] a = (i * i if i == 9 else i + 5 for i in a) print(a) print(next(a)) #等于 a.__next__() for i in a: print(‘geerator:‘,i)
- 通过运行上面代码我们可以发现第一个print只返回了一个6,这是为什么呢,但是仔细一看我的条件是只有等于9的才相乘,其他的都是自加5,二列表中的第一个书就是一个1,1+5这个算数这个就不用多说了,值得一说的就是生成器是一个对象,也就是可以被调用的,通过for循环可以将列表中多有的数字遍历一遍,而如果我们是一个一个next()直到最后一个不仅傻而且大多数的时候你并不知道这个列表的长度,一旦超过列表真实长度就会抛出异常。
- 斐波拉契数列(这个不会刻意理解)
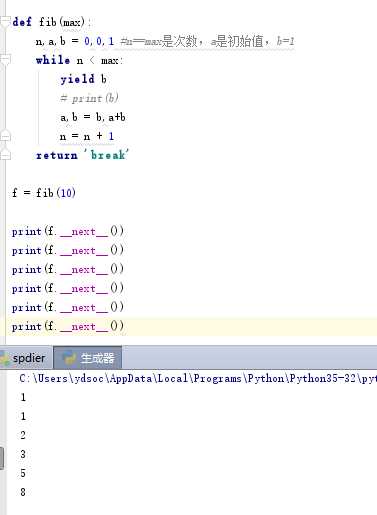
def fib(max): n,a,b = 0,0,1 #n==max是次数,a是初始值,b=1 while n < max print(b) a,b = b,a+b n = n + 1 return ‘break‘
- 什么是斐波拉契:简单的说就是后面的数,等于前面的两个数相加,我们调用上面的函数,比方说flb(10)这个函数就会循环十次,会直接十次的数字全部打印出来,如果这个时候我们想一个一个打印出来呢?
- 生成器的fib
def fib(max): n,a,b = 0,0,1 #n==max是次数,a是初始值,b=1 while n < max: #print(b) yield b a,b = b,a+b n = n + 1 return ‘break‘ f = fib(6) # --> 生成器
-- 串行生成器
什么是串行生成器:串行生成器就是generator对象被反复调用期间做其他的一些工作,比如说执行一个函数。
- 吃包子程序(实在是想不出其他的东西了,其实是不想写)
import time def consumer(name): print("开始吃包子了"%name) while True: baozi = yield print("包子%s来了,被%s!"%(baozi,name)) def producer(name): c = consumer("Leon") c1 = consumer("CHEN") c.__next__() c1.__next__() print("开始吃包子了") for i in range(10): time.sleep(1) print("做了两个包子") c.send(i) # send方法可以将指传入到上面的yield对应的变量 c1.send(i) producer("MA")
这个列子只需要知道,使用生成器可以实现假并发,实际是串行,和yield是可以赋值,并且使用seed是可以向生成器中传值得。
在写迭代器之前,我们需要知道什么数据类型是可以被迭代的(可以被for循环)。
- 字典
- 列表
- 字符串
- 生成器
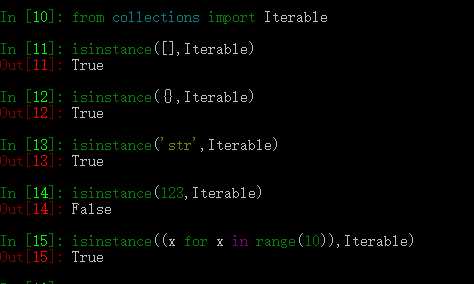
- 那些数据类型是迭代器
>>> from collections import Iterator >>> isinstance((x for x in range(10)), Iterator) True >>> isinstance([], Iterator) False >>> isinstance({}, Iterator) False >>> isinstance(‘abc‘, Iterator) False
- 生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
小结
- 凡是可作用于for循环的对象都是Iterable类型;
- 凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
- 集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
- time 模块
In [1]: import time In [2]: time.time() #显示时间戳 Out[2]: 1508836530.6026018 In [3]: time.gmtime() #UTC的时间对象 Out[3]: time.struct_time(tm_year=2017, tm_mon=10, tm_mday=24, tm_hour=9, tm_min=15, tm_sec=51, tm_wday=1, tm_yday=297, tm_isdst=0) In [4]: t = time.gmtime() #取出对象中的年月日 In [5]: t.tm_year Out[5]: 2017 In [6]: t.tm_mon Out[6]: 10 In [7]: time.clock()#老子也不知道是啥反正没有用就是了 Out[7]: 2.8444452535310943e-07 In [8]: time.asctime() 返回时间格式 Out[8]: ‘Tue Oct 24 17:17:05 2017‘ In [10]: time.localtime() #和上面的gmtime差不多只不过是本地的时间对象 Out[10]: time.struct_time(tm_year=2017, tm_mon=10, tm_mday=24, tm_hour=17, tm_min=28, tm_sec=38, tm_wday=1, tm_yday=297, tm_isdst=0) In [12]: time.strftime("%Y-%m-%d %H:%M:%S") #自定义时间 Out[12]: ‘2017-10-24 17:31:09‘
