标签:article 概率分布 由来 云游戏 tran 相关 实践 迭代 实战
欢迎大家前往腾讯云社区,获取更多腾讯海量技术实践干货哦~
导语: 本文是对机器学习算法的一个概览,以及个人的学习小结。通过阅读本文,可以快速地对机器学习算法有一个比较清晰的了解。本文承诺不会出现任何数学公式及推导,适合茶余饭后轻松阅读,希望能让读者比较舒适地获取到一点有用的东西。
本文是对机器学习算法的一个概览,以及个人的学习小结。通过阅读本文,可以快速地对机器学习算法有一个比较清晰的了解。本文承诺不会出现任何数学公式及推导,适合茶余饭后轻松阅读,希望能让读者比较舒适地获取到一点有用的东西。
本文主要分为三部分,第一部分为异常检测算法的介绍,个人感觉这类算法对监控类系统是很有借鉴意义的;第二部分为机器学习的几个常见算法简介;第三部分为深度学习及强化学习的介绍。最后会有本人的一个小结。
异常检测,顾名思义就是检测异常的算法,比如网络质量异常、用户访问行为异常、服务器异常、交换机异常和系统异常等,都是可以通过异常检测算法来做监控的,个人认为这种算法很值得我们做监控的去借鉴引用,所以我会先单独介绍这一部分的内容。
异常定义为“容易被孤立的离群点 (more likely to be separated)”——可以理解为分布稀疏且离密度高的群体较远的点。用统计学来解释,在数据空间里面,分布稀疏的区域表示数据发生在此区域的概率很低,因而可以认为落在这些区域里的数据是异常的。
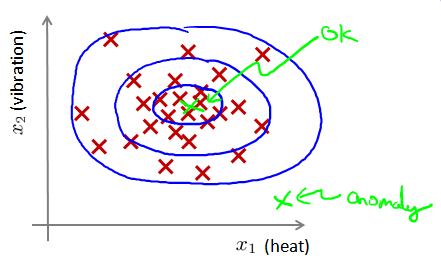
图1-1离群点表现为远离密度高的正常点
如图1-1所示,在蓝色圈内的数据属于该组数据的可能性较高,而越是偏远的数据,其属于该组数据的可能性就越低。
下面是几种异常检测算法的简介。
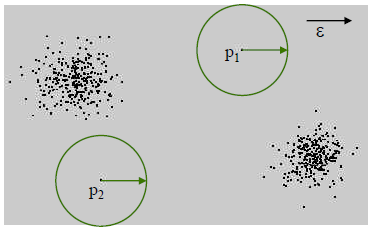
图1-2 基于距离的异常检测
思想:一个点如果身边没有多少小伙伴,那么就可以认为这是一个异常点。
步骤:给定一个半径r,计算以当前点为中心、半径为r的圆内的点的个数与总体个数的比值。如果该比值小于一个阈值,那么就可以认为这是一个异常点。
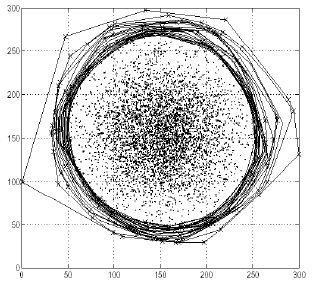
图1-3 基于深度的异常检测算法
