标签:his zip 有关 语句 注意 两种方法 详细 hub 整合
首先保证这一篇分析查找算法的文章,气质与大部分搜索引擎搜索到的文章不同,主要体现在代码上面,会更加高级,会结合到很多之前研究过的内容,例如设计模式,泛型等。这也与我的上一篇面向程序员编程——精研排序算法不尽相同。
关键字:二分查找树,红黑树,散列表,哈希,索引,泛型,API设计,日志设计,测试设计,重构
查找是在大量的信息中寻找一个特定的信息元素,在计算机应用中,查找是常用的基本运算。
当今世纪,IT界最重要的词就是“数据!数据!数据!”,高效检索这些信息的能力是处理他们的重要前提。数据结构我们采用的是符号表,也叫索引和字典,算法就是下面将要研究的各种查找算法。
描述一张抽象的表格,我们会将value存入其中,然后按照指定的key来搜索并获取这些信息。符号表也叫索引,类似于书本后面列出的每个术语对应的页码(术语为key,页码为value),同时也被称为字典,类似于按照字母排序检索单词的释义(单词是key,发音释义是value)。
下文将要介绍到实现高效符号表的三种数据类型:
二分查找树、红黑树、散列表。符号表的键值对为key和value,也叫键和数据元素,大部分时候键指的都是主键(primary key),有的也包含次主键(secondary key)。
符号表支持两种操作:
| 操作 | 释义 |
|---|---|
| 插入(put) | 将一组新的键值对存入表中 |
| 查找(get) | 根据给定的键得到相应的值 |
符号表的分类
符号表的基础API设计
符号表[symbol table, 缩写ST],也有称为查找表[search table, 缩写ST],但是意思都是一样的,所以,之后下文出现的无论符号表、索引还是字典,指的都是同一个东西,不要混淆。
public class ST
| return | function | 释义 |
|---|---|---|
| . | ST() | 构造函数,创建一个索引 |
| void | put(Key key, Value val) | 将键值存入表中(若值为空则删除键) |
| Value | get(Key key) | 获取键对应的值(若key不存在返回null) |
| void | remove(Key key) | 从表中强制删除键值对 |
| boolean | containsKey(Key key) | 判断键在表中是否存在对应的值 |
| boolean | isEmpty() | 判断表是否为空 |
| int | size() | 获得表的键值对数量 |
| Iterable | keys() | 获得表中所有键的集合(可迭代的) |
下面进入算法分析阶段,这次的研究我将一改以往简码的作风,我将遵循上面API的设计,完成一个在真实实践中也可用的API架构,因此除去算法本身,代码中也会有很多实用方法。
利用这一次研究查找算法的机会,在研究具体算法内容之前,结合前面研究过的知识,我已经不满足于面向程序员编程——精研排序算法时的程序架构了(人总要学会慢慢长大...),这一次我要对系统进行重新架构。
首先建一个package search,然后按照上面的API创建一个ST基类:
package algorithms.search;
/**
* 符号表类
*
* @author Evsward
*
* @param <Key>
* @param <Value>
*/
public class ST<Key, Value> {
/**
* ST类并不去亲自实现SFunction接口
*
* @design “合成复用原则”
* @member 保存接口实现类的对象为符号表类的成员对象
*/
SFunction<Key, Value> sf;
/**
* 构造器创建符号表对象
*
* @param sf
* 指定接口的具体实现类(即各种查找算法)
*/
public ST(SFunction<Key, Value> sf) {
this.sf = sf;
}
/**
* 采用延时删除,将key的值置为null
*
* @param key
* 将要删除的key
*/
public void delete(Key key) {
sf.put(key, null);
}
/**
* 判断表内是否含有某key(value为null,key存在也算)
*
* @param key
* @return
*/
public boolean containsKey(Key key) {
@SuppressWarnings("rawtypes")
List list = (ArrayList) keySet();
list.contains(key);
return list.contains(key);
}
/**
* 判断表是否为空
*
* @return
*/
public boolean isEmpty() {
return sf.size() == 0;
}
public void put(Key key, Value val) {
sf.put(key, val);
}
public int size() {
return sf.size();
}
public Iterable<Key> keySet() {
return sf.keySet();
}
public Value get(Key key) {
return sf.get(key);
}
/**
* 即时删除(与延时删除相对应的) 直接删掉某key
*
* @param key
*/
public void remove(Key key) {
sf.remove(key);
}
}
下面,创建一个泛型接口SFunction<Key, Value>,用来定义查找算法必须要实现的方法,代码如下:
package algorithms.search;
/**
* 查找算法的泛型接口,定义必须要实现的方法
*
* @author Evsward
*
* @param <Key>
* @param <Value>
*/
public interface SFunction<Key, Value> {
public int size();// 获取表的长度
public Value get(Key key);// 查找某key的值
public void put(Key key, Value val);// 插入
public Iterable<Key> keySet();// 返回一个可迭代的表内所有key的集合
public void remove(Key key);// 强制删除一个key以及它的节点
}
下面,我们再创建一个DemoSearch算法来实现SFunction接口。代码如下:
package algorithms.search;
/**
* 查找算法接口的实现类:Demo查找
*
* @notice 在实现一个泛型接口的时候,要指定参数的类型
* @author Evsward
*
*/
public class DemoSearch implements SFunction<String, String> {
@Override
public void put(String key, String val) {
// TODO Auto-generated method stub
}
@Override
public int size() {
// TODO Auto-generated method stub
return 0;
}
@Override
public void remove(Key key) {
// TODO Auto-generated method stub
}
@Override
public Iterable<String> keys() {
// TODO Auto-generated method stub
return null;
}
@Override
public String get(String key) {
return "demo-test";
}
}
(这段话已被丢弃)说明:实现类必须指定参数类型代替泛型,否则报错。
最后再创建一个客户端,用来调用search方法:
package algorithms.search;
public class Client {
public static void main(String[] args) {
ST st;
// error: Cannot instantiate the type SFunction
st = new ST<String, String>(new SFunction());
// warning: Type safety: The constructor ST(SFunction) belongs to the
// raw type ST. References to generic type ST<Key,Value> should be
// parameterized
st = new ST(new DemoSearch());
st.get("key");
}
}
分析:
(这段话已被丢弃)由于泛型擦除的变通机制,我们无法继承一个未指定具体类型的泛型类或者实现一个未指定具体类型的泛型接口。(这段话已被丢弃) 虽然我最终也没有找到超越第一版的更好的版本,但是我们再一次加强了对java泛型的理解。所以,我们在第一版的基础之上,
在此约定,每个算法具体实现类的泛型均被指定为<String, String>。
然后将算法实现类配置到配置文件中
<sf>algorithms.search.DemoSearch</sf>
客户端代码改为:
package algorithms.search;
import tools.XMLUtil;
public class Client {
public static void main(String[] args) {
Object oSf = XMLUtil.getBean("sf");// 注入对象
@SuppressWarnings("unchecked")
ST<String, String> st = new ST<String, String>((SFunction<String, String>) oSf);
System.out.println(st);
System.out.println(st.get(""));
}
}
执行结果:
algorithms.search.ST@4e25154f
demo-test之后的算法实现类只需要:
我们发现上面的架构代码中并未出现具体的实现符号表的数据结构,例如数组、链表等。原因是每种算法依赖的数据结构不同,这些算法是直接操作于这些具体数据结构之上的(正如数据结构和算法水乳交融的关系),因此当有新的XXXSearch被创建的时候,它就会在类中引出自己需要的数据结构。上面被丢弃的第二版将泛型强制指定为<String, String>,这对系统架构中要求灵活的数据结构造成非常大的伤害,这也是第二版被丢弃的原因之一。
上面的“第二版”已被丢弃,文章将它留下的原因就是可以记录自己思考的过程,虽然没有结果,但是对设计模式,对泛型都加深了理解。那么最终架构是什么呢?由于泛型的特殊性,我们无法对其做多层继承设计,所以最终架构就是没有架构,每个算法都是一个独立的类,只能要求我自己在这些独立的算法类中去对比上面的API去依次实现。
又叫线性查找,是最基本的查找技术,遍历表中的每一条记录,根据关键字逐个比较,直到找到关键字相等的元素,如果遍历结束仍未找到,则代表不存在该关键字。
顺序查找不依赖表中的key是否有序,因此顺序查找中实现符号表的数据结构可以采用单链表结构,每个结点存储一个键值对,其中key是无序的。
package algorithms.search.support;
import java.util.ArrayList;
import java.util.List;
/**
* 已更换最新架构,请转到algorithms.search.STImpl;
*
* @notice 此类已过时,并含有bug,请对比学习。
* @author Evsward
*
* @param <Key>
* @param <Value>
*/
public class SequentialSearchSTOrphan<Key, Value> {
private Node first;
private class Node {
Key key;
Value val;
Node next;
public Node(Key key, Value val, Node next) {
this.key = key;
this.val = val;
this.next = next;
}
}
public void put(Key key, Value val) {
// 遍历链表
for (Node x = first; x != null; x = x.next) {
// 找到key则替换value
if (key.equals(x.key)) {
x.val = val;
return;
}
}
// 如果未找到key,则新增
first = new Node(key, val, first);
}
public int size() {
int count = 0;
for (Node x = first; x != null; x = x.next) {
count++;
}
return count;
}
/**
* 取出表中所有的键并存入可迭代的集合中
*
* @return 可以遍历的都是Iterable类型,这里用List
*/