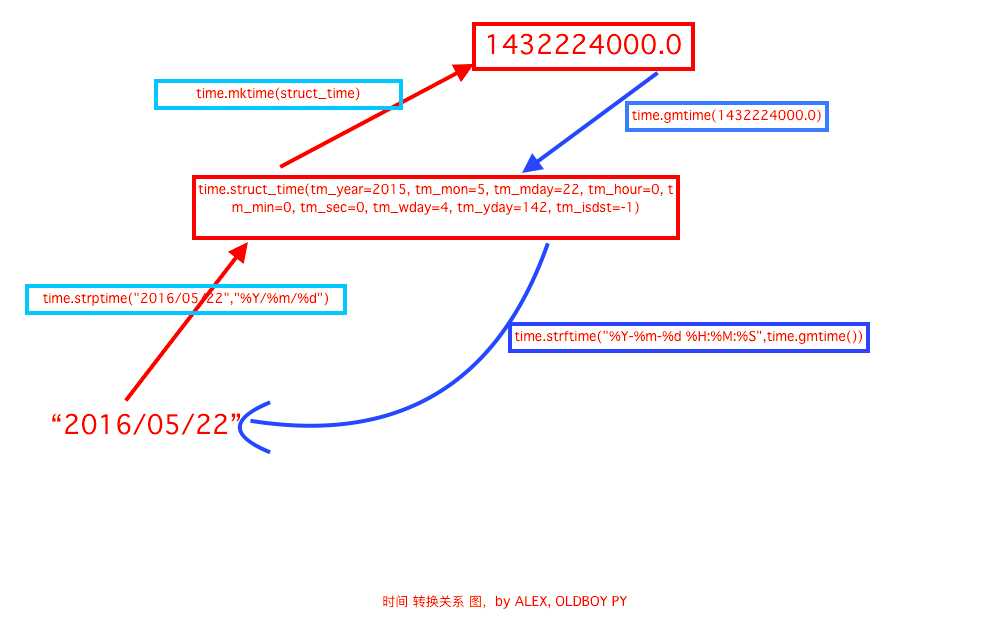
时间戳与字符串形式的时间之间的转换
In [12]: time.strptime("2016-07-05","%Y-%m-%d") #首先自定义一个字符串类型的时间 Out[12]: time.struct_time(tm_year=2016, tm_mon=7, tm_mday=5, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=1, tm_yday=187, tm_isdst=-1) In [13]: t_obj = time.strptime("2016-07-05","%Y-%m-%d") #装换成一个时间对象 In [14]: time.mktime(t_obj) #最后使用mktime装换成时间戳 Out[14]: 1467648000.0 In [2]: t_obj = time.gmtime(time.time() - 86400) #时间对象 In [3]: time.strftime("%Y-%m-%d %H:%M:%S") Out[3]: ‘2017-10-24 18:42:26‘
- 时间戳与字符串形式之间互相转换图
- datetime
In [1]: import datetime In [3]: datetime.datetime.now() #返回当前时间(对象) Out[3]: datetime.datetime(2017, 11, 1, 20, 46, 50, 646785) In [5]: a = datetime.datetime.now() #将当前时间赋值给一个变量 In [6]: a.date() #取变量中的时间 Out[6]: datetime.date(2017, 11, 1) In [7]: a.hour #现在是几点 Out[7]: 20 In [8]: import time In [9]: datetime.date.fromtimestamp(time.time()) #time.time()是一个时间戳,这里就是将时间戳直接转换成时间对象 Out[9]: datetime.date(2017, 11, 1) In [10]: datetime.datetime.now() + datetime.timedelta(2) Out[10]: datetime.datetime(2017, 11, 3, 20, 49, 42, 89591) In [11]: datetime.datetime.now() + datetime.timedelta(minutes=30) #对时间进行加法,这里是加了30分钟 Out[11]: datetime.datetime(2017, 11, 1, 21, 20, 8, 957128) In [14]: time_obj.replace(year=2009) Out[14]: datetime.datetime(2009, 11, 1, 20, 50, 44, 210144) #时间替换将年份替换成2009年,其他不变 """ 其实通过datetime的使用我们也不难发现,datetime中存在的方法time模块中其实都有;我个人观点就是datetime你只需要会replace和datetime.datetime.now()这两个方法就行了,在我们后期的学习中大多数还是使用time模块的。 """
- random模块
random模块是产生随机字符的一个模块,这样明摆着就是打印一个随机字符串,在应用方面可以输出一个验证码;
random.random() #产生一个随机的小数 print(random.randint(1,10)) #产生1~10直接任意的一个数,每次执行代码的时候都会改变 print(random.randrange(1,100,2)) #产生1~10直接的任意一个数不过有间距 a=list(range(10)) print(random.sample(a,2)) #这里第一个数字必须是传一个列表或者元组,然后去a的任意两个数字
- 使用random随机产生验证码
code = "" for i in range(4): current = random.randrange(0,4) if current != i: #i == 0~4 current == 0~4 获取大写的英文字母 temp = chr(random.randint(65,90)) else: #i == 0~4 current == 0~4 获取数字 temp = random.randint(0,9) code += str(temp) print(code)