思想:异常点远离密度大的群体,往往处于群体的最边缘。
步骤:通过将最外层的点相连,并表示该层为深度值为1;然后将次外层的点相连,表示该层深度值为2,重复以上动作。可以认为深度值小于某个数值k的为异常点,因为它们是距离中心群体最远的点。
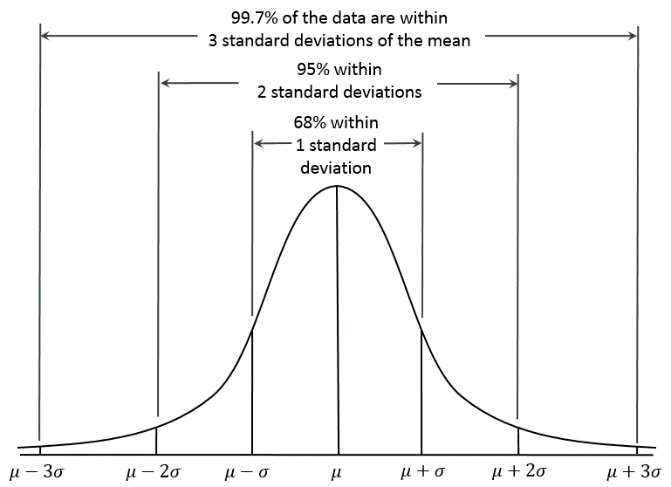
图1-4 高斯分布
思想:当前数据点偏离总体数据平均值3个标准差时,可以认为是一个异常点(偏离多少个标准差可视实际情况调整)。
步骤:计算已有数据的均值及标准差。当新来的数据点偏离均值3个标准差时,视为异常点。
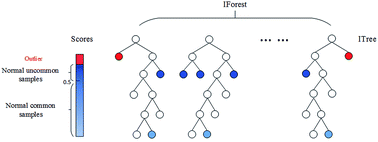
图1-5孤立深林
思想:将数据不断通过某个属性划分,异常点通常能很早地被划分到一边,也就是被早早地孤立起来。而正常点则由于群体众多,需要更多次地划分。
步骤:通过以下方式构造多颗孤立树:在当前节点随机挑选数据的一个属性,并随机选取属性的一个值,将当前节点中所有数据划分到左右两个叶子节点;如果叶子节点深度较小或者叶子节点中的数据点还很多,则继续上述的划分。异常点表现为在所有孤立树中会有一个平均很低的树的深度,如图1-5中的红色所示为深度很低的异常点。
简单介绍机器学习的几个常见算法:k近邻、k-means聚类、决策树、朴素贝叶斯分类器、线性回归、逻辑回归、隐马尔可夫模型及支持向量机。遇到讲得不好的地方建议直接跳过。

图2-1距离最近的3个点里面有2个点为红三角,所以待判定点应为红三角
分类问题。对于待判断的点,从已有的带标签的数据点中找到离它最近的几个数据点,根据它们的标签类型,以少数服从多数原则决定待判断点的类型。
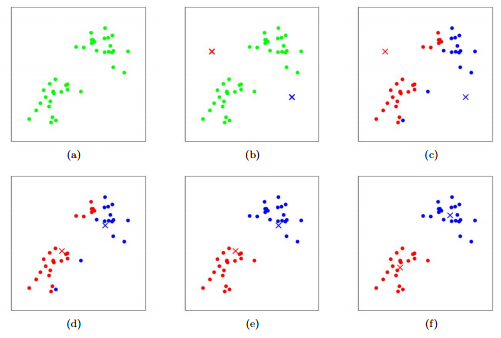
图2-2不断迭代完成“物以类聚”
k-means聚类的目标是要找到一个分割,使得距离平方和最小。初始化k个中心点;通过欧式距离或其他距离计算方式,求取各个数据点离这些中心点的距离,将最靠近某个中心点的数据点标识为同一类,然后再从标识为同一类的数据点中求出新的中心点替代之前的中心点,重复上述计算过程,直到中心点位置收敛不再变动。
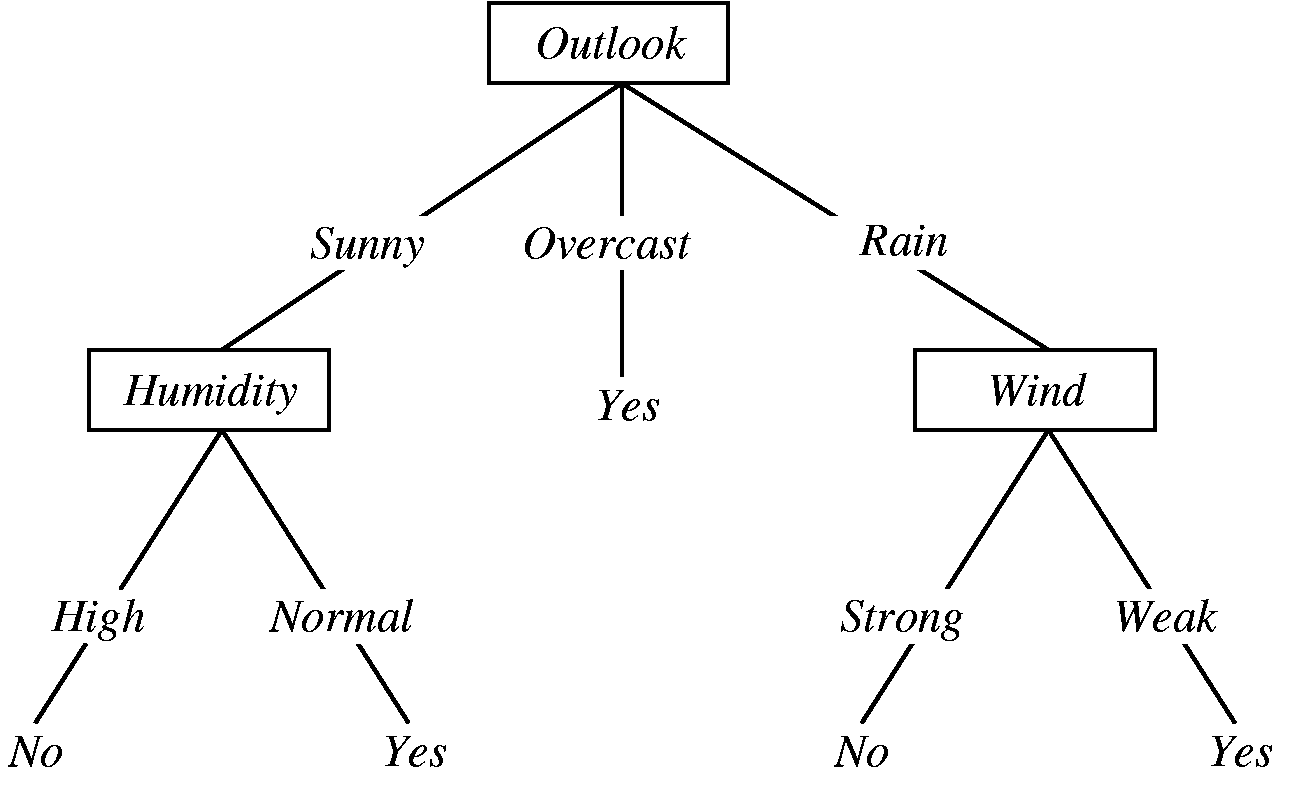
图2-3 通过决策树判断今天是否适合打球
