标签:能力 展开 小项目 blank 为我 百度 opencv k-means 根据
前段时间做了一个车型识别的小项目,思路是利用k-means算法以及词袋模型来做的。
近年来图像识别的方法非常非常多,这边只记录一下我那个项目的思路,核心思想是k-means算法和词汇树。
很遗憾没有做详尽的开发前的思路文档,只能按照记忆进行大致总结。
项目分为三大模块:特征点抽取、训练词汇树、识别(利用训练好的词汇树)。
首先是特征点的抽取。我是用的OpenCV的框架来做的特征点抽取。这里提到两种特征点:SURF和SIFT。
关于这两种特征点提取算法,这里做简要介绍(其实我真的不太care,主要是看哪个的特性适合我的项目。单纯为了实现这个东西的话我觉得没必要太深究这个,当然如果你要把这个东西做透了,那肯定得好好研究,毕竟源码来看还是有很多可以优化的东西)。
SIFT特征是图像的局部特征,对平移、旋转、尺度缩放、亮度变化、遮挡和噪声等具有良好的不变性,对视觉变化、仿射变换也保持一定程度的稳定性。SIFT算法时间复杂度的瓶颈在于描述子的建立和匹配 ,如何优化对特征点的描述方法是提升SIFT效率的关键。
SURF算法的优点是速度远快于SIFT且稳定性好;在时间上,SURF运行速度大约为SIFT的3倍;在质量上,SURF的鲁棒性很好,特征点识别率较SIFT高,在视角、光照、尺度变化等情形下,大体上都优于SIFT。
这里要提到的一点就是SURF是64维的特征描述子,而SIFT是128维的特征描述子,简单点数说就是SIFT是X=(x1,x2,x3,...,x128)。而SURF是Y=(y1,y2,y3,...,y64)。从做k-means聚类的角度上来说我果断选择了SURF算法来提取(不过因为用的是OpenCV框架,所以几句代码的事。再提一句,OpenCV框架不止C有,Java也有,喜欢Java不喜欢C/C++的朋友可以尝试,我就是用的java代码)。
简单点说一幅图就是由N多个SURF特征点构成的,有点像像素点。每一个SURF特征点是一个64维的向量Y=(y1,y2,y3,...,y64),就像像素一样,一张图不也是由很多很多个像素点组成的吗,每一个像素点是一个三维向量(x,y,z),其中x,y,z都在0到255之间。
首先是SURF特征点的抽取,我们采用OpenCV框架来抽取每一张图的SURF特征点(当时大约10000张图),将所有图中抽出的SURF特征点都放在一起,形成一个特征点“池塘”,有大概几十亿个特征点。
第二步是词汇树的训练。我们把这个词汇树定义为一个深层次的二叉树,那么这个二叉树如何生成呢,这里首先要提到k-means聚类算法:
k-means聚类算法是一类无监督机器学习的算法。至于什么是机器学习,什么是有监督学习和无监督学习,这里简单介绍,具体可以查百度。
机器学习是一类算法的总称,通俗点来讲就是想让机器通过学习来拥有智慧(拥有决策能力),这和大多数的基本算法其实没啥区别,这里还要提到一点就是基于时代的背景,当下机器学习大势是在统计学习上的,至于什么是统计学习,什么是符号学习,这个是机器学习的一个发展史相关的东西,可以百度。也就是说我们根据现有的一些数据,通过一些手段来分析,能够得到一个决策的方法,来了一个新的数据我就知道该干什么(这跟我们人类的思维过程是一样的,我们也是小的时候学到了很多东西,后来遇到一件新的事情之后呢我们就能根据以往的经验来做出决策)。
