标签:price 返回 sleep end 数据库查询 soap pytho rand 优点
例:做一包子吃一个包子
优点:更省内存。
以上例子的原理: 重点★★★★★
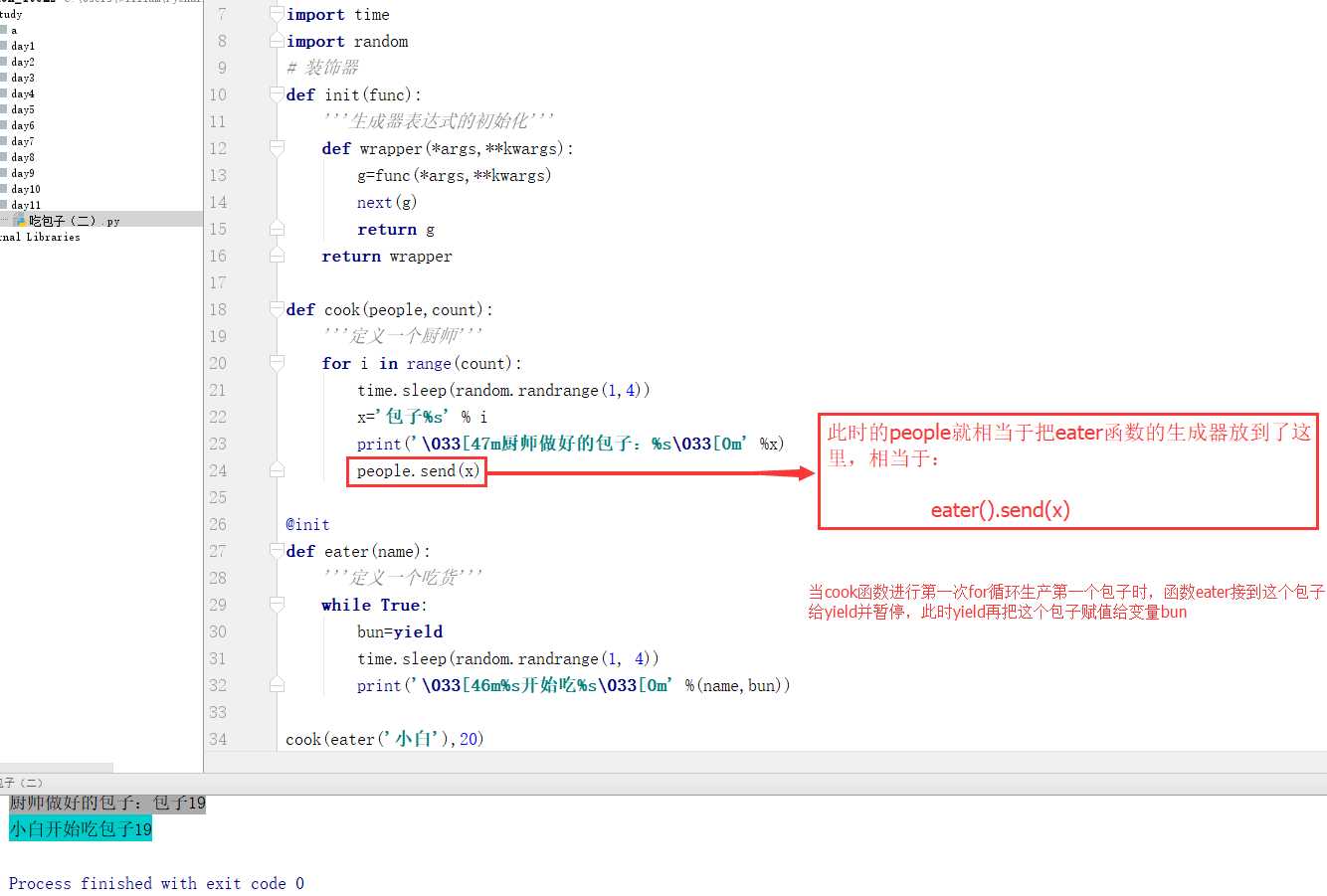
源代码:
import time
import random
# 装饰器
def init(func):
‘‘‘生成器表达式的初始化‘‘‘
def wrapper(*args,**kwargs):
g=func(*args,**kwargs)
next(g)
return g
return wrapper
def cook(people,count):
‘‘‘定义一个厨师‘‘‘
for i in range(count):
time.sleep(random.randrange(1,4))
x=‘包子%s‘ % i
print(‘\033[47m厨师做好的包子:%s\033[0m‘ %x)
people.send(x)
@init
def eater(name):
‘‘‘定义一个吃货‘‘‘
while True:
bun=yield
time.sleep(random.randrange(1, 4))
print(‘\033[46m%s开始吃%s\033[0m‘ %(name,bun))
cook(eater(‘小白‘),20)
例:
要求:求一个商品文件中所有物品的价格总和
有一个记载了商品的.txt文件,里面的内容如下:

代码如下:
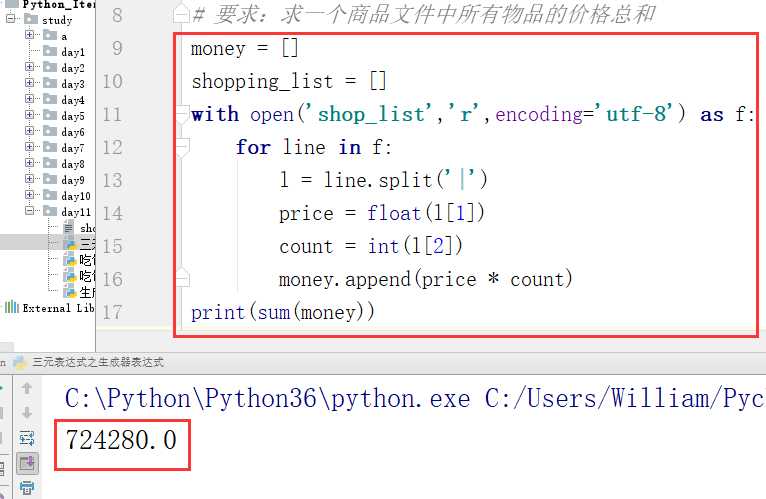
以上代码太长,这里用三元表达式中的列表解析来精简代码,但是列表解析是把文件内容都放到内存空间,会造成占用过多内存。所以最好是用生成器表达式,一来精简代码,二来节省内存。
代码如下:
money = []
with open(‘shop_list‘,‘r‘,encoding=‘utf-8‘) as f:
t = (float(line.split(‘|‘)[1]) * int(line.split(‘|‘)[2]) for line in f)
print(sum(t))
输出结果:
724280.0
要求:把第2小点中的例子中的数据取出来,拼接成一个有结构一样的数据,类似数据库的查询功能
分析:把所以数据查出来,它们只是一串字符串,然后把这些字符串拼接成一个字典的形式,这样我们就能通过键找到相对应的值了。
商品列表如下:
代码如下:
goods_info = [] # 用来存放所有的商品,每件商品以字典的形式存放
with open(‘shop_list‘,‘r‘,encoding=‘utf-8‘) as f:
goods_info = [{‘name‘:line.split(‘|‘)[0],‘price‘:line.split(‘|‘)[1],‘count‘:line.split(‘|‘)[2]} for line in f]