import random,string a = string.ascii_letters + string.digits # string.ascii_letters获取所有的字母,string.digits获取所有的数字 str_val = random.sample(a,4) "".join(str_val)
- os模块
import os os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.curdir 返回当前目录: (‘.‘) os.pardir 获取当前目录的父目录字符串名:(‘..‘) os.makedirs(‘dirname1/dirname2‘) 可生成多层递归目录 os.removedirs(‘dirname1‘) 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir(‘dirname‘) 生成单级目录;相当于shell中mkdir dirname os.rmdir(‘dirname‘) 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir(‘dirname‘) 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat(‘path/filename‘) 获取文件/目录信息 os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" os.pathsep 输出用于分割文件路径的字符串 os.name 输出字符串指示当前使用平台。win->‘nt‘; Linux->‘posix‘ os.system("bash command") 运行shell命令,直接显示 os.environ 获取系统环境变量 os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os模块补充:
获取当前路径的上级路径:os.path.dirname(os.path.abspath(__file__)) 其中__file__是指运行脚本的绝对路径
路径的拆分:os.path.split(__file__) :拆分后是一个元组
路径的拼接(常用):os.path.join("C:\\","windows","Python27") -- > C:\windows\Python27
- sys模块
#sys 模块很简单,我们只需要记住两个方法就行了 sys.argv #命令行参数List,第一个元素是程序本身路径,第二个就是运行文本后的第一个位置参数 sys.path # 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
- json & pickle 模块
- json和pickle都是用来做序列化和反序列化的,并且用法是一模一样,不同的是两者序列化保存到文件的类容和“兼容性”首先pickle保存到文件不是一个明文的,所以看不出任何东西,而json保存到文件是明文而且能看出数据格式;json接口是可以被任何语言反序列化的,而pickle只可以被Python程序反序列化,这也导致pickle支持Python中所有的数据类型;(可以序列化Python中的函数和类,而json不可以)
import json Leon = { "name":"LeonY", "age":"18", "ha":"CHEN", } #序列化到文件 f = open("filename","w") f.write(json.dumps(Leon)) f.close #反序列化到内存 f = open("filename","r") Leon = json.loads(f) print(Leon["name"]) f.close()
import pickle #序列化保存到文件 Leon = { "name":"LeonY", "age":"18", "ha":"CHEN", } f = open("filename","wb") f.write(pickle.dumps(Leon)) f.close #反序列化到内存 f = open("filename","rb") Leon=pickle.loads(f) print(Leon["name"]) f.close() #这里需要注意pickle不管是在dumps或者是loads的时候都是以bytes的方式去读写,因为Python3 中默认的加载到硬盘中的字符就是bytes格式的
- logging模块
logging模块是专门在程序运行时打印或者输出文件日志的一个模块;logging模块中记录日志分为5中级别:debug,info,warning,error,critical,下面我们看一下logging模块的最基本使用方法