public Iterable<Key> keySet() {
List<Key> list = new ArrayList<Key>();
for (Node x = first; x != null; x = x.next) {
list.add(x.key);
}
return list;
}
public Value get(Key key) {
// 遍历链表
for (Node x = first; x != null; x = x.next) {
// 找到key则替换value
if (key.equals(x.key)) {
return x.val;
}
}
return null;// 未找到则返回null
}
/**
* 永久删除
*
* @param key
*/
public void remove(Key key) {
if (containsKey(key)) {
if (key.equals(first.key)) {// 删除表头结点
first = first.next;
return;
}
// 遍历链表
for (Node x = first; x != null; x = x.next) {
if (key.equals(x.next.key)) {
if (x.next.next == null) {// 删除表尾结点
x.next = null;
return;
}
x.next = x.next.next;// 删除表中结点
}
}
}
}
/**
* 下面的方法是固定的,不需要改动。
*/
/**
* 延迟删除
*
* @param key
*/
public void delete(Key key) {
if (containsKey(key)) {
put(key, null);
}
}
public boolean containsKey(Key key) {
return get(key) != null;
}
public boolean isEmpty() {
return size() == 0;
}
}请仔细观察代码,我将其中的方法名改为与Map一致,这样可以将Map作为参照物,来测试我们新写的符号表算法,下面是客户端测试代码:
package algorithms.search.second;
import java.util.Random;
public class Client {
public static void main(String[] args) {
long start = System.currentTimeMillis();
SequentialSearchST<Integer, String> sst = new SequentialSearchST<Integer, String>();
// Map作为性能参照物
// Map<Integer, String> sst = new HashMap<Integer, String>();
if (sst.isEmpty()) {
sst.put(3, "fan");
System.out.println("sst.size() = " + sst.size());
}
if (!sst.containsKey(17)) {
sst.put(17, "lamp");
System.out.println("sst.size() = " + sst.size());
}
System.out.println("sst.get(20) = " + sst.get(20));
sst.put(20, "computer");
System.out.println("sst.get(20) = " + sst.get(20));
sst.remove(20);
System.out.println("sst.get(345) = " + sst.get(345));
Random rand = new Random();
String abc = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz";
for (int i = 0; i < 10000; i++) {
sst.put(rand.nextInt(), String.valueOf(abc.charAt(rand.nextInt(abc.length())))
+ String.valueOf(abc.charAt(rand.nextInt(abc.length()))));
}
sst.put(123, "gg");
sst.remove(3);
sst.remove(123);
sst.remove(17);
System.out.println("-----输出集合全部内容-----");
int a = 0;
for (int k : sst.keySet()) {
a++;
sst.get(k);
}
int keyR = sst.keySet().iterator().next();
System.out.println("next-key: " + keyR + " next-val: " + sst.get(keyR));
System.out.println("0-" + a + "..." + "sst.size() = " + sst.size());
long end = System.currentTimeMillis();
System.out.println("总耗时:" + (end - start) + "ms");
}
}客户端测试写了很多行,覆盖了我们符号表中所有的方法,同时也有大量的数据操作来测试性能。先看一下刚写的SequentialSearchST的输出:
sst.size() = 1
sst.size() = 2
sst.get(20) = null
sst.get(20) = computer
sst.get(345) = null
-----输出集合全部内容-----
next-key: 1727216285 next-val: Pf
0-10000...sst.size() = 10000
总耗时:640ms输出全部按预期正确,注意最后的总耗时是640ms。接下来是见证奇迹的时刻,我们将sst的对象类型改为Map,
Map<Integer, String> sst = new HashMap<Integer, String>();
再看一下输出情况:
sst.size() = 1
sst.size() = 2
sst.get(20) = null
sst.get(20) = computer
sst.get(345) = null
-----输出集合全部内容-----
next-key: 817524922 next-val: Hk
0-10000...sst.size() = 10000
总耗时:21ms这就是算法和数据结构的差异带来的性能差异。顺序查找因为有大量的遍历操作,并且它采用的单链表是一个内部类,每次要针对它进行操作,所以它的速度想想也不会太快。相较之下,jdk中的Map的性能提升不是一点半点,但是不用着急,后面会慢慢介绍到Map的实现方式,解答“为什么它这么快?”
玩个游戏,我背着你写下一个100以内的整数,你如何用最快速的方式猜出这个数是几?这个游戏我想大家小时候都接触过,方法是先猜50,问结果比50大还是小,小的话再猜25,以此类推。这就是二分查找的主要思想。
@deprecated
(这段话已被丢弃)二分查找,也称折半查找,它属于有序表查找,所以前提必须是key有序,如果将数组的下标当做key的话,数组的结构天生就是key有序,因此实现符号表的数据结构采用数组。
上面被丢弃的原因是我没有想到如果key只是数组的下标的话,无形中就是强制约束了key的类型只能为整型,其他类型无法被作为key,这对我们程序的限制非常大,我们用了泛型就希望他们是类型泛化的,而不是被强制成一种类型不能变动。
因此,我们将采用两个数组,一个数组用来存放key,一个数组用来存放value,两个数组为平行结构,通过相等的下标关联,也即实现了key-value的关联关系。
经过上面的分析,我们发现代码阶段的第一个难点其实在于动态调整数组大小,我们都知道数组的大小在创建时就被限定,无法改变其大小,这也是为什么实际工作中我们愿意使用List来替代数组的原因之一。经过查阅资料,找到了一个动态调整数组大小的下压栈。
graph TB
subgraph top
el3-->el2
el2-->el1
end这一次我们要实现数组的动态调整,因此采用泛型数组的方式实现下推栈。这里面要注意数组的大小一定要始终满足栈的空间需求,否则就会造成栈溢出,同时又要随时监控如果栈变小到一定程度,就要对数组进行减容操作,否则造成空间浪费。下面是动态调整数组栈:
package algorithms.search.second;
@SuppressWarnings("unchecked")
public class ResizeArrayStack<Item> {
/**
* 定义一个存放栈的数组
*
* @注意 该数组要始终保持空间充足以供栈的使用,否则会造成栈溢出。
*/
private Item[] target = (Item[]) new Object[1];
private int top = 0;// 栈顶指针,永远指向最新元素的下一位
// 判断栈是否为空
public boolean isEmpty() {
return top == 0;
}
// 返回栈的大小,如果插入一个元素,top就加1的话,当前top的值就是栈的大小。
public int size() {
return top;
}
/**
* 调整数组大小,以适应不断变化的栈。
*
* @supply 数组的大小不能预先设定过大,那会造成空间的浪费,影响程序性能
* @param max
*/
public void resize(int max) {
Item[] temp = (Item[]) new Object[max];
for (int i = 0; i < top; i++) {
temp[i] = target[i];
}
target = temp;
}
/**
* @step1 如果没有多余的空间,就给数组扩容
* @step2 空间充足,不断压入新元素
* @param i
*/
public void push(Item i) {
// 如果没有多余的空间,会将数组长度加倍,以支持栈充足的空间,栈永远不会溢出。
if (top == target.length)
resize(2 * target.length);// 扩充一倍
target[top++] = i;// 在top位置插入新元素,然后让top向上移动一位
}
/**
* 弹出一个元素,当弹出元素较多,数组空间有大约四分之三的空间空闲,则针对数组空间进行相应的减容
*
* @return
*/
public Item pop() {
Item item = target[--top];// top是栈顶指针,没有对应对象,需要减一位为最新对象
// 弹出的元素已被赋值给item,然而内存中弹出元素的位置还有值,但已不属于栈,需要手动置为null,以供GC收回。
target[top] = null;
// 如果栈空间仅为数组大小的四分之一,则给数组减容一半,这样可以始终保持数组空间使用率不低于四分之一。
if (top > 0 && top == target.length / 4)
resize(target.length / 2);
return item;
}
public static void main(String[] args) {
ResizeArrayStack<Client> clients = new ResizeArrayStack<Client>();
for (int i = 0; i < 5; i++) {
clients.push(new Client());
}
System.out.println("clients.size() = " + clients.size());
Client a = clients.pop();
System.out.println("clients.size() = " + clients.size());
a.testST();
}
}
输出
clients.size() = 5
clients.size() = 4
sst.size() = 1
sst.size() = 2
sst.get(20) = null
sst.get(20) = computer
sst.get(345) = null
-----输出集合全部内容-----
next-key: 1294486824 next-val: zV
0-10000...sst.size() = 10000
总耗时:21ms(客户端这还是Map呢,没改)输出正确。
集合类数据元素的基本操作之一就是可以使用foreach语句迭代遍历并处理集合中的每个元素。加入迭代的方式就是实现Iterable接口,不了解Iterable接口与泛型联用的朋友可以转到“大师的小玩具——泛型精解”,查询“Iterable接口”相关的知识。下面对ResizeArrayStack作一下改造,加入迭代。
这里我不完整地粘贴出代码了,因为改动只是很小的部分。
package algorithms.search.second;
import java.util.Iterator;
@SuppressWarnings("unchecked")
public class ResizeArrayStack<Item> implements Iterable<Item> {
...
