标签:test sel 流式 通过 img col 表单提交 二进制 html文本
一。request库
import json import requests from io import BytesIO #显示各种函数相当于api # print(dir(requests)) url = ‘http://www.baidu.com‘ r = requests.get(url) print(r.text) print(r.status_code) print(r.encoding)
结果:
# 传递参数:不如http://aaa.com?pageId=1&type=content params = {‘k1‘:‘v1‘, ‘k2‘:‘v2‘} r = requests.get(‘http://httpbin.org/get‘, params) print(r.url) 结果:
# 二进制数据 # r = requests.get(‘http://i-2.shouji56.com/2015/2/11/23dab5c5-336d-4686-9713-ec44d21958e3.jpg‘) # image = Image.open(BytesIO(r.content)) # image.save(‘meinv.jpg‘) # json处理 r = requests.get(‘https://github.com/timeline.json‘) print(type(r.json)) print(r.text)
结果:
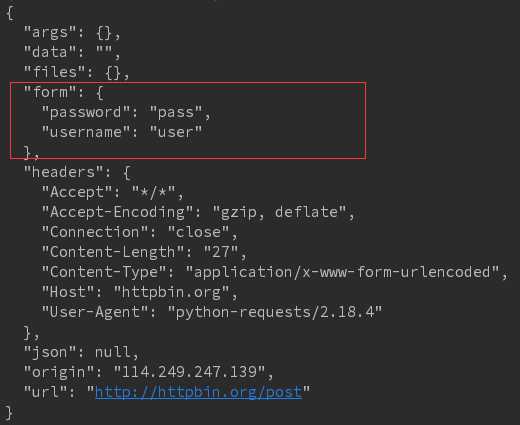
# 原始数据处理 # 流式数据写入 r = requests.get(‘http://i-2.shouji56.com/2015/2/11/23dab5c5-336d-4686-9713-ec44d21958e3.jpg‘, stream = True) with open(‘meinv2.jpg‘, ‘wb+‘) as f: for chunk in r.iter_content(1024): f.write(chunk) # 提交表单 form = {‘username‘:‘user‘, ‘password‘:‘pass‘} r = requests.post(‘http://httpbin.org/post‘, data = form) print(r.text)
结果:参数以表单形式提交,所以参数放在form参数中
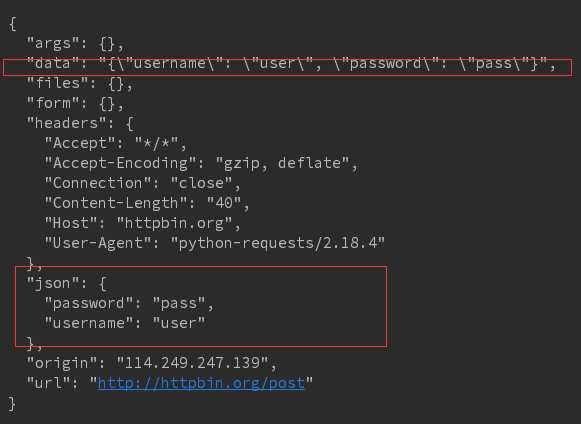
r = requests.post(‘http://httpbin.org/post‘, data = json.dumps(form)) print(r.text)
结果:参数不是以form表单提交的,所以放在json字段中
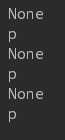
# cookie url = ‘http://www.baidu.com‘ r = requests.get(url) cookies = r.cookies #cookie实际上是一个字典 for k, v in cookies.get_dict().items(): print(k, v) 结果:cookie实际上是一个键值对
cookies = {‘c1‘:‘v1‘, ‘c2‘: ‘v2‘} r = requests.get(‘http://httpbin.org/cookies‘, cookies = cookies) print(r.text) 结果:
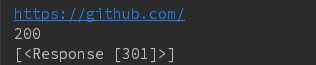
# 重定向和重定向历史 r = requests.head(‘http://github.com‘, allow_redirects = True) print(r.url) print(r.status_code) print(r.history) 结果:通过301定向
# # 代理 # # proxies = {‘http‘: ‘,,,‘, ‘https‘: ‘...‘} # r = requests.get(‘...‘, proxies = proxies)
二。BeautifulSoup库
html:举例如下
<html><head><title>The Dormouse‘s story</title></head> <body> <p class="title" name="dromouse"><b>The Dormouse‘s story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p>
解析代码如下:
from bs4 import BeautifulSoup soup = BeautifulSoup(open(‘test.html‘))
#使html文本更加结构化 # print(soup.prettify()) # Tag print(type(soup.title))
结果:bs4的一个类
print(soup.title.name)
print(soup.title)
结果如下:
# String print(type(soup.title.string)) print(soup.title.string) 结果如下:只显示标签里面内容
# Comment print(type(soup.a.string)) print(soup.a.string)
结果:显示注释中的内容,所以有时需要判断获取到的内容是不是注释
# # ‘‘‘ for item in soup.body.contents: print(item.name) 结果:body下面有三个item
# CSS查询 print(soup.select(‘.sister‘))
结果:样式选择器返回带有某个样式的所有内容 结果为一个list
print(soup.select(‘#link1‘))
结果:ID选择器,选择ID等于link1的内容
print(soup.select(‘head > title‘)) 结果:
a_s = soup.select(‘a‘) for a in a_s: print(a)
结果:标签选择器,选择所有a标签的

持续更新中。。。。,欢迎大家关注我的公众号LHWorld.

标签:test sel 流式 通过 img col 表单提交 二进制 html文本
原文地址:http://www.cnblogs.com/LHWorldBlog/p/7842267.html