import logging #在屏幕上面打印,并显示日志级别 logging.info("you‘re database xxx table info") logging.critical("you‘re database is down please paolu") #输出至文件中 logging.basicConfig( filename="access.log", #日志文件名 format="%(levelno)s %(asctime)s %(message)s ", #格式化的字符串也就是日志中的格式,-详细信息如下表 datefmt="%Y-%m-%d %H:%M:%S", #格式化时间格式 level=logging.INFO, #最低输出到文件中的日志级别 ) #向文件中输出日志 logging.debug("messge zhongguo haoren ") logging.info("messge meiguo haoren ") logging.error("messge hanguo haoren ") logging.critical("messge riben haoren ")
日志格式
|
%(name)s |
Logger的名字 |
|
%(levelno)s |
数字形式的日志级别 |
|
%(levelname)s |
文本形式的日志级别 |
|
%(pathname)s |
调用日志输出函数的模块的完整路径名,可能没有 |
|
%(filename)s |
调用日志输出函数的模块的文件名 |
|
%(module)s |
调用日志输出函数的模块名 |
|
%(funcName)s |
调用日志输出函数的函数名 |
|
%(lineno)d |
调用日志输出函数的语句所在的代码行 |
|
%(created)f |
当前时间,用UNIX标准的表示时间的浮 点数表示 |
|
%(relativeCreated)d |
输出日志信息时的,自Logger创建以 来的毫秒数 |
|
%(asctime)s |
字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 |
|
%(thread)d |
线程ID。可能没有 |
|
%(threadName)s |
线程名。可能没有 |
|
%(process)d |
进程ID。可能没有 |
|
%(message)s |
用户输出的消息 |
import logging from logging import handlers #创建一个文件对象logger logger = logging.getLogger("TEST-LOG") #TEST-LOG 是输入到全局中的日志名称 logger.setLevel(logging.INFO) #输出到全局中的日志等级 # 创建输出到屏幕上面的log headler ch = logging.StreamHandler() ch.setLevel(logging.DEBUG) #创建输出到日志文件的log headler fh = logging.FileHandler() fh.setLevel(logging.WARNING) #创建日志格式 format_log = logging.Formatter(‘%(asctime)s - %(name)s - %(levelname)s - %(message)s‘) #将ch和fh格式化输出 ch.setFormatter(format_log) fh.setFormatter(format_log) #将ch和fh将入到logger对象中 logger.addHandler(ch) logger.addHandler(fh)
#通常我们在输出到文件日志,都是需要切割的,所以logging模块也提供了相对应的接口 import logging from logging import handlers #创建一个文件对象logger logger = logging.getLogger("TEST-LOG") #TEST-LOG 是输入到全局中的日志名称 logger.setLevel(logging.INFO) #输出到全局中的日志等级 # 创建输出到屏幕上面的log headler ch = logging.StreamHandler() ch.setLevel(logging.DEBUG) #创建输出到日志文件的log headler fh = handlers.TimedRotatingFileHandler("access.log",when="S",interval=5,backupCount=3) #按照时间切割,when默认是按照h(小时)来切割,interval是5s切割一次,backupcont是保留几个,0是无限 #fh = handlers.RotatingFileHandler("access.log",maxBytes=4,backupCount=2)#按照大小切割 fh.setLevel(logging.WARNING) #创建日志格式 format_log = logging.Formatter(‘%(asctime)s - %(name)s - %(levelname)s - %(message)s‘) #将ch和fh格式化输出 ch.setFormatter(format_log) fh.setFormatter(format_log) #将ch和fh将入到logger对象中 logger.addHandler(ch) logger.addHandler(fh)
标签:col .com level read let dex sample 其他 down
原文地址:http://www.cnblogs.com/yanlinux/p/7712749.html