...
public static void main(String[] args) {
ResizeArrayStack<Client> clients = new ResizeArrayStack<Client>();
for (int i = 0; i < 5; i++) {
clients.push(new Client());
}
System.out.println("clients.size() = " + clients.size());
// a.testST();
for (Client c : clients) {
System.out.println(c);
}
}
@Override
public Iterator<Item> iterator() {
return new Iterator<Item>() {
private int i = top;
@Override
public boolean hasNext() {
return i > 0;
}
@Override
public Item next() {
// top 没有值,减一位为最新的值。这里是用来迭代查找的方法,与弹出不同,不涉及事务性(增删改)操作
return target[--i];
}
};
}
}
输出
clients.size() = 5
algorithms.search.second.Client@15db9742
algorithms.search.second.Client@6d06d69c
algorithms.search.second.Client@7852e922
algorithms.search.second.Client@4e25154f
algorithms.search.second.Client@70dea4e在原ResizeArrayStack的基础上,让它实现Iterable接口,然后重写Iterator,返回一个匿名内部类,实现hasNext和next方法。注意,next方法只是用来遍历迭代的方法,与栈弹出不同,不会修改数据内容。这样一来,我们就可以方便的在客户端直接通过foreach语句迭代遍历栈内元素了。
在编写上面“加入迭代”的代码的时候,发现
public class ResizeArrayStack<Item> implements Iterable<Item> { ...
翻回上面的架构第二版内容,我知道我理解错了,人就是不断学习去进步的,因此我也不打算删除前面的内容,留下我的思考、推翻自己、决定改变和再次推翻自己的学习过程。
既然可以泛型继承,它也跟擦除机制没什么关系,那么现在可以对上面第二版的架构稍作修改,然后再次启用了。(●>?<●)
修改内容:
大部分修改依然重用了第二版的原始代码,这里不再重复粘贴展示,只是在具体实现类上采用了泛型继承,在实现类阶段不再指定具体数据类型,而在使用该类的时候可以根据使用者情况去选择适合的具体数据类型。除此之外,这次重构还在SFunction接口中新加入了一个remove方法,更改了containKey方法名和keySet方法名,用来与Map的API保持一致。从次以后,下面的代码采用这次新改的架构,请具体查看代码。
现在我们学会了数组也可以动态调整的方式,在上面的“二分查找”部分,我们也了解了二分查找的分治思想,要求Key有序,确立了基于二分查找算法的符号表的数据结构:
二分查找的数据结构:采用一对平行可变数组(实现方式参照ResizeArrayStack),分别存储key和value。
二分查找算法的代码阶段:
public class BinarySearchST<Key extends Comparable<Key>, Value> implements SFunction<Key, Value> {...package algorithms.search.second;
import java.util.ArrayList;
import java.util.List;
import algorithms.search.SFunction;
/**
* 一对平行的可变长度数组,参照ResizeArrayStack
*
* @author Evsward
* @notice 二分查找为Key有序:所以Key的泛型的边界为Comparable,可比较的,否则无法判断是否有序
* @param <Key>
* @param <Value>
*/
public class BinarySearchST<Key extends Comparable<Key>, Value> implements SFunction<Key, Value> {
private Key[] keys;
private Value[] values;
private int top;// keys顶端指针,不存值,等于数组长度的大小,keys[top-1]为最长处的元素。
/**
* 做一个通用类,可以自动先将数据排序后再进行二分查找
*
* @target 构造函数时强制Key有序,同时Value的值也要跟随变化,保证key-value的映射。
*
* @卡壳处 无法根据Key数组创建一个等长的Value数组,因为泛型数组无法被创建。
* @error Cannot create a generic array of Value
*/
public BinarySearchST() {
// 必须加一个无参构造器,否则客户端测试报错
// 通过配置文件反射创建对象没有初始化构造器参数。
resize(1);
}
public BinarySearchST(int capacity) {
if (capacity < 1)// 如果设置的不符合标准,则初始化为1
capacity = 1;
resize(capacity);
// Value valueTemp[] = new Value[keyTemp.length];// error
}
/**
* 同时调整Key和Value数组大小,以适应伸缩的键值对空间。
*
* @supply1 数组的大小不能预先设定过大,那会造成空间的浪费,影响程序性能
* @supply2 数组也不能设定小了,会造成键值对丢失,一定要足够键值对数据使用。
* @param max
*/
@SuppressWarnings("unchecked")
public void resize(int max) {
Key[] tempKeys = (Key[]) new Comparable[max];
Value[] tempValues = (Value[]) new Object[max];
for (int i = 0; i < top; i++) {
tempKeys[i] = keys[i];
tempValues[i] = values[i];
}
keys = tempKeys;
values = tempValues;
}
public int size() {
return top;
}
/**
* 二分查找:在有序keys【从小到大排序】中找到key的下标
*
* @notice 实际上同时也是二分排序
* @param key
* @return
*/
public int getIndex(Key key) {
int low = 0;
int high = size() - 1;
while (low <= high) {
int mid = low + (high - low) / 2;
int comp = key.compareTo(keys[mid]);
if (comp > 0) // key比mid大,则只比较后一半
low = mid + 1;
else if (comp < 0) // key比mid小,则只比较前一半
high = mid - 1;
else
return mid;
}
return low;// 当low=high+1的时候,依然没有找到相等的mid,就返回low【ceiling】。
}
/**
* 查找到键则更新值,否则就创建一个新键值对
*/
public void put(Key key, Value val) {
int keyIndex = getIndex(key);
if (keyIndex < top && keys[keyIndex].compareTo(key) == 0) {
// 存在键下标且值相等,更新value
values[keyIndex] = val;
return;
}
// 如果数组空间不足以新增键值对元素,则扩充一倍,保证数组的利用率始终在25%以上。
if (keys.length == size())
resize(2 * keys.length);
for (int j = top; j > keyIndex; j--) {
// 插入,后面元素都往右窜一位,把keyIndex的位置空出来。
keys[j] = keys[j - 1];
values[j] = values[j - 1];
}
keys[keyIndex] = key;
values[keyIndex] = val;
top++;// 每次插入,指针向右移动一位。
}
@Override
public Iterable<Key> keySet() {
List<Key> list = new ArrayList<Key>();
for (int i = 0; i < size(); i++) {
list.add(keys[i]);
}
return list;
}
@Override
public Value get(Key key) {
int keyIndex = getIndex(key);
if (keyIndex < top && key.compareTo(keys[keyIndex]) == 0) {
// 如果keys中存在key的下标且值也相等,则返回values相同下标的值。
return values[keyIndex];
}
return null;
}
@Override
public void remove(Key key) {
int keyIndex = getIndex(key);
if (keyIndex == top - 1)// 删除表尾键值对数据
top--;
if (keyIndex < top - 1 && keys[keyIndex].compareTo(key) == 0) {// 删除表头或表中键值对数据
// 存在键下标且值相等
for (int j = keyIndex; j < top - 1; j++) {// 注意这里循环的是数组下标,最大不能超过表尾数据(上面已处理删除表尾)
// 删除,后面元素都往左窜一位,把keyIndex的位置占上去
keys[j] = keys[j + 1];// 循环若能够到表尾[top-1]数据,j+1溢出。
values[j] = values[j + 1];
}
top--;
// 监测:如果键值对的空间等于数组的四分之一,则将数组减容至一半,保证数组的利用率始终在25%以上。
if (size() == keys.length / 4) {
resize(keys.length / 2);
}
}
}
/**
* 以下是一些除了基本符号表ST类以外的二分查找特有的方法。
*/
public Key min() {
return keys[0];
