标签:bytes sign head erro 找不到 rip 信息 tmpfs red
前天外面出差大数据测试环境平台有7台服务器挂了,同事重启好了五台服务器,但是还有两台服务器启动不起来,第二天回来后我和同事再次去机房检查,发现两台服务器都显示superblock的报错,经过一番处理后两台服务器都正常进系统了,现决定重现superblock故障并将此类问题故障处理思路写下来方便后面新同事参考。
硬盘的物理结构侧视图和俯视图,这两张图传递出来的比较重要的信息如下:
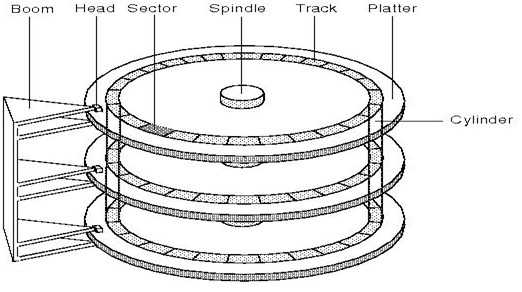
磁盘划分为磁头(Head),柱面(Cylinder),扇区(Sector)
磁头:每个磁片正反两面各有一个磁头,磁头固定在可移动的机械臂上,用于读写数据
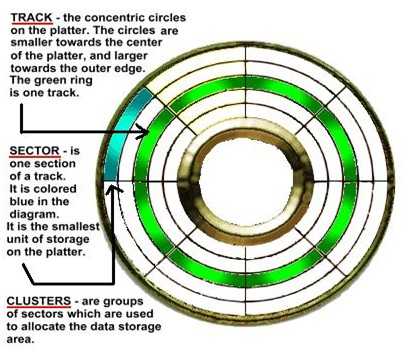
磁道:当硬盘盘片旋转时,磁头若保持在一个位置上,则磁头会在盘片表面划出一个圆形轨迹,这些圆形轨迹就叫做磁道,磁道由外向内从0开始编号。
柱面:磁片中半径相同的同心磁道(Track)构成柱面。在实际应用中经常用到的磁盘分区就是用它作为范围划分的(重要)。
扇区:每个磁道上的一个弧段被成为一个扇区,它是硬盘的最小组成单元,一般扇区的大小是512字节。
了解了这几个概念就能算出一个分区的大小
硬盘容量:磁头数*柱面数*扇区数*512
磁盘sda的容量是: 255 * 2610 * 63 * 512 = 21467980800 ,算出的容量跟系统显示的基本一致。
[root@server1 ~]# fdisk -l Disk /dev/sda: 21.5 GB, 21474836480 bytes 255 heads, 63 sectors/track, 2610 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x000205e3 Device Boot Start End Blocks Id System /dev/sda1 * 1 26 204800 83 Linux Partition 1 does not end on cylinder boundary. /dev/sda2 26 2611 20765696 8e Linux LVM Disk /dev/sdb: 10.7 GB, 10737418240 bytes 255 heads, 63 sectors/track, 1305 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x00000000
由于Linux系统是多用户多的。从ext2开始,将磁盘分区格式化后是将文件属性和文件内容分开存储的,分别由inode和block来负责。
用于存储文件的各属性,包括:
- 所有者信息:文件的owner,group;
- 权限信息:read、write和excite;
-时间信息:建立或改变时间(ctime)、最后读取时间(atime)、最后修改时间(mtime);
- 标志信息:一些flags;
- 内容信息:type,size,以及相应的block的位置信息。
注意:不记录文件名或目录名,文件名或目录名记录在文件所在目录对应的block里。
inode的大小一般是12Bytes,也可能是256 Bytes.
用于存储文件的内容,它的大小一般是1K,2K,4K,一般在磁盘格式化的时候就默认了。
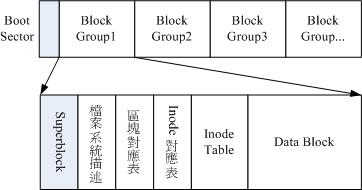
因为现在的磁盘都比较大,对其进行格式化后inode和block的个数将会非常大,为了便于管理,ext4文件系统在格式化的时候基本上是区分为多个区块群组(block group),这个跟军队里层级划分很像哦.
ext4文件系统格式化后的划分是下面这样的。
Boot Sector 是用于引导分区上的操作系统的,这个一般用在双系统上,这里就直接忽略了。
Block Group 为了便于管理,文件系统格式化的时候划分为了多个区块群组,它里面保存了以下内容:
Superblock 是记录整个 filesystem 相关信息的地方.为了系统的健壮性,最初每个块组都有超级块和组描述符表的一个拷贝,但是当文件系统很大时,这样浪费了很多块(尤其是组描述符表占用的块多),后来采用了一种稀疏的方式来存储这些拷贝,只有块组号是3, 5 ,7的幂的块组(譬如说1,3,5,7,9,25,49…)才备份这个拷贝。通常情况下,只有主拷贝(第0块块组)的超级块信息被文件系统使用,其它拷贝只有在主拷贝被破坏的情况下才使用,他记录的信息主要有:
block 与 inode 的总量;
这个区段可以描述每个 block group 的开始与结束的 block 号码,以及说明每个区段 (superblock, bitmap, inodemap, data block) 分别介于哪一个 block 号码之间.