决策树的表现形式和if-else类似,只是在通过数据生成决策树的时候,需要用到信息增益去决定最先使用那个属性去做划分。决策树的好处是表现力强,容易让人理解结论是如何得到的。
朴素贝叶斯法师基于贝叶斯定理与特征条件独立性假设的分类方法。由训练数据学习联合概率分布,然后求得后验概率分布。(抱歉,没图,又不贴公式,就这样吧-_-)
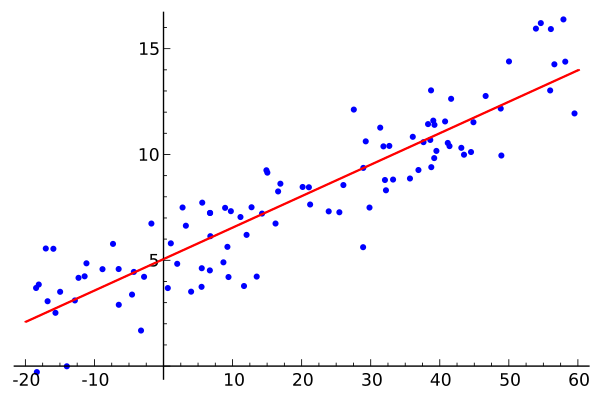
图2-4 拟一条直线,与所有数据点实际值之差的和最小
就是对函数f(x)=ax+b,通过代入已有数据(x,y),找到最合适的参数a和b,使函数最能表达已有数据输入和输出之间的映射关系,从而预测未来输入对应的输出。
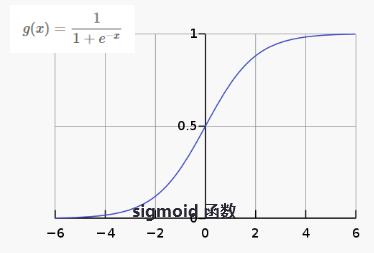
图2-5 逻辑函数
逻辑回归模型其实只是在上述的线性回归的基础上,套用了一个逻辑函数,将线性回归的输出通过逻辑函数转化成0到1之间的数值,便于表示属于某一类的概率。
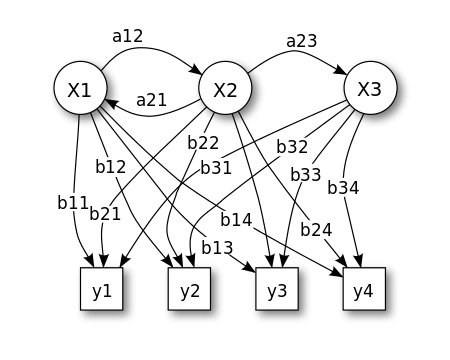
图2-6 隐藏状态x之间的转移概率以及状态x的观测为y的概率图
隐马尔科夫模型是关于时序的概率模型,描述由一个隐藏的马尔科夫链随机生成不可观测的状态的序列,再由各个状态随机生成一个观测而产生观测的序列的过程。隐马尔科夫模型有三要素和三个基本问题,有兴趣的可以单独去了解。最近看了一篇有意思的论文,其中使用了隐马尔可夫模型去预测美国研究生会在哪个阶段转专业,以此做出对策挽留某专业的学生。公司的人力资源会不会也是通过这个模型来预测员工会在哪个阶段会跳槽,从而提前实施挽留员工的必要措施?(^_^)
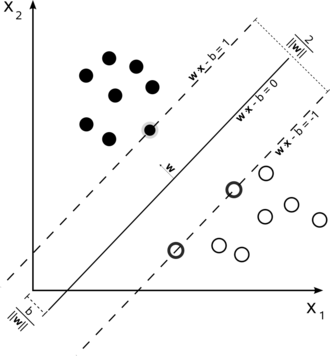
图2-7支持向量对最大间隔的支持
支持向量机是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器。如图2-7所示,由于支持向量在确定分离超平面中起着关键性的作用,所以将这种分类模型称为支持向量机。
对于输入空间中的非线性分类问题,可以通过非线性变换(核函数)将它转换为某个高维特征空间中的线性分类问题,在高维特征空间中学习线性支持向量机。如图2-8所示,训练点被映射到可以容易地找到分离超平面的三维空间。