}
public Key max() {
return keys[top - 1];// 注意这里不是key.length-1,而是top-1,为什么?自己想一想
}
/**
* 返回排名为k的Key
*
* @notice 排名是从1开始的,数组下标是从0开始的
* @param k
* @return
*/
public Key select(int k) {
if (k > top || k < 0)// 越界(指的是键值对数据空间越界)
return null;
return keys[k - 1];
}
/**
* 当key不在keys中时,向上取整获得相近的keys中的元素。
*
* @param key
* 要检索的key
* @return
*/
public Key ceiling(Key key) {
int i = getIndex(key);
return keys[i];
}
/**
* 操作同上,只是向下取整
*
* @param key
* @return
*/
public Key floor(Key key) {
int i = getIndex(key);
return keys[i - 1];
}
/**
* delete, containKeys, isEmpty()方法均定义在ST中。
*/
}
输出:
algorithms.search.ST@15db9742
sst.size() = 1
sst.size() = 2
sst.get(20) = null
sst.get(20) = computer
-----输出集合全部内容-----
next-key: 125 next-val: Xd
0-10000...sst.size() = 10000
总耗时:68ms我们还记得SequentialSearchST的总耗时是多少吗?我向上翻了一下是640ms,jdk中的Map是21ms,而我们的BinarySearchST是68ms。程序的优化在稳步前进中。下面我们来分析和总结一下二分查找算法。
二分查找的关键算法在于以上代码中的getIndex方法。
getIndex():通过给定的一个key值来判断其在一个从小到大有序排列的键值对数组中的位置,如果恰好找到那个位置则返回,如果没找到,则向上取整,返回与他临近的稍大一点的key的下标。
这个方法的意义如上所说,具体实现方法采用的是二分分治的思想,每一次强制取键值对数组中间的key来与参数key比较,若参数key大,则与后一半进行比较,由于数组本身是从小到大有序排列,所以可以直接确定参数key比前一半都要大,递归执行这一操作。
我猜想可能有朋友不太理解以上代码中的keys、values和top的关系。keys和values只是对象数组,他们提供空间,而top指的是键值对数据的顶端指针,键值对数据的大小一定是小于等于对象数组的,由于数组在创建以后大小的不可变性,所以我们根据ResizeArrayStack的思想自己实现了resize方法来动态调整数组的大小以供键值对数据操作。可以类比为keys和values是舞台,键值对是舞台上面排排站的小朋友,而top指针则是小朋友队伍后面的那个老师,她并不是小朋友队伍的,但她永远在报数数最大的小朋友的后边。
这里是BinarySearchST的软肋,也是二分查找的软肋,就是要求符号表本身是有序的,但是对于静态表(不需要增删改)来说,初始化时就排序是值得的,但是更多时候,表有序并不是常见情况,因此如果想让我们的BinarySearchST在数据类型泛化的基础上进一步扩大它的使用范围,我们要在BinarySearchST中实现一个排序的算法,可以参照面向程序员编程——精研排序算法。但是正如以上代码构造器的注释所说,同时有两个泛型数组的情况下,是很难实现的,因为
无法根据Key数组创建一个等长的Value数组,因为泛型数组无法被初始化创建。// Value valueTemp[] = new Value[keyTemp.length];// error
当时我之所以想的是在构造函数里面实现排序,是因为我想初始化的时候就去把整个静态表插入进来,此时来反思这一过程,其实放在构造函数里面并不合适。因为构造函数只是构造了一个空的数组空间,我们还未向里面存入任何键值对数据,所以排序方法应该在插入的时候去为整个键值对数据做排序,(删除的时候不会破坏排序)。
《算法》也是建议在构造函数中实现符号表排序,将BinarySearchST<Key extends Comparable<Key>, Value>改为BinarySearchST<Item>,而Item是一个具体的键值对类,包含键值属性。
然而,我的代码可能与《算法》中的展示代码类似,但是我的思想却是与它不同,参照上面的“keys和top的关系?”,《算法》是将keys直接看作键值对,top就是数组的长度。而我是继承了ResizeArrayStack的思想,分割开了空间和数据的概念。这就使keys和values数组变为了空间的概念,而随着第一对键值对数据的插入,我们就开始了getIndex排序,二分查找的同时也在二分排序,这就是这段代码的神奇之处。也是我无心插柳柳成荫的幸事。
下面我们用客户端来测试一下,看是否支持无序插入,有序输出,以验证我以上的所有想法。首先改一改客户端测试脚本:
...
String abc = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz";
for (int i = 0; i < 8; i++) {
sst.put(rand.nextInt(), String.valueOf(abc.charAt(rand.nextInt(abc.length())))
+ String.valueOf(abc.charAt(rand.nextInt(abc.length()))));
}
... for (int k : sst.keySet()) {
System.out.println(k);
}最终输出结果:
class: algorithms.search.second.BinarySearchST
sst.size() = 1
sst.size() = 2
sst.get(20) = null
sst.get(20) = computer
-----输出集合全部内容-----
-1750658048
-1135712693
-594342805
-102767779
3
17
123
448486962
792653902
1785770411
1858702680
next-key: -1750658048 next-val: Zi
0-11...sst.size() = 11
总耗时:28ms可以看到,key的输出是按照大小排列的。所以我们的BinarySearchST已具备通用性,没有对原数据是否有序产生依赖。
以上代码中我在注释里面写得非常详细,如果朋友们有任何问题,可以随时留言,我会不吝解答。再对话一下看过《大话数据结构》的朋友们,如果你们只是想体会一下查找算法的核心思想,看完那本书就OK了,但是如果你想真的建立一个算法程序的概念,请你来这里,或者读一下《算法》,我们一起交流。
本文到这里,已经经历了一次架构重构,业务上面已经实现了SequentialSearchST和BinarySearchST两种查找算法。但是我发现在客户端测试时还处于非常低级与混乱的状态(恐怕读者们也忍了我好久),而且关键问题是我们的客户端测试脚本似乎无法完全覆盖我们系统的功能性需求以及性能需求。
系统测试是保障系统鲁棒性的最有利途径。
闲言少叙,我已经将客户端测试脚本改了一版:
package algorithms.search;
import java.util.Random;
import tools.XMLUtil;
public class Client {
@SuppressWarnings("unchecked")
public void testFun() {
ST<Integer, String> sst;
Object oSf = XMLUtil.getBean("sf");
sst = new ST<Integer, String>((SFunction<Integer, String>) oSf);
System.out.println("-----功能测试-----");
if (sst.isEmpty()) {
sst.put(3, "fan");
System.out.println("sst.put(3, " + sst.get(3) + ") --- sst.size() = " + sst.size());
}
sst.put(77, "eclipse");
sst.put(23, "idea");
sst.put(60, "cup");
sst.put(56, "plane");
System.out.println("sst.put 77,23,60,56 --- sst.size() = " + sst.size());
if (!sst.containsKey(1)) {
sst.put(1, "lamp");
System.out.println("sst.put(1, " + sst.get(1) + ") --- sst.size() = " + sst.size());
}
sst.put(20, "computer");
System.out.println("sst.put(20, " + sst.get(20) + ") --- sst.size() = " + sst.size());
sst.delete(20);
System.out.println("sst.delete(20) --- sst.size() still= " + sst.size());
System.out.println("-----①遍历当前集合【观察输出顺序】-----");
for (int k : sst.keySet()) {
System.out.println(k + "..." + sst.get(k));
}
System.out.println("-----②测试表头中尾删除-----");
sst.remove(20);// 【有序表中删除,顺序表头删除】
System.out.println("sst.remove(20)...【有序表中删除,顺序表头删除】");
System.out.println("sst.get(20) = " + sst.get(20) + " --- sst.size() = " + sst.size());
sst.remove(1);// 【有序表头删除,顺序表中删除】
System.out.println("sst.remove(1)...【有序表头删除,顺序表中删除】");
System.out.println("sst.get(1) = " + sst.get(1) + " --- sst.size() = " + sst.size());
sst.remove(77);// 【有序表尾删除】,顺序表中删除
System.out.println("sst.remove(77)...【有序表尾删除】,顺序表中删除");
System.out.println("sst.get(77) = " + sst.get(77) + " --- sst.size() = " + sst.size());
