标签:链表 数组 idt 增加 聚集 hash冲突 hash函数 应该 了解
一、前序
前几篇文章我结合数据结构说了一些常用的集合,但是我感觉那样可能不系统,于是乎想着重写,按照由整体到细节的方式去写,这样才能更好的把握集合,废话不多说开始吧;
二、集合框架
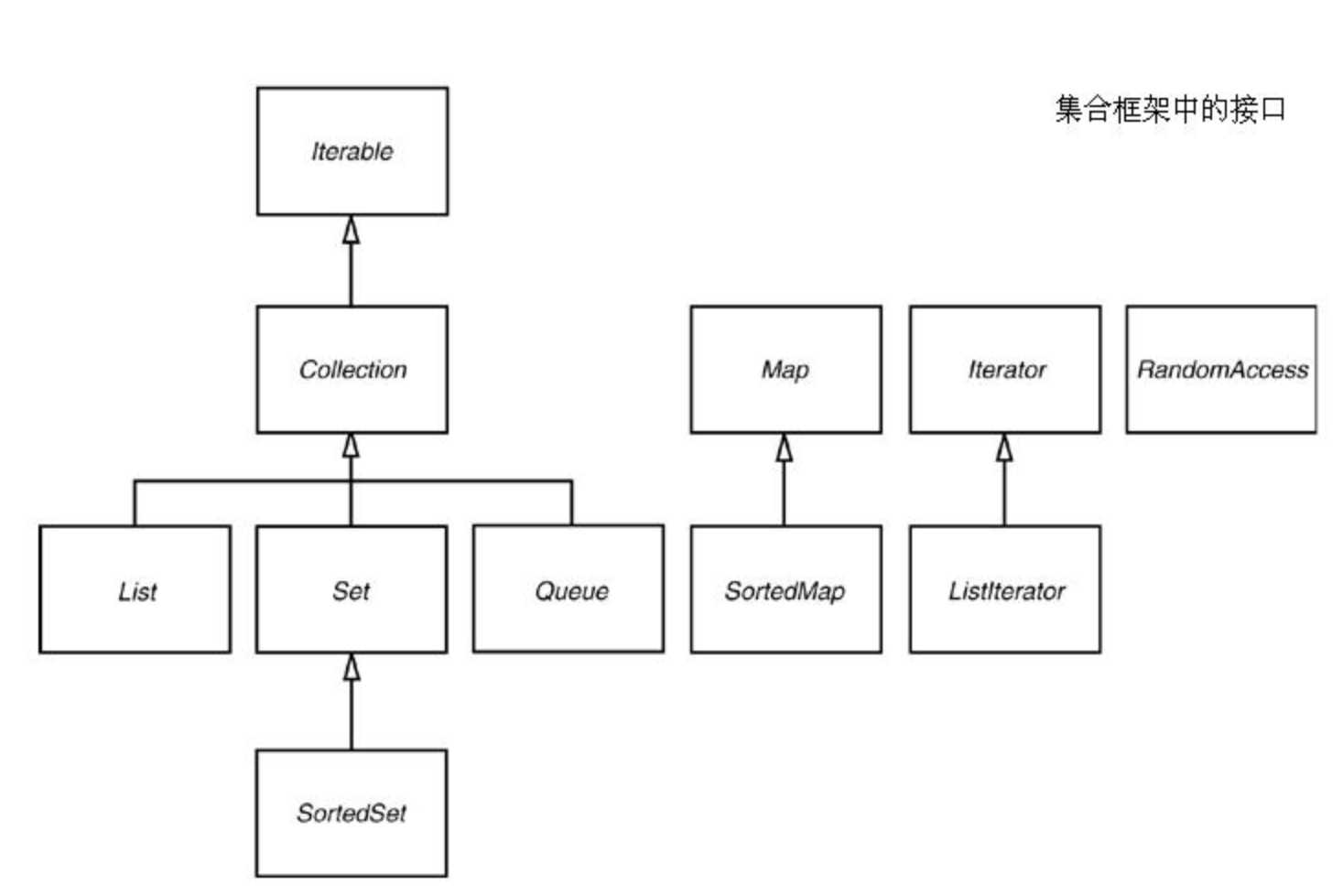
上面这副图是集合框架中的基本接口,另外还有NavigableSet和NavigableMap这两个接口;看到这些接口如果你有些什么想法的话,那么恭喜你,你对Java集合掌握非常可以;这里述说下每个接口的主要作用以及常用的一些方法,等等针对于单个接口的实现的时候我们到时候具体再说也可以;
1.Iterator接口:主要实现对集合进行迭代的迭代器;
2.基本接口:Collection和Map,这2个接口里面封装基本的集合操作,比如add,put,get等一系列方法,总体比较简单;
3.List接口:有序集合,这里面主要包括2种数据结构前面讲的很清楚了,另外还有获取元素的方法,迭代器,索引和随机访问,也就是上面的RandomAccess接口;
4.ListIterator接口:这个是Iterator接口的子接口,这个定义一个可以在迭代器以前增加元素的方法;
5.Set接口:Set接口等同于Collection接口,Set里面add里面不允许增加相同的元素;
Java里面有个 很明显的特点,就是不直接继承接口,增加一层抽象类,然后在去实现抽象类,这样有个好处就是方便我们对抽象类扩展,一但继承接口那么就必须对接口下面的所有方法进行实现,但是抽象类却不需要;
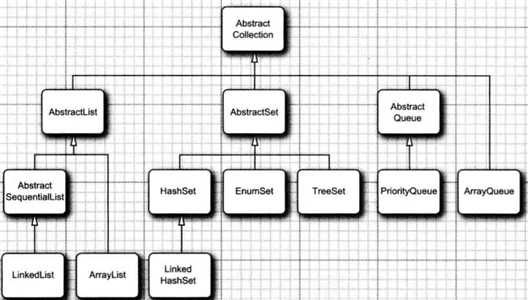
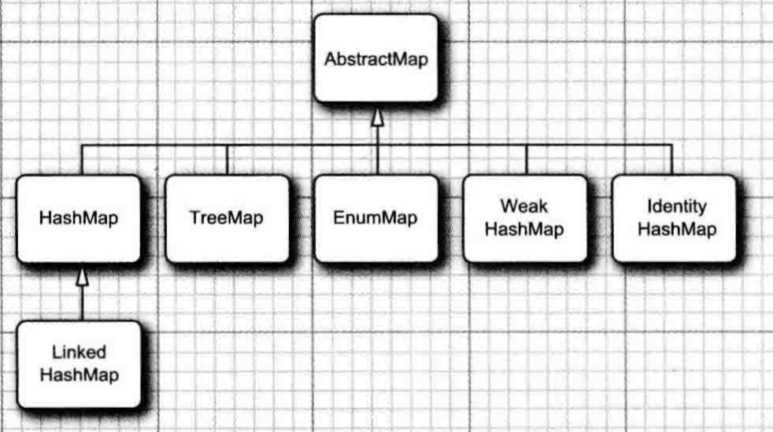
以上简单对接口的整体框架进行介绍,接下来我们开始对每一个具体的实现进行详细介绍;
三、List接口
实现这个接口的集合主要有ArryList,Vector和LinkedList,前面介绍数据接口的链表的时候已经介绍过,这里进行下对比;ArryList和Vector这两个集合就要是基于动态数组实现的,区别就在Vector是线程同步的,每一个方法都是synchronized修饰,这个地方的好处就在于读取的时候可以开2个线程同时访问这个集合,建议是不同步的时候使用ArryList,同步的时候使用Vector,LinkedList主要是基于双向链表实现,只要明白了数据结构相信这块的东西很简单,要是不明白的话可以看下我写的链表那2章;这里需要提一下LinkedList的迭代,LinkedList实现了ListIterator这个接口,可以用来遍历集合;