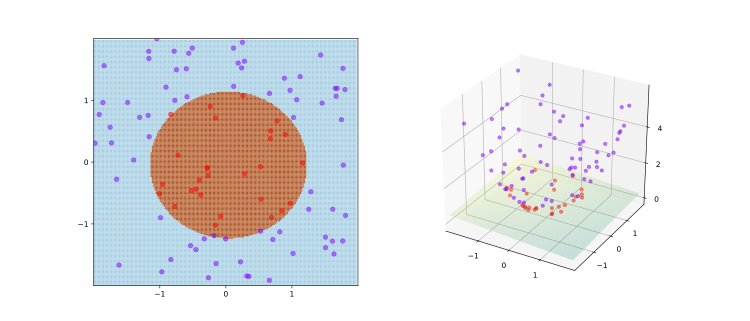
图2-8将二维线性不可分转换为三维线性可分
这里将简单介绍神经网络的由来。介绍顺序为:感知机、多层感知机(神经网络)、卷积神经网络及循环神经网络。

图3-1输入向量通过加权求和后代入激活函数中求取结果
神经网络起源于上世纪五、六十年代,当时叫感知机,拥有输入层、输出层和一个隐含层。它的缺点是无法表现稍微复杂一些的函数,所以就有了以下要介绍的多层感知机。
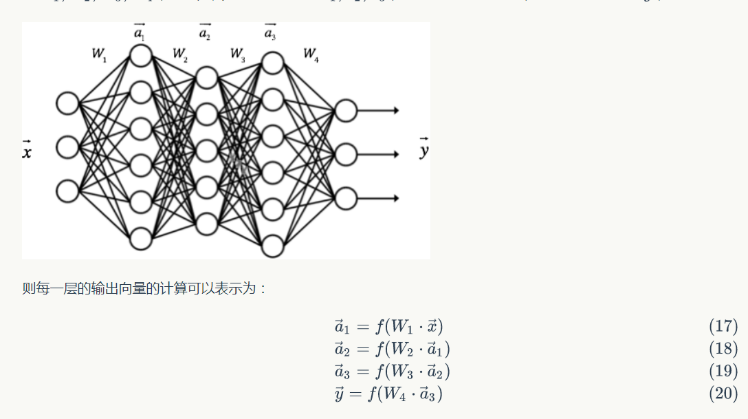
图3-2多层感知机,表现为输入与输出间具有多个的隐含层
在感知机的基础上,添加了多个隐含层,以满足能表现更复杂的函数的能力,其称之为多层感知机。为了逼格,取名为神经网络。神经网络的层数越多,表现能力越强,但是随之而来的是会导致BP反向传播时的梯度消失现象。
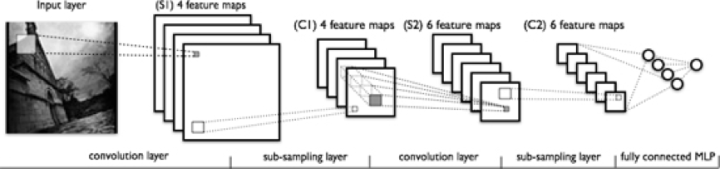
图3-3卷积神经网络的一般形式
全连接的神经网络由于中间隐含层多,导致参数数量膨胀,并且全连接方式没有利用到局部模式(例如图片里面临近的像素是有关联的,可构成像眼睛这样更抽象的特征),所以出现了卷积神经网络。卷积神经网络限制了参数个数并且挖掘了局部结构这个特点,特别适用于图像识别。
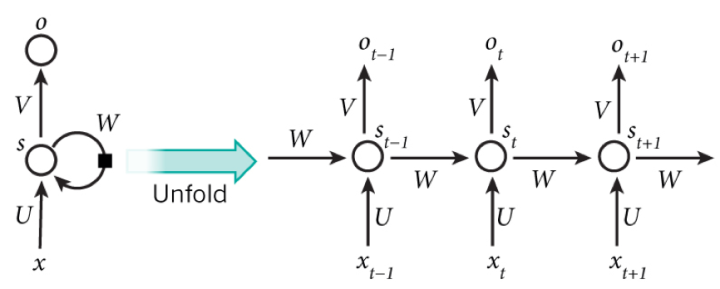
图3-4 循环神经网络可以看成一个在时间上传递的神经网络
循环神经网络可以看成一个在时间上传递的神经网络,它的深度是时间的长度,神经元的输出可以作用于下一个样本的处理。普通的全连接神经网络和卷积神经网络对样本的处理是独立的,而循环神经网络则可以应对需要学习有时间顺序的样本的任务,比如像自然语言处理和语言识别等。
机器学习其实是学习从输入到输出的映射:
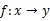
即希望通过大量的数据把数据中的规律给找出来。(在无监督学习中,主要任务是找到数据本身的规律而不是映射)
总结一般的机器学习做法是:根据算法的适用场景,挑选适合的算法模型,确定目标函数,选择合适的优化算法,通过迭代逼近最优值,从而确定模型的参数。