sst.remove(3);// 有序表中删除,【顺序表尾删除】
System.out.println("sst.remove(3)...有序表中删除,【顺序表尾删除】");
System.out.println("sst.get(3) = " + sst.get(3) + " --- sst.size() = " + sst.size());
System.out.println("-----③遍历当前集合-----");
for (int k : sst.keySet()) {
System.out.println(k + "..." + sst.get(k));
}
System.out.println("-----性能测试-----");
long start = System.currentTimeMillis();
Random rand = new Random();
String abc = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz";
for (int i = 0; i < 10000; i++) {
sst.put(rand.nextInt(10000), String.valueOf(abc.charAt(rand.nextInt(abc.length())))
+ String.valueOf(abc.charAt(rand.nextInt(abc.length()))));
}
int a = 0;
for (int k : sst.keySet()) {
a++;
sst.get(k);
}
System.out.println("0-" + a + "..." + "sst.size() = " + sst.size());
long end = System.currentTimeMillis();
System.out.println("总耗时:" + (end - start) + "ms");
}
public static void main(String[] args) {
new Client().testFun();
}
}
我会依次在config.xml中替换SequentialSearchST和BinarySearchST,观察他们的输出。
class: algorithms.search.second.SequentialSearchST
-----功能测试-----
sst.put(3, fan) --- sst.size() = 1
sst.put 77,23,60,56 --- sst.size() = 5
sst.put(1, lamp) --- sst.size() = 6
sst.put(20, computer) --- sst.size() = 7
sst.delete(20) --- sst.size() still= 7
-----①遍历当前集合【观察输出顺序】-----
20...null
1...lamp
56...plane
60...cup
23...idea
77...eclipse
3...fan
-----②测试表头中尾删除-----
sst.remove(20)...【有序表中删除,顺序表头删除】
sst.get(20) = null --- sst.size() = 7
sst.remove(1)...【有序表头删除,顺序表中删除】
sst.get(1) = null --- sst.size() = 6
sst.remove(77)...【有序表尾删除】,顺序表中删除
sst.get(77) = null --- sst.size() = 5
sst.remove(3)...有序表中删除,【顺序表尾删除】
sst.get(3) = null --- sst.size() = 4
-----③遍历当前集合-----
20...null
56...plane
60...cup
23...idea
-----性能测试-----
0-6358...sst.size() = 6358
总耗时:368ms我是一个分割线
class: algorithms.search.second.BinarySearchST
-----功能测试-----
sst.put(3, fan) --- sst.size() = 1
sst.put 77,23,60,56 --- sst.size() = 5
sst.put(1, lamp) --- sst.size() = 6
sst.put(20, computer) --- sst.size() = 7
sst.delete(20) --- sst.size() still= 7
-----①遍历当前集合【观察输出顺序】-----
1...lamp
3...fan
20...null
23...idea
56...plane
60...cup
77...eclipse
-----②测试表头中尾删除-----
sst.remove(20)...【有序表中删除,顺序表头删除】
sst.get(20) = null --- sst.size() = 6
sst.remove(1)...【有序表头删除,顺序表中删除】
sst.get(1) = null --- sst.size() = 5
sst.remove(77)...【有序表尾删除】,顺序表中删除
sst.get(77) = null --- sst.size() = 4
sst.remove(3)...有序表中删除,【顺序表尾删除】
sst.get(3) = null --- sst.size() = 3
-----③遍历当前集合-----
23...idea
56...plane
60...cup
-----性能测试-----
0-6310...sst.size() = 6310
总耗时:48ms总结:
这个版本经过我多次调试,可用性已经很高,代码中包含了多个测试用例,具体我不在这里详细列出。依然可以观察到他们的运行速度,
顺序查找是368ms,二分查找是48ms。
这里由于我测试的机器不同,以及每次测试脚本的更改,这个时间的数值可能不同,但是我们只要将他们结对对比,结果依然是有参考意义的。
以上代码虽完整,但是每次输出均只能从控制台复制出来,无法统一管理,而且代码中充斥大量的syso显得特别混乱,日志级别也没有得到有效控制,因此集成一套日志系统是非常必要的。
目前主流java的日志系统是jcl+log4j。
经过我的调查,log4j已经放出了最新版的2.9.1,而且log4j2.x貌似已经完全集成了接口和实现,也就是说我们不必再集成jcl+log4j了,直接使用log4j2即可。这样一来,我们可以尝试只采用最新的log4j2.9.1架构我们自己的日志系统。
首先去官网下载最新的apache-log4j-2.9.1-bin.zip。解压缩出来一大堆的包,根据官方文档我写了一个helloworld,需要引入:
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
经过尝试,发现引入log4j-api-2.9.1.jar可以成功导入这两个包,然而在运行时发生报错:
ERROR StatusLogger Log4j2 could not find a logging implementation. Please add log4j-core to the classpath. Using SimpleLogger to log to the console...
我又引入了log4j-core-2.9.1.jar,再次运行继续报错:
ERROR StatusLogger No log4j2 configuration file found. Using default configuration: logging only errors to the console. Set system property ‘log4j2.debug‘ to show Log4j2 internal initialization logging.
根据报错信息,开始添加log4j2的配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<File name="LogFile" fileName="output.log" bufferSize="1"
advertiseURI="./" advertise="true">
<PatternLayout
pattern="%d{YYYY/MM/dd HH:mm:ss} [%t] %-5level %logger{36} - %msg%n" />
</File>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout
pattern="%d{HH:mm:ss} %-5level %logger{36} - %msg%n" />
</Console>
</Appenders>
<Loggers>
<Root level="info">
<AppenderRef ref="Console" />
<AppenderRef ref="LogFile" />
</Root>
</Loggers>
</Configuration>根据我的想法,以上配置描述了:
然后新创建一个客户端VIPClient,集成最新日志系统,只需要将原来的syso替换为logger.info即可。替换完以后进行测试输出:
class: algorithms.search.second.BinarySearchST
14:44:20 INFO algorithms.search.VIPClient - -----功能测试-----
14:44:20 INFO algorithms.search.VIPClient - sst.put(3, fan) --- sst.size() = 1
...
...此时再去工程根目录下查看output.log:
2017/11/09 14:44:20 [main] INFO algorithms.search.VIPClient - -----功能测试-----
2017/11/09 14:44:20 [main] INFO algorithms.search.VIPClient - sst.put(3, fan) --- sst.size() = 1
2017/11/09 14:44:20 [main] INFO algorithms.search.VIPClient - sst.put 77,23,60,56 --- sst.size() = 5
...
...集成日志成功。
我们集成一个简单的单元测试,不再使用main方法去测试了。很简单,只要把main方法删除,新增一个test方法:
@Test(timeout = 1000)
public void test() {
new VIPClient().testFun();
}增加注解Test,同时设定timeout的时间为1s,也就是说我们最长允许系统阻塞pending时间为1s,但是当发现问题需要调试时,请将超时限制去掉。
以后再测试,随时可以在JUnit界面点击rerun test即可触发单元测试,不必再进入main方法界面去右键点击运行了,再加上我们上面集成的日志备份系统,非常方便。
接下来的开发流程只需要:
? (? ? ?)?