区块对应表用于描述该块组所管理的块的分配状态。如果某个块对应的位未置位,那么代表该块未分配,可以用于存储数据;否则,代表该块已经用于存储数据或者该块不能够使用(譬如该块物理上不存在)。由于区块位图仅占一个块,因此这也就决定了块组的大小。
Inode位图用于描述该块组所管理的inode的分配状态。我们知道inode是用于描述文件的元数据,每个inode对应文件系统中唯一的一个号,如果inode位图中相应位置位,那么代表该inode已经分配出去;否则可以使用。由于其仅占用一个块,因此这也限制了一个块组中所能够使用的最大inode数量。
Inode表用于存储inode信息。它占用一个或多个块(为了有效的利用空间,多个inode存储在一个块中),其大小取决于文件系统创建时的参数,由于inode位图的限制,决定了其最大所占用的空间。
数据块存放真正的文件数据
现在回过头来观察自己的文件系统,每个区段与superblock的信息都可以使用dumpe2fs这个命令来查询
[root@server1 ~]# dumpe2fs /dev/sdb|more dumpe2fs 1.41.12 (17-May-2010) Filesystem volume name: <none> ---------->> 文件系统的名称 Last mounted on: <not available> -------------------------------->> 分区挂载,当前没有挂载,所以显示不可用 Filesystem UUID: c6421bf7-8497-45c0-86b0-dfac1b21989a Filesystem magic number: 0xEF53 Filesystem revision #: 1 (dynamic) Filesystem features: has_journal ext_attr resize_inode dir_index filetype extent flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize ----------->> 文件系统的一些特性 Filesystem flags: signed_directory_hash Default mount options: (none) Filesystem state: clean ----------->> 文件系统当前是好的(clean) Errors behavior: Continue Filesystem OS type: Linux Inode count: 655360 -------->> Inode 总的个数 Block count: 2621440 --------->> Block 总的个数 Reserved block count: 131072 Free blocks: 2541777 --------->> 空闲的block个数 Free inodes: 655349 ----------->> 空闲的inode个数 First block: 0 ------------->>第一个block的编号 Block size: 4096 --------------->> block的大小,这里是4K Fragment size: 4096 Reserved GDT blocks: 639 Blocks per group: 32768 ------------------->> 每个块组block的个数 Fragments per group: 32768 Inodes per group: 8192 ------------>> 每个块组inode的个数 Inode blocks per group: 512 Flex block group size: 16 Filesystem created: Sat Nov 11 13:23:30 2017 Last mount time: n/a Last write time: Sat Nov 11 13:23:32 2017 Mount count: 0 Maximum mount count: 33 Last checked: Sat Nov 11 13:23:30 2017 Check interval: 15552000 (6 months) Next check after: Thu May 10 13:23:30 2018 Lifetime writes: 291 MB Reserved blocks uid: 0 (user root) Reserved blocks gid: 0 (group root) First inode: 11 Inode size: 256 ------------>> inode的大小 Required extra isize: 28 Desired extra isize: 28 Journal inode: 8 Default directory hash: half_md4 Directory Hash Seed: 2fd3813e-6245-4a62-bc28-34c1534c919d Journal backup: inode blocks Journal features: (none) 日志大小: 128M Journal length: 32768 Journal sequence: 0x00000001 Journal start: 0 Group 0: (Blocks 0-32767) [ITABLE_ZEROED] 校验和 0xee7f,8181个未使用的inode 主 superblock at 0, Group descriptors at 1-1 -------------->> 主superblock的位置在编号为0的block中 保留的GDT块位于 2-640 Block bitmap at 641 (+641), Inode bitmap at 657 (+657) Inode表位于 673-1184 (+673) 23897 free blocks, 8181 free inodes, 2 directories, 8181个未使用的inodes 可用块数: 8871-32767 可用inode数: 12-8192 Group 1: (Blocks 32768-65535) [INODE_UNINIT, ITABLE_ZEROED] 校验和 0x1ae3,8192个未使用的inode 备份 superblock at 32768, Group descriptors at 32769-32769 ------------->> 备份superblock的位置在编号为 32768 的block中 保留的GDT块位于 32770-33408 Block bitmap at 642 (+4294935170), Inode bitmap at 658 (+4294935186) Inode表位于 1185-1696 (+4294935713) 32127 free blocks, 8192 free inodes, 0 directories, 8192个未使用的inodes 可用块数: 33409-65535 可用inode数: 8193-16384 Group 2: (Blocks 65536-98303) [INODE_UNINIT, BLOCK_UNINIT, ITABLE_ZEROED] 校验和 0x8b39,8192个未使用的inode Block bitmap at 643 (+4294902403), Inode bitmap at 659 (+4294902419) Inode表位于 1697-2208 (+4294903457) 32768 free blocks, 8192 free inodes, 0 directories, 8192个未使用的inodes 可用块数: 65536-98303 可用inode数: 16385-24576 Group 3: (Blocks 98304-131071) [INODE_UNINIT, ITABLE_ZEROED] 校验和 0x6c3d,8192个未使用的inode 备份 superblock at 98304, Group descriptors at 98305-98305 保留的GDT块位于 98306-98944 Block bitmap at 644 (+4294869636), Inode bitmap at 660 (+4294869652) Inode表位于 2209-2720 (+4294871201) 32127 free blocks, 8192 free inodes, 0 directories, 8192个未使用的inodes 可用块数: 98945-131071 可用inode数: 24577-32768