关于未来的展望,有人说强化学习才是真正的人工智能的希望,希望能进一步学习强化学习,并且要再加深对深度学习的理解,才可以读懂深度强化学习的文章。
最后最后,由于本人也只是抽空自学了几个月的小白,所以文中有错误的地方,希望海涵和指正,我会立即修改,希望不会误导到别人。
【1】 李航. 统计学习方法[J]. 清华大学出版社, 北京, 2012.
【2】 Kriegel H P, Kr?ger P, Zimek A. Outlier detection techniques[J]. Tutorial at KDD, 2010.
【3】 Liu F T, Ting K M, Zhou Z H. Isolation forest[C]//Data Mining, 2008. ICDM‘08. Eighth IEEE International Conference on. IEEE, 2008: 413-422.
【4】 Aulck L, Aras R, Li L, et al. Stem-ming the Tide: Predicting STEM attrition using student transcript data[J]. arXiv preprint arXiv:1708.09344, 2017.
【5】 李宏毅.deep learning tutorial. http://speech.ee.ntu.edu.tw/~tlkagk/slide/Deep%20Learning%20Tutorial%20Complete%20(v3)
【6】 科研君.卷积神经网络、循环神经网络、深度神经网络的内部结构区别. https://www.zhihu.com/question/34681168
「腾讯云游戏开发者技术沙龙」11月24 日深圳站报名开启 畅谈游戏加速
此文已由作者授权腾讯云技术社区发布,转载请注明原文出处
原文链接:https://cloud.tencent.com/community/article/570843?utm_source=bky
海量技术实践经验,尽在腾讯云社区!
标签:article 概率分布 由来 云游戏 tran 相关 实践 迭代 实战
原文地址:http://www.cnblogs.com/qcloud1001/p/7845277.html