上面介绍了使用单链表实现的顺序查找和使用数组实现的二分查找。他们各有所侧重,顺序查找在插入上非常灵活,而二分查找在查询上非常高效,换句话说,一个适合静态表,一个适合动态表。但是顺序查找在查询时要使用大量遍历,二分查找在插入时也有大量操作,这都是他们各自的劣势。下面将介绍的二叉查找树,是结合了以上两种查找方式的优势,同时又最大化地避开了他们的劣势。
二叉查找树,是计算机科学中最重要的算法之一。
顾名思义,这个算法依赖的数据结构不是链表也不是数组,而是二叉树。每个结点含有左右两个链接(也就是左右子结点),链接可以指向空或者其他结点。同时每个结点还存储了一组键值对。
定义:一棵二叉查找树(BST, short of "Binary Search Tree"),是一棵二叉树,其中每个结点都含有一个Comparable的键(以及相关联的值)且每个结点的键都大于其左子树中的任意节点的键而小于右子树的任意结点的键。
二叉查找树的画法:键会标在结点上,对应的值写在旁边,除空结点(空结点没有结点)只表示为向下的一条线段以外,每个结点的链接都指向它下方的结点。
package algorithms.search;
/**
* 查找算法的泛型接口,定义必须要实现的方法
*
* @notice 针对有序列表的扩展接口
* @author Evsward
* @param <Key>
* @param <Value>
*/
public interface SFunctionSorted<Key, Value> {
/**
* 获取最小键
*
* @return
*/
public Key min();
/**
* 获取最大键
*
* @return
*/
public Key max();
/**
* 获取k位置的键【一般指有序列表中】
*
* @return
*/
public Key select(int k);
/**
* 获取键对应符号表中向上取整的键
*
* @return
*/
public Key ceiling(Key key);
/**
* 获取键对应符号表中向下取整的键
*
* @return
*/
public Key floor(Key key);
/**
* 重合这部分方法,用来测试
*/
public void put(Key key, Value val);// 插入
public Iterable<Key> keySet();// 迭代表内所有key
public Value get(Key key);// 查找某key的值
}
接下来为实现了SFunctionSorted接口的类添加测试。我们将VIPClient改造了一下,去掉了main方法,直接在方法名上执行测试,增加了一个新测试方法。
package algorithms.search;
import java.util.Random;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import org.junit.Test;
import tools.XMLUtil;
public class VIPClient {
private static final Logger logger = LogManager.getLogger();
@SuppressWarnings("unchecked")
@Test
public void testST() {... // 代码同上,这里不重复粘贴。
}
@SuppressWarnings("unchecked")
@Test
/**
* 由于有序符号表实现了两个接口,SFunction相关的通过testST可以测试,这里仅测试与SFunctionSorted的方法。
*/
public void testSST() {
SST<Integer, String> sst;
Object oSf = XMLUtil.getBean("ssf");
sst = new SST<Integer, String>((SFunctionSorted<Integer, String>) oSf);
sst.put(3, "fan");
sst.put(77, "eclipse");
sst.put(23, "idea");
sst.put(60, "cup");
sst.put(56, "plane");
sst.put(1, "lamp");
sst.put(20, "computer");
logger.info("-----①遍历当前集合【观察输出顺序】-----");
for (int k : sst.keySet()) {
logger.info(k + "..." + sst.get(k));
}
logger.info("-----②有序表特有功能测试-----");
logger.info("sst.ceiling(59) = " + sst.ceiling(59));
logger.info("sst.floor(59) = " + sst.floor(59));
logger.info("sst.min() = " + sst.min());
logger.info("sst.max() = " + sst.max());
logger.info("sst.select(3) = " + sst.select(3));
}
}
同时,为config.xml增加字段:
<sf>algorithms.search.second.BinarySearchST</sf>
<ssf>algorithms.search.second.BinarySearchST</ssf>我也对log格式进行了调整,增加了方法名,以便于区分以上两个测试方法。
举例说明:
如果每一次都要查看日志,一行行比对方法输出结果信息的话,那实在很费力,相同的事情做多遍,为了快速验证我们的代码是否通过测试,可以引入断言机制。
assertTrue(sst.ceiling(59) == 60);就像这样,但是要求VIPClient导入对应的包
import static org.junit.Assert.*;然后就可以正常使用了,我们只要在输出的每一个位置,设定好预计输出的正确的值交给断言去判断,如果错误会中断测试。在testST和testSST的方法体结尾处添加一行
logger.info("测试成功!");每次执行Junit,只要看结尾是否有“测试成功”的字样即可,看到了就代表测试通过,不比再依次比对输出结果。如果看不到,则可以去看是哪一行断言出了问题,也能准确定位错误的位置。
我发现,每一次去修改config.xml中的类名,以此来决定执行的是哪一个实现类,这样非常麻烦,况且又新增了有序表的实现类配置。能否每次只是增加一个新的实现类,一次配置,不用修改。因此有了:
<?xml version="1.0"?>
<config>
<!-- 符号表实现类 SequentialSearchST BinarySearchST BST -->
<sf1>algorithms.search.second.SequentialSearchST</sf1>
<sf2>algorithms.search.second.BinarySearchST</sf2>
<sf3>algorithms.search.second.BST</sf3>
<!-- 有序符号表实现类 BinarySearchST BST -->
<ssf1>algorithms.search.second.BinarySearchST</ssf1>
<ssf2>algorithms.search.second.BST</ssf2>
</config> 每一次新增一个实现类只要在config.xml中按照需要添加到相应的位置。
@Test
public void testSTBatch() {
logger.info("------开始批量测试------");
testST("sf1");
testST("sf2");
//...
logger.info("------批量测试成功!------");
}
@Test
public void testSSTBatch() {
logger.info("------开始批量测试------");
testSST("ssf1");
//...
logger.info("------批量测试成功!------");
}<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<File name="LogFile" fileName="output.log" bufferSize="1"
advertiseURI="./" advertise="true">
<ThresholdFilter level="debug" onMatch="ACCEPT"
onMismatch="DENY" />
<PatternLayout
pattern="%d{YYYY/MM/dd HH:mm:ss} [%t] %-5level %logger{36} - %msg%n" />
</File>
<!--这个会打印出所有的信息,每次大小超过size,则这size大小的日志会自动存入按年份-月份建立的文件夹下面并进行压缩存档 -->
<RollingFile name="RollingFile" fileName="logs/mainbase.log"
filePattern="log/$${date:yyyy-MM}/app-%d{MM-dd-yyyy}-%i.log.gz">
<PatternLayout
pattern="%d{yyyy-MM-dd ‘at‘ HH:mm:ss z} %-5level %class{36} %L %M - %msg%xEx%n" />
<SizeBasedTriggeringPolicy size="1MB" />
</RollingFile>
<Console name="Console" target="SYSTEM_OUT">
<ThresholdFilter level="info" onMatch="ACCEPT"
onMismatch="DENY" />
<PatternLayout pattern="%d{HH:mm:ss}[%M]: %msg%n" />
</Console>
</Appenders>
<Loggers>
<Root level="debug">
<AppenderRef ref="LogFile" />
<AppenderRef ref="Console" />
</Root>
</Loggers>
</Configuration>以后每次测试只需要:
package algorithms.search.second;
import java.util.LinkedList;
import algorithms.search.SFunction;
import algorithms.search.SFunctionSorted;
/**
* 二叉查找树,默认都是从小到大,从左到右排序
*
* @notice 二叉查找树将用到大量递归,每个公有方法都对应着一个用来递归的私有方法
* @see 每棵树由其根结点代表
* @author Evsward
*
* @param <Key>