有监督学习和无监督学习是机器学习中的两个大类,有监督学习是说我给定的一大堆数据,是人为标注好哪些数据属于哪一类的。而无监督学习是指我事先不加以人工干预,单纯凭借这一大批数据来进行一个分类或者说预测。
k-means算法的大致步骤,这里我用二维坐标系中的点的聚类来形象地表示:
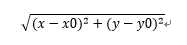
(不好意思自己弄得公示有点丑),(x0,y0)即质心。
从网上贴张图来表示k-means聚类的过程:
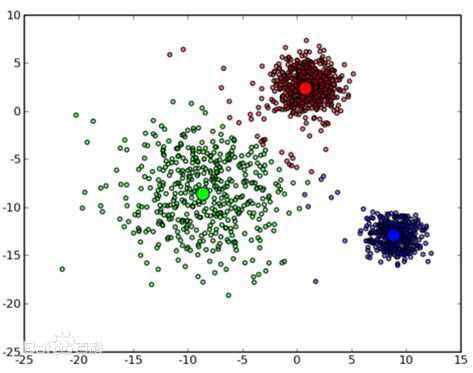
这是一种比较形象的聚类。可以看到图中三类点被聚到了3类中。
那么对于我们项目中的SURF特征点的聚类,实际上和上面提到的二维点聚类是一样的,只不过我们现在是一个64维的坐标系,每一个点是一个64维向量X=(x1,x2,x3,...,x64)
而计算距离就是变成了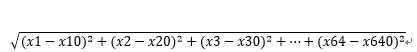 。而质心的坐标就是(x10,x20,x30,...,x640)。
。而质心的坐标就是(x10,x20,x30,...,x640)。
接下来就是建立二叉树的过程了,首先我们有一个根结点。我们对于那么多的特征点利用k-means算法分成两类。那么根结点的左右子树分别是我们分好类的A类和B类。紧接着,对于左右子树,我们分别对A类再分成A1,A2两类作为左子树的左右子树;对B类在分成B1,B2两类作为右子树的左右子树,一直迭代,直到迭代到我们需要的层数。我当时定了32层,于是在叶子节点处就有2^31个叶子节点,即有2^31类。然后对每一个叶子节点给一个符号。现在词汇树就建立完成了。
接下来就是图像识别。
现在我的词汇树已经训练完成,那么我要对我数据库里面的10000张图片做一个调整,毕竟图片是没啥东西可以抽取的,我们要转换成别的形式。于是我们数据库里的每一张图,现在我们来走一遍这个二叉树,就能将一张图片转化为一段文本。具体过程:遍历每一个SURF特征点,然后比较和A1,A2类哪个接近(用欧氏距离),假设离A1近,然后再到A1子树里,比较和A1的左子树,A1的右子树哪个近……就这样一直比较到最终的叶子节点,然后就把这个SURF特征点转化为一个符号(也就是一个文字)。接着我么把所有的数据库中的图片全部转化为文字。
然后我们再进一步转化,可以把一张图转化成一个多维向量!这个利用到文本挖掘里面的一点知识,大家可以自行百度,简单说就是由好多好多文本(每一段文本由不同的符号组成,相当于普通文本,每一段文本由不同的词组成嘛),然后选出一系列具有代表性的词(我们不需要选,因为我们只有2^31个词!那么就能转化成2^31维的向量)。
紧接着我们拍到了一张新的汽车的图片,我们利用相似的过程将一个新的汽车的图片转化成一个2^31维向量,然后根据已有的数据来匹配,最接近哪些车型?这个过程其实有很多办法,这里不详细展开了,最简单的一种办法就是像刚刚一样计算欧氏距离。
那么整个识别过程到这里就介绍完了,当中其实还有很多坑,比如说拍的汽车图片,周围是有很多背景的,在提取SURF特征点过程中,如何防止这些无用的背景的干扰,还有可否拍摄视频来识别?等等有很多问题需要解决,也有很多方法,就不在本文中描述了。
标签:能力 展开 小项目 blank 为我 百度 opencv k-means 根据
原文地址:http://www.cnblogs.com/zhouxiaosong/p/7707479.html