四、Set接口
在明白这个之前我们先要了解一种数据结构--散列表(哈希表):
什么是Hash?是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
为什么需要Hash?上面已经简单提到出现Hash的目的,是为了快速查找到我们想要的数据,这个是针对于数组和链表结构的集合来说的,当我们需要查询集合中是否于某个元素相同的时候我们需要便利整个集合,然而我们使用Hash可以减少我们的次数;这个我们举个例子,好比我们在图书管找我们需要的一本书,假设图书管理员没有进行分类整理的话,那么我们需要在一堆乱七八糟的书堆里查找我们需要的书,但是图书管理进行分类以后我们只需要按照规则去我们需要的地方找我们需要的图书就好,那么在时间上我们就更加快速;
Hash函数?上面我们已经简单提到了,Hash表的内部是按照某种规则进行分类排列,那么接下来我们说一下常见的几种函数:
1.直接定法址;
2.数字分析法;
3.平方取中法;
4.折叠法;
5.取模(求余数);----这种最常用,集合内部散列就是这样实现的;
6.随机数法;
基本上就是这几种,应该都比较简单,大家一看就明白;关键在于2点,计算简单和分布均匀;
Hash冲突?上面简单的说了一下Hash函数,我们考虑一下这个问题,就按照取模方法来说,肯定会有2个数字计算出的的余数相同,那么针对这种情况我们怎么办,怎么处理?这就是我们所说的冲突,接下来我们说一下处理冲突的手段:
1.开放定址法,这个是基于数组实现的,根据不同的处理方式我们可以分为线性探测法,二次探测法,随机探测法,再散列函数法;这里做一下概述:当发生冲突的时候我们需要存放冲突的数据,线性探测法和二次线性探测法这两个方法主要是在自身的散列上存储数据,线性探测的就是在冲突的位置继续向下查找,直到找到为空的将数据存放,这一过程中难免会遇到已经有数据的位置,这种情况叫做聚集,影响效率,二次探测法就是将向寻址的结果平方,这样就可以向前向后查找,另外二次探测法可以避免聚集,基本上只是散列表为填满的时候,我们都可以使用上面2种方法解决冲突的问题;接下来就是在散列函数法,就是冲突的时候在增加一个散列表,重新计算地址然后将数据放入;
2.链地址法,这个居于链表和数组的实现,就是当出现冲突的时候继续增加链表的节点,HashMap就是使用的这个方法;
明白Hash是什么东西接下来我们开始看下Set接口下面的集合源码,篇幅估计会比较大,我们在下一节说;
标签:链表 数组 idt 增加 聚集 hash冲突 hash函数 应该 了解
原文地址:http://www.cnblogs.com/wtzbk/p/7801848.html