* @param <Value>
*/
public class BST<Key extends Comparable<Key>, Value> implements SFunction<Key, Value>, SFunctionSorted<Key, Value> {
private TreeNode root;// 定义一个根节点,代表了整个BST。
protected class TreeNode {
protected Key key;
protected Value value;
protected TreeNode leftChild;// 左链接:小于该结点的所有键组成的二叉查找树
protected TreeNode rightChild;// 右链接:大于该结点的所有键组成的二叉查找树
protected int size;// 以该结点为根的子树的结点总数
// 构造函数创建一个根节点,不包含左子右子。
public TreeNode(Key key, Value value, int size) {
this.key = key;
this.value = value;
this.size = size;
}
}
@Override
public int size() {
return size(root);
}
protected int size(TreeNode node) {
if (node == null)
return 0;
return node.size;
}
@Override
public void put(Key key, Value val) {
// 注意将内存root的对象作为接收,否则对root并没有做实际修改。
root = put(root, key, val);
}
/**
* 递归函数:向根节点为x的树中插入key-value
*
* @理解递归 把递归当作一个黑盒方法,而不要跳进这个里边
* @核心算法
* @param x
* @param key
* @param val
* @return 插入key-value的新树
*/
private TreeNode put(TreeNode x, Key key, Value val) {
if (x == null)// 若x为空,则新建一个key-value结点。
return new TreeNode(key, val, 1);// 初始化长度只为1。
int comp = key.compareTo(x.key);
if (comp < 0)
x.leftChild = put(x.leftChild, key, val);
else if (comp > 0)
x.rightChild = put(x.rightChild, key, val);
else if (comp == 0)// 如果树x已有key,则更新val值。
x.value = val;
x.size = size(x.leftChild) + size(x.rightChild) + 1;
return x;
}
@Override
public Iterable<Key> keySet() {
return keySet(root);
}
protected Iterable<Key> keySet(TreeNode x) {
if (x == null)
return null;
LinkedList<Key> list = new LinkedList<Key>();
Iterable<Key> leftKeySet = keySet(x.leftChild);
Iterable<Key> rightKeySet = keySet(x.rightChild);
if (leftKeySet != null) {
for (Key k : leftKeySet) {// 按照顺序,先add左边小的
list.add(k);
}
}
list.add(x.key);// 按照顺序,再add中间的根节点
if (rightKeySet != null) {
for (Key k : rightKeySet) {// 按照顺序,最后add右边大的
list.add(k);
}
}
return list;
}
@Override
public Value get(Key key) {
return get(root, key);
}
/**
* 设置递归方法:在结点node中查找条件key
*
* @核心算法
* @param node
* @param key
* @return
*/
protected Value get(TreeNode node, Key key) {
if (node == null)
return null;// 递归调用最终node为空,未命中
int comp = key.compareTo(node.key);
if (comp < 0)
return get(node.leftChild, key);
else if (comp > 0)
return get(node.rightChild, key);
return node.value;// 递归调用最终命中
}
@Override
public void remove(Key key) {
// 注意将内存root的对象作为接收,否则对root并没有做实际修改。
root = remove(root, key);
}
/**
* 强制删除树x中key的键值对
*
* @param x
* @param key
* @return
*/
private TreeNode remove(TreeNode x, Key key) {
if (x == null)// 若x为空,返回空
return null;
int comp = key.compareTo(x.key);
if (comp < 0)
// 从左子树中删除key并返回删除后的左子树
// 这里不能直接返回,要执行下面的size重置。
x.leftChild = remove(x.leftChild, key);
else if (comp > 0)
// 从右子树中删除key并返回删除后的右子树
// 这里不能直接返回,要执行下面的size重置。
x.rightChild = remove(x.rightChild, key);
else {// 命中,删除
if (x.leftChild == null && x.rightChild == null)// 说明树x只有一个结点
return null;
else if (x.rightChild == null)// 表尾删除
x = x.leftChild;
else if (x.leftChild == null)// 表头删除
x = x.rightChild;
else {// 表中删除,越过根节点x,重构二叉树
// 这是二叉树,不是数组,x.rightChild是右子树的根结点
// 要找出右子树的最小结点需要调用方法min(TreeNode x)
TreeNode t = x;
x = min(t.rightChild);// x置为右子树中的最小值,替换待删除x
x.rightChild = deleteMin(t.rightChild);// 右子树为删除最小值(即当前x)以后的树
x.leftChild = t.leftChild;// 左子树均不变
}
}
x.size = size(x.leftChild) + size(x.rightChild) + 1;
return x;
}
public void deleteMin() {
// 注意将内存root的对象作为接收,否则对root并没有做实际修改。
root = deleteMin(root);
}
/**
* 删除树x中最小的键对应的键值对
*
* @param x
* @return 删除以后的树
*/
private TreeNode deleteMin(TreeNode x) {
if (x == null)// 一定要先判断null,避免空值异常
return null;
if (x.leftChild == null)
return x.rightChild;// x.rightChild将x替换。x被删除
x.leftChild = deleteMin(x.leftChild);// 否则在左子树中继续查找
// ******注意处理size的问题,不要忘记******
x.size = size(x.leftChild) + size(x.rightChild) + 1;
return x;
}
public void deletMax() {
// 注意将内存root的对象作为接收,否则对root并没有做实际修改。
root = deleteMax(root);
}
/**
* 删除树x中最大的键对应的键值对
*
* @param x
* @return 删除以后的树
*/
private TreeNode deleteMax(TreeNode x) {
if (x == null)// 一定要先判断null,避免空值异常
return null;
if (x.rightChild == null)
return x.leftChild;// 越过x,返回x.leftChild。x被删除
x.rightChild = deleteMax(x.rightChild);// 否则在右子树中继续查找
// ******注意处理size的问题,不要忘记******
x.size = size(x.leftChild) + size(x.rightChild) + 1;
return x;
}
/**
* 实现针对有序列表的扩展接口的方法。
*/
protected TreeNode min(TreeNode x) {
// 当结点没有左结点的时候,它就是最小的
if (x.leftChild == null)
return x;
return min(x.leftChild);
}
@Override
public Key min() {
return min(root).key;
}
protected TreeNode max(TreeNode x) {
// 当结点没有右结点的时候,它就是最小的
if (x.rightChild == null)
return x;
return max(x.rightChild);
}
@Override
public Key max() {
return max(root).key;
}
@Override
public Key select(int k) {
// int a = 0;
// for (Key key : keySet()) {
// if (a++ == k)
// return key;
// }
// return null;
return selectNode(root, k).key;
}
/**
* 获取在树x中排名为t的结点
*
* @notice 位置是从0开始,排名是从1开始。
* @param x
* @param t
* @return
*/
protected TreeNode selectNode(TreeNode x, int t) {