说到这里心里大概有谱了,原来superblock在文件系统上是有备份的,那我们模拟下主superblock出问题,看如何恢复
这里直接利用dd命令将sdb磁盘第一个block的内容抹除
[root@server1 ~]# dd if=/dev/zero of=/dev/sdb bs=1 count=4096 记录了4096+0 的读入 记录了4096+0 的写出 4096字节(4.1 kB)已复制,0.019493 秒,210 kB/秒 [root@server1 ~]# dumpe2fs /dev/sdb dumpe2fs 1.41.12 (17-May-2010) dumpe2fs: Bad magic number in super-block 当尝试打开 /dev/sdb 时 找不到有效的文件系统超级块. [root@server1 ~]# tune2fs -l /dev/sdb tune2fs 1.41.12 (17-May-2010) tune2fs: Bad magic number in super-block 当尝试打开 /dev/sdb 时 找不到有效的文件系统超级块. [root@server1 ~]#
这时候我们根本无法从dumpe2fs和tune2fs看到Backup superblock的位置,都找不到superblock备份的位置该怎么恢复主superblock呢
注意下面的命令都是针对ext类文件系统的,其它文件系统不适用
首先要找到superblock备份的几个位置,这需要利用mke2fs这个命令
mke2fs:create an ext2/ext3/ext4 filesystem
利用mke2fs这个命令 mke2fs -n 设备名,为了不引起歧义,所以这里直接复制了原文解释。
-n Causes mke2fs to not actually create a filesystem, but display what it would do if it were to create
a filesystem. This can be used to determine the location of the backup superblocks for a particular
filesystem, so long as the mke2fs parameters that were passed when the filesystem was originally
created are used again. (With the -n option added, of course!)
简单来说就是接了-n 参数 ,mke2fs 不是真的在设备上创建文件系统,它只是模拟这个过程并显示给你看。让你明白它究竟做了那些事。
[root@server1 ~]# mke2fs -n /dev/sdb mke2fs 1.41.12 (17-May-2010) /dev/sdb is entire device, not just one partition! 无论如何也要继续? (y,n) y 文件系统标签= 操作系统:Linux 块大小=4096 (log=2) 分块大小=4096 (log=2) Stride=0 blocks, Stripe width=0 blocks 655360 inodes, 2621440 blocks 131072 blocks (5.00%) reserved for the super user 第一个数据块=0 Maximum filesystem blocks=2684354560 80 block groups 32768 blocks per group, 32768 fragments per group 8192 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632 --------------->>> 超级块的备份位置就在这里 [root@server1 ~]#
利用上面的命令就可以找到超级块的备份位置了。然后我们就可以再利用系统提供的另一个磁盘命令e2fsck命令进行恢复,它有一个-b选项,由于我的操作系统是ext4格式的,也可以用fsck.ext4 -b 32768 /dev/sdb,效果一样。
恢复的命令格式: e2fsck –b superblock device
-b superblock
Instead of using the normal superblock, use an alternative superblock specified by superblock. This
option is normally used when the primary superblock has been corrupted. The location of the backup
superblock is dependent on the filesystem’s blocksize. For filesystems with 1k blocksizes, a backup
superblock can be found at block 8193; for filesystems with 2k blocksizes, at block 16384; and for
4k blocksizes, at block 32768.
Additional backup superblocks can be determined by using the mke2fs program using the -n option to
print out where the superblocks were created. The -b option to mke2fs, which specifies blocksize
of the filesystem must be specified in order for the superblock locations that are printed out to be
accurate.
If an alternative superblock is specified and the filesystem is not opened read-only, e2fsck will
make sure that the primary superblock is updated appropriately upon completion of the filesystem
check.