print(goods_info)
输出结果:

[{‘name‘: ‘apple‘, ‘price‘: ‘3.2‘, ‘count‘: ‘1000‘}, {‘name‘: ‘banana‘, ‘price‘: ‘1.8‘, ‘count‘: ‘600‘}, {‘name‘: ‘ipad‘, ‘price‘: ‘4000‘, ‘count‘: ‘100‘}, {‘name‘: ‘macbook pro‘, ‘price‘: ‘10000‘, ‘count‘: ‘30‘}, {‘name‘: ‘soap‘, ‘price‘: ‘2‘, ‘count‘: ‘10000‘}]
将要求更改:只取价格大于等于4000的商品。
代码如下:
goods_info = [] # 用来存放所有的商品,每件商品以字典的形式存放
with open(‘shop_list‘,‘r‘,encoding=‘utf-8‘) as f:
goods_info = [{‘name‘:line.split(‘|‘)[0],‘price‘:float(line.split(‘|‘)[1]),‘count‘:int(line.split(‘|‘)[2])} for line in f if float(line.split(‘|‘)[1]) >= 4000]
print(goods_info)
输出结果:
[{‘name‘: ‘ipad‘, ‘price‘: 4000.0, ‘count‘: 100}, {‘name‘: ‘macbook pro‘, ‘price‘: 10000.0, ‘count‘: 30}]
之前学过的函数都是有函数名的,该函数名是用于绑定值的,与变量名的定义类似,当创建一个函数时,此时函数名绑定了一个值,这个值的引用计数器则加1,一旦没有函数名来引用这个值了,这个值将会被python的内存回收机制给回收。但是匿名函数除外。
(1)没有函数名
(2)函数参数的命名规则与有名函数是一样的。
(3)定义形参时直接写参数名且不用加上括号
(4)一行代码即可完成创建函数
(5)自带return效果,所以一定有返回值
(6)定义完后就会被python内存回收机制回收
lambda 函数的参数 :函数体 # 匿名函数的函数体就相当于有名函数的retturn返回值。
有时我们只需要用一次函数时,且不想清理有名函数时便可以用到此匿名函数。
Python基础第十一天——内置函数的补充、内置函数与lambda、递归
标签:price 返回 sleep end 数据库查询 soap pytho rand 优点
原文地址:http://www.cnblogs.com/xiaoxiaobai/p/7811157.html
