标签:count 字段 alt mysql tab 用户表 http log 排序
首先 索引长度和区分度是相互矛盾的,
索引长度太短,那么区分度就很低,吧索引长度加长,区分度就高,但是索引也是要占内存的,所以我们需要找到一个平衡点;
那么这个平衡点怎么来定?
比如用户表有个字段 username ,要给他加索引,问题是索引长度多少合适?
其实我们知道 百家姓里面有百多个姓 ,但是大多数人的姓 集中在前十多个;如果我设置索引索引长度为1,对染占内存少,但是区分度低,
区分度低索引的效率越低。太长则占内存;
首先你要知道 mysql的索引都是排好序的。如果区分度高排序越快,区分度越低,排序慢;
举个例子: (张,张三,张三哥),如果索引长度取1的话,那么每一行的索引都是 张 这个字,完全没有区分度,你让他怎么排序?结果这样三行完全是随机排的,因为索引都一样;
如果长度取2,那么排序的时候至少前两个是排对了的,如果取3,区分度达到100%,排序完全正确;
等等,那你说是不是索引越长越好? 答案肯定是错的,比如 (张,李,王) 和 (张三啦啦啦,张三呵呵呵,张三呼呼呼);前者在内存中排序占得空间少,排序也快,后者明显更慢更占内存,在大数据应用中这一点点都是很恐怖的;
所以要做一个取舍;这个取舍不是没有一个固定的量;需要跟你自己的数据库里面的数据来判断;比较常规的公式是:
test是要加索引的字段,5是索引长度,
select count(distinct left(test,5))/count(*) from table;
求出一个浮点数,这个浮点数是逐渐趋向1的,网上找了个图片来分析下;
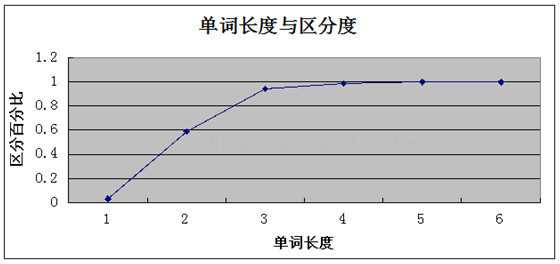
这个地方观察到,当索引长度达到4的时候就已经趋向1了,所以长度设为4是最佳的,在大点增加的索引效果已经很小了,这个地方不是说必须接近1才行;
其实这个值达到0.1就已经可以接受了;总之要找一个平衡点;
还有一些特殊的字段常规方法用起不太顺畅,比如有一个url字段,绝大部分的url都是 http://www. 开头的
这种情况下索引长度取取到11都是无效的,需要更长的索引,那么有没有优雅的方式来解决呢;
第一种方法: 可以将数据倒序存入数据库;
第二种方法:对字符串进行crc32哈希处理;
两种方法都不错,当然要配合客户端程序完成;
标签:count 字段 alt mysql tab 用户表 http log 排序
原文地址:http://www.cnblogs.com/zox2011/p/7822791.html