[root@server1 ~]# e2fsck -b 32768 /dev/sdb e2fsck 1.41.12 (17-May-2010) /dev/sdb was not cleanly unmounted, 强制检查. 第一步: 检查inode,块,和大小 第二步: 检查目录结构 第3步: 检查目录连接性 Pass 4: Checking reference counts 第5步: 检查簇概要信息 /dev/sdb: ***** 文件系统已修改 ***** /dev/sdb: 11/655360 files (0.0% non-contiguous), 79663/2621440 blocks [root@server1 ~]# dumpe2fs /dev/sdb|more dumpe2fs 1.41.12 (17-May-2010) Filesystem volume name: <none> Last mounted on: <not available> Filesystem UUID: c6421bf7-8497-45c0-86b0-dfac1b21989a Filesystem magic number: 0xEF53 Filesystem revision #: 1 (dynamic) Filesystem features: has_journal ext_attr resize_inode dir_index filetype extent flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize Filesystem flags: signed_directory_hash Default mount options: (none) Filesystem state: clean Errors behavior: Continue Filesystem OS type: Linux Inode count: 655360 Block count: 2621440 Reserved block count: 131072 Free blocks: 2541777 Free inodes: 655349 First block: 0 Block size: 4096 Fragment size: 4096 Reserved GDT blocks: 639 Blocks per group: 32768 Fragments per group: 32768 Inodes per group: 8192 Inode blocks per group: 512 Flex block group size: 16 Filesystem created: Sat Nov 11 13:23:30 2017 Last mount time: n/a Last write time: Sat Nov 11 16:57:39 2017 Mount count: 0 Maximum mount count: 33 Last checked: Sat Nov 11 16:57:39 2017
现在主超级块已经恢复了,系统可以正常使用。
那如果档案系统描述(GDT)损坏了怎么办,这里也可以试验下:
这里块组1的组描述符是在第二个块的,直接利用dd覆盖第二个块,可以看到现在磁盘已经无法进行挂载了。并且系统提示组块0有错误。
[root@server1 /]# dd if=/dev/zero of=/dev/sdb bs=1 count=4096 seek=4096 记录了4096+0 的读入 记录了4096+0 的写出 4096字节(4.1 kB)已复制,0.0795117 秒,51.5 kB/秒 [root@server1 /]# mount /dev/sdb /data/ mount: wrong fs type, bad option, bad superblock on /dev/sdb, missing codepage or helper program, or other error In some cases useful info is found in syslog - try dmesg | tail or so [root@server1 /]# dmesg |tail -5 EXT4-fs (sdb): mounted filesystem with ordered data mode. Opts: EXT4-fs (sdb): ext4_check_descriptors: Checksum for group 0 failed (43116!=0) EXT4-fs (sdb): group descriptors corrupted! EXT4-fs (sdb): ext4_check_descriptors: Checksum for group 0 failed (43116!=0) EXT4-fs (sdb): group descriptors corrupted! [root@server1 /]#
组描述错误可以直接利用fsck –y device设备名来进行修复,修复好后就能正常挂载 。
[root@server1 /]# fsck -y /dev/sdb fsck from util-linux-ng 2.17.2 e2fsck 1.41.12 (17-May-2010) fsck.ext4: Group descriptors look bad... trying backup blocks... /dev/sdb was not cleanly unmounted, 强制检查. 第一步: 检查inode,块,和大小 第二步: 检查目录结构 第3步: 检查目录连接性 Pass 4: Checking reference counts 第5步: 检查簇概要信息 Free 块s count wrong for 簇 #48 (24544, counted=24543). 处理? 是 Free 块s count wrong (2541777, counted=2541776). 处理? 是 Free inodes count wrong for 簇 #48 (8192, counted=8191). 处理? 是 Directories count wrong for 簇 #48 (0, counted=1). 处理? 是 Free inodes count wrong (655349, counted=655348). 处理? 是 /dev/sdb: ***** 文件系统已修改 ***** /dev/sdb: 12/655360 files (0.0% non-contiguous), 79664/2621440 blocks [root@server1 /]# mount /dev/sdb /data/ [root@server1 /]# df -lh Filesystem Size Used Avail Use% Mounted on /dev/mapper/VolGroup-LogVol01_root 9.9G 4.3G 5.1G 46% / tmpfs 491M 32K 491M 1% /dev/shm /dev/sda1 194M 35M 150M 19% /boot /dev/mapper/VolGroup-LogVol02_home 7.7G 149M 7.2G 2% /home /dev/sdb 9.9G 151M 9.2G 2% /data [root@server1 /]#
标签:bytes sign head erro 找不到 rip 信息 tmpfs red
原文地址:http://www.cnblogs.com/kl876435928/p/7819565.html