标签:自动 output ring png 效率 另一个 catch otf 不同
2017-11-05 17:48:17
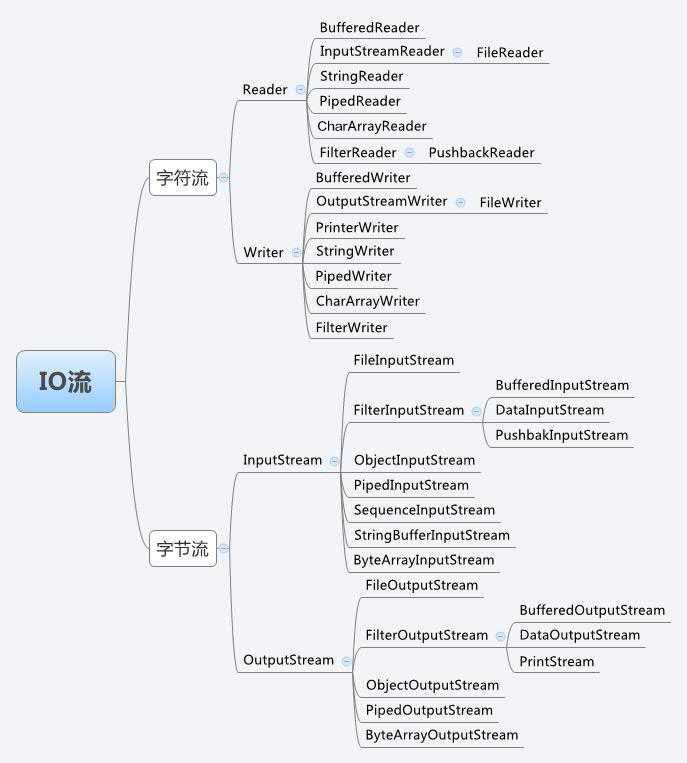
Java中的IO流按数据类型分类分为两种,一是字节流,二是字符流。字符流的出现是为了简化文本数据的读入和写出操作。
如果操作的文件是文本文件,那么使用字符流会大大简化操作,但是如果什么都不知道,就用字节流。
字节流的两个抽象基类是:InputStream
OutputStream
抽象类显然是无法实例化的,所以需要寻找相应的子类来进行操作。下面讨论两个很重要的字节输入输出流子类。
* FileOutputStream
FileOutputStream 用于写入诸如图像数据之类的原始字节的流。要写入字符流,请考虑使用 FileWriter。
**构造方法
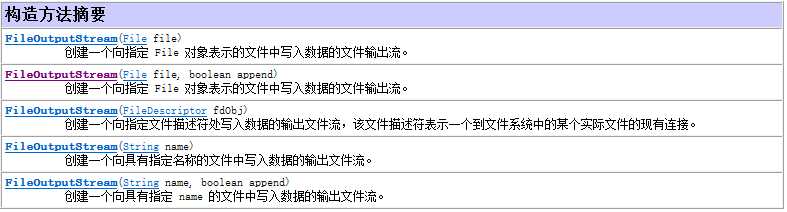
从Api中可以看出,既可以使用File类来初始化,也可以直接使用地址字符串来初始化。
如果文件不存在,会自动新建该文件。
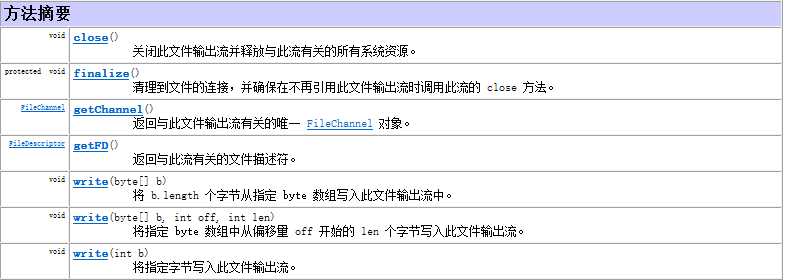
**常用方法
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo1 {
public static void main(String[] args) throws IOException {
FileOutputStream file = new FileOutputStream("E:\\text.txt");
byte[] b = "Hello Spring.\r\n".getBytes();
file.write(b);
file.write("Hello World.".getBytes());
file.close();
}
}
换行符问题:在这里需要注意一个问题,就是换行符的问题。不同系统针对换行符的识别是不同的。
首先解释一下 \r:表示回车
\n:表示换行
高级记事本或者编辑器比如sublime里会自动识别不同的换行符,如果写的\n,在记事本中打开是不显示换行的,但是在sublime中会正常换行。
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo1 {
public static void main(String[] args){
FileOutputStream file = null;
try{
file=new FileOutputStream("E:\\text.txt");
byte[] b = "Hello Spring.\n".getBytes();
file.write(b);
file.write("Hello World.".getBytes());}
catch (FileNotFoundException e)
{
e.printStackTrace();
}
catch (IOException e)
{
e.printStackTrace();
}
finally {
if(file!=null) {
try {
file.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
* FileInputStream
FileInputStream 用于读取诸如图像数据之类的原始字节流。要读取字符流,请考虑使用 FileReader。
**构造方法

**常用方法

如果因为已经到达文件末尾而没有更多的数据,则返回 -1。
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo1 {
public static void main(String[] args) throws IOException {
FileInputStream fin = new FileInputStream("E:\\text.txt");
FileOutputStream fout = new FileOutputStream("E:\\text2.txt");
byte[] b = new byte[5];
int len = 0;
while ((len = fin.read(b)) != -1) {
fout.write(b, 0, len);
}
fin.close();
fout.close();
}
}
返回值为当次读取到的字节数,如果到达文件末尾则返回-1。在写文件的时候,必须使用偏移法进行写入,否则会有覆盖问题。
一般一次读1024或者1024的整数倍,就是一次读1kb或者多kb。
==>显然的,在读写的时候如果使用数组的话,会大大提高效率,所以Java在设计的时候也考虑到了这个问题并提供了
字节缓冲区流:BufferedOutputStream,BufferedInputStream。
* BufferedOutputStream
BufferedOutputStream:该类实现缓冲的输出流。通过设置这种输出流,应用程序就可以将各个字节写入底层输出流中,而不必针对每次字节写入调用底层系统。
**构造方法

构造方法可以指定缓冲区的大小,一般来说使用默认缓冲区大小就够了。
**常用方法

当然也可以直接写byte[] b,指的是把长度为len的字节数组都写入。
* BufferedInputStream
BufferedInputStream 为另一个输入流添加一些功能,即缓冲输入以及支持 mark 和 reset 方法的能力。在创建 BufferedInputStream 时,会创建一个内部缓冲区数组。在读取或跳过流中的字节时,可根据需要从包含的输入流再次填充该内部缓冲区,一次填充多个字节。mark 操作记录输入流中的某个点,reset 操作使得在从包含的输入流中获取新字节之前,再次读取自最后一次 mark 操作后读取的所有字节。
**构造方法

**常用方法

使用Buffered缓冲流在使用的时候和基本的File流没有差异,不过在底层进行了优化,所以导致效率大大提高。
标签:自动 output ring png 效率 另一个 catch otf 不同
原文地址:http://www.cnblogs.com/TIMHY/p/7788048.html