标签:报错 编码转换 你好 nbsp 级别 过程 就会 不能 添加
一提到编码,我们脑子里就会想到unicode, utf-8 ,gbk 等类型的编码。
但事实上,unicode和utf-8,gbk并不是同一级别的代码。
python3中,unicode是内存里统一使用的编码,内存里所有的数据(比如str对象)都是用unicode编码的。
 可以看到,添加u前缀以后,str对象没变化,说明原本就是unicode
可以看到,添加u前缀以后,str对象没变化,说明原本就是unicode
从unicode编码转换成别的类型的编码,这个过程叫编码 (encode)
从别的类型的编码转换为unicode,这个过程叫解码 (decode)
由此你可以想到,str对象没有decode方法,因为unicode不能再解码了。
同样的,byte对象没有encode方法。
下图中,‘\xe4\xbd\xa0\xe5\xa5\xbd’是中文‘你好’的utf-8编码。
但是,如果我们在这段代码前面不加前缀b,python就会把它当字符串看待,也就是unicode
我们说过,unicode没有decode方法,所以python报错了。

我们在前面加上前缀b以后,python就会把str转换成byte,这样就可以调用decode属性了。
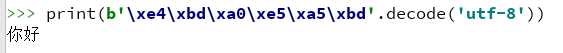
标签:报错 编码转换 你好 nbsp 级别 过程 就会 不能 添加
原文地址:http://www.cnblogs.com/ShiveryMoon/p/7823218.html