if (x == null)// 一定要先判断null,避免空值异常
return null;
if (x.leftChild.size > t && t > 0)// 左子树的size大于t,则继续在左子树中找
return selectNode(x.leftChild, t);
else if (x.leftChild.size == t)// 左子树的size与t相等,说明左子树的最大值就是排名t的结点
return max(x.leftChild);
else if (x.leftChild.size < t && t < x.size)// t比左子树的size大,且小于根节点的总size
// 其实就是rightChild的范围,在右子树中寻找,排名为右子树中的排名,所以要减去左子树的size
return selectNode(x.rightChild, t - x.leftChild.size - 1);// -1是因为要减去根结点
else if (t == x.size)// 排名恰好等于结点的总size,说明排名为t的结点为最大结点,即有序表中的最后结点
return max(x);
else// 其他情况为t越界,返回null
return null;
}
public int getRank(Key key) {
return getRank(root, key);
}
/**
* 获取key在树x中的排名,即位置+1,位置是从0开始,排名是从1开始。
*
* @param x
* @param key
* @return
*/
protected int getRank(TreeNode x, Key key) {
if (x == null)// 一定要先判断null,避免空值异常
return 0;
int comp = key.compareTo(x.key);
if (comp > 0)
return getRank(x.rightChild, key) + x.leftChild.size + 1;
else if (comp < 0)
return getRank(x.leftChild, key);
else
return x.leftChild.size;
}
@Override
public Key ceiling(Key key) {
TreeNode x = ceiling(root, key);// 最终也没找到比它大的,这个key放在表里面是最大的
if (x == null)
return null;
return x.key;
}
/**
* 向上取整,寻找与key相邻但比它大的key
*
* @param x
* @param key
* @return
*/
protected TreeNode ceiling(TreeNode x, Key key) {
if (x == null)// 一定要先判断null,避免空值异常
return null;// 递归调用最终node为空,未找到符合条件的key
int comp = key.compareTo(x.key);
if (comp == 0)// 相等即返回,不必取整
return x;
else if (comp > 0)// 比根节点大,则ceiling一定继续在右子树里面找
return ceiling(x.rightChild, key);
else if (comp < 0) {// 比根节点小,则在左子树中尝试寻找比它大的结点作为ceiling
TreeNode a = ceiling(x.leftChild, key);
if (a != null)// 找到了就返回
return a;
}
return x;// 没找到就说明只有根节点比它大,则返回根节点
}
@Override
public Key floor(Key key) {
TreeNode x = floor(root, key);
if (x == null)// 最终也没找到比它小的,这个key放在表里面是最小的
return null;
return x.key;
}
/**
* 向下取整,寻找与key相邻但比它小的key
*
* @param x
* @param key
* @return
*/
protected TreeNode floor(TreeNode x, Key key) {
if (x == null)// 一定要先判断null,避免空值异常
return null;// 递归调用最终node为空,未找到符合条件的值
int comp = key.compareTo(x.key);
if (comp == 0)// 若相等,则没必要取整,直接返回即可
return x;
else if (comp < 0)// 如果比根节点小,说明floor一定在左子树
return floor(x.leftChild, key);
else if (comp > 0) {// 如果大于根节点
TreeNode a = floor(x.rightChild, key);// 先查找右子树中是否有比它小的值floor
if (a != null)// 找到了则返回
return a;
}
return x;// 否则,最终只有根节店key比它小,作为floor返回。
}
}
在config.xml中的sf和ssf分别加入BST。然后执行两个批量测试,输出结果为:
14:48:45[testSTBatch]: ------开始批量测试------
14:48:45[getBean]: class: algorithms.search.second.SequentialSearchST
14:48:46[testST]: 总耗时:357ms
14:48:46[getBean]: class: algorithms.search.second.BinarySearchST
14:48:46[testST]: 总耗时:40ms
14:48:46[getBean]: class: algorithms.search.second.BST
14:48:46[testST]: 总耗时:20ms
14:48:46[testSTBatch]: ------批量测试成功!------我是有序表测试的分割线
14:49:11[testSSTBatch]: ------开始批量测试------
14:49:11[getBean]: class: algorithms.search.second.BinarySearchST
14:49:11[getBean]: class: algorithms.search.second.BST
14:49:11[testSSTBatch]: ------批量测试成功!------通过结果可以看出,我们新增的BST已经通过了符号表基础API以及有序符号表API的功能测试,而在性能测试方面,BST遥遥领先为20ms,二分查找为40ms,而顺序查找为357ms。关于二分查找树的各个方法的具体实现,我在代码中已经有了详细的注释,如有任何问题,欢迎随时留言,一起讨论。
二叉查找树是效率较高的查找算法,但是它只是要求二叉树的左子树所有结点必须小于根结点,同时右子树所有结点必须大于根结点。它可以是普通二叉树,可以是完全二叉树,也可以是满二叉树,并不限制二叉树的结构。殊不知,相同的由二叉查找树实现的符号表,结构不同,效率也不同,二叉查找树层数越多,比较次数也就越多,所以二叉查找树是不稳定的,最坏情况可能效率并不高。
理想情况下,我们希望在二叉查找树的基础上,保证在一棵含有N个几点的数中,树高为log2N,是完全二叉树的结构。
但是在动态表中,不断维持完美二叉树的代价会很高,我们希望找到一种结构能够在尽可能减小这个代价的前提下,保证实现符号表API的操作都能在对数时间内完成的数据结构。
注意:这种结构是树,可以不是二叉树。
如果能始终保持二叉查找树的结构为完美平衡结构,那么它的查找算法将会发挥最高效率,同时也会随着这种稳定的结构而效率稳定。
学习一种结构,它也是一个树,但是它包含两种结点类型:2-结点和3-结点。
这种结构叫做2-3查找树,内部包含2-结点和3-结点混搭。如下图所示:
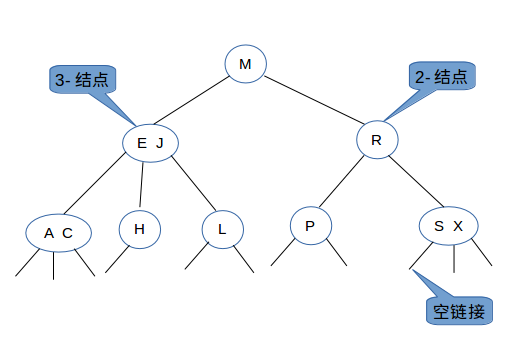
一种完美平衡的2-3查找树中的所有空链接到根结点的距离都应该是相同的。以下所有2-3查找树均指的是这种完美平衡的2-3查找树。
想出这种结构的人真是大师,为了时刻保持数据能够化为“满树”,这种方式真的很巧妙。对,《算法》的作者Robert Sedgewick大叔,崇拜的就是你,当然了每一种新型技术出现必然都是如一棵树一样,有它自己的根源,并不是一个人自己就能够创造的,他也是经过对前人智慧的总结再加上自身的钻研而取得的成就,致敬所有这一条路上奋斗且做出贡献的大师。
以上这些操作应该可以覆盖2-3查找树在实现符号表API过程中的所有操作了
注意:无论2-3树如何操作,2结点与3结点如何转换,都不会破坏2-3树的“满树”形态,都不会影响2-3树的全局有序性
2-3树的平衡性:全树的任意空链接到根结点的距离都是相等的。
根据上面介绍的巧妙的2-3查找树,我们要在程序中找到一种可行的数据结构来实现它,这种数据结构就是红黑二叉查找树。
由于红黑树属于二叉查找树,所以大部分的方法可以直接复用BST。
现在我们要研究的是用代码实现红黑树与2-3树的转换。
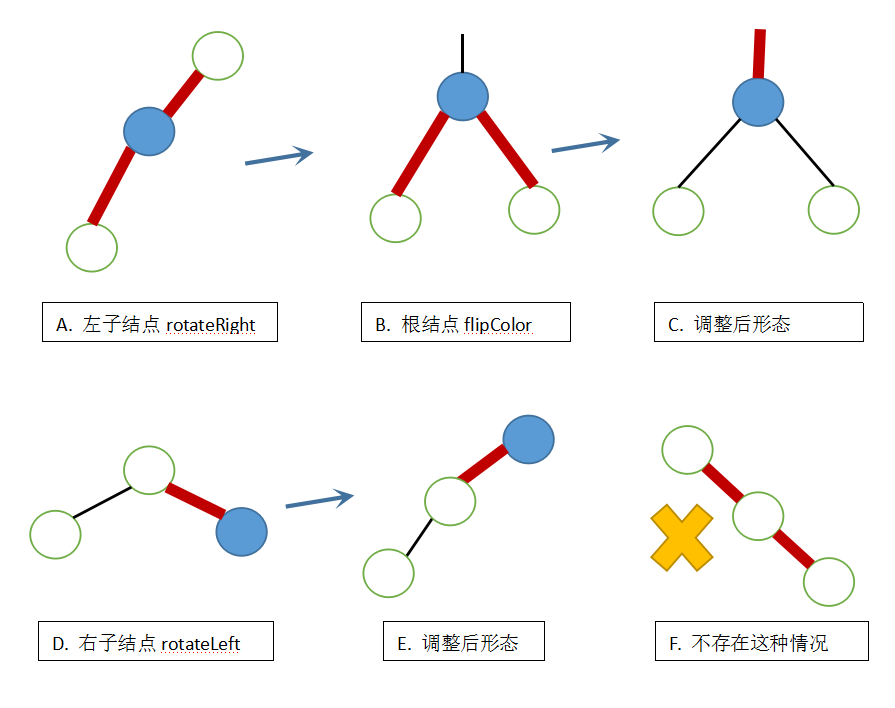
保证没有右红链接(红黑树完整定义的第一条)
当在一个2-结点插入一个新键大于老键,这个新键必然是一个右红链接,这时候需要使用上面的左旋转(rotateLeft)将其调整过来。
问:为什么插入新的键,一定是红链接?
答:根据红黑树的完整定义,任意空链接到根结点的路径上的黑链接数量相同。如果我们插入的新键不采用红链接而是黑链接,那么必然导致新键为根结点的空链接到根节点的路径上的黑链接数量增加了一个,就不能保持完美黑色平衡了。因此只有新键采用红链接,才不会打破这个完美黑色平衡。
保证不存在两条连续的红链接(红黑树完整定义的第二条)
当在一个3-结点(一个根结点,一条左红链接指向其左子结点)插入一个新键时,必然会出现一个结点同时和两条红链接相连的情况。flipColor红链接的向上传递
上面三种操作都用到了将两条红链接变黑,父结点的黑链接变红的操作,我们将其封装为一个方法flipColor来负责这个操作。flipColor的操作中根结点会由黑变红。从2-3树的角度来说,相当于把根结点送入了父结点,这意味着在父结点新插入了一个键,如果父结点是红链接(即3-结点),那么仍需要按照在3-结点中插入新键的方式去调整,直到遇到父结点为树的根结点或者是一个黑链接(即2-结点为止)。这个过程就是红链接在树中的向上传递。
左旋转和右旋转
我们不是要保证红链接一直为左链接吗?为什么还要有右旋转,其实是这样的,上面讲过了3-结点的新键插入,一般来讲,右旋转的操作之后一定会跟着一个颜色转换,这样就可以保证我们的右红链接不存在了。而左右旋转的使用时机在这里再总结一番:如下图所示:
红黑树插入举例
仍旧使用我们测试脚本中的例子,在此红黑树中依次插入3,77,23,60,56,1,20,根据这几个数值的特性,预期效果应该是最终形成一个完全二叉树,分解成示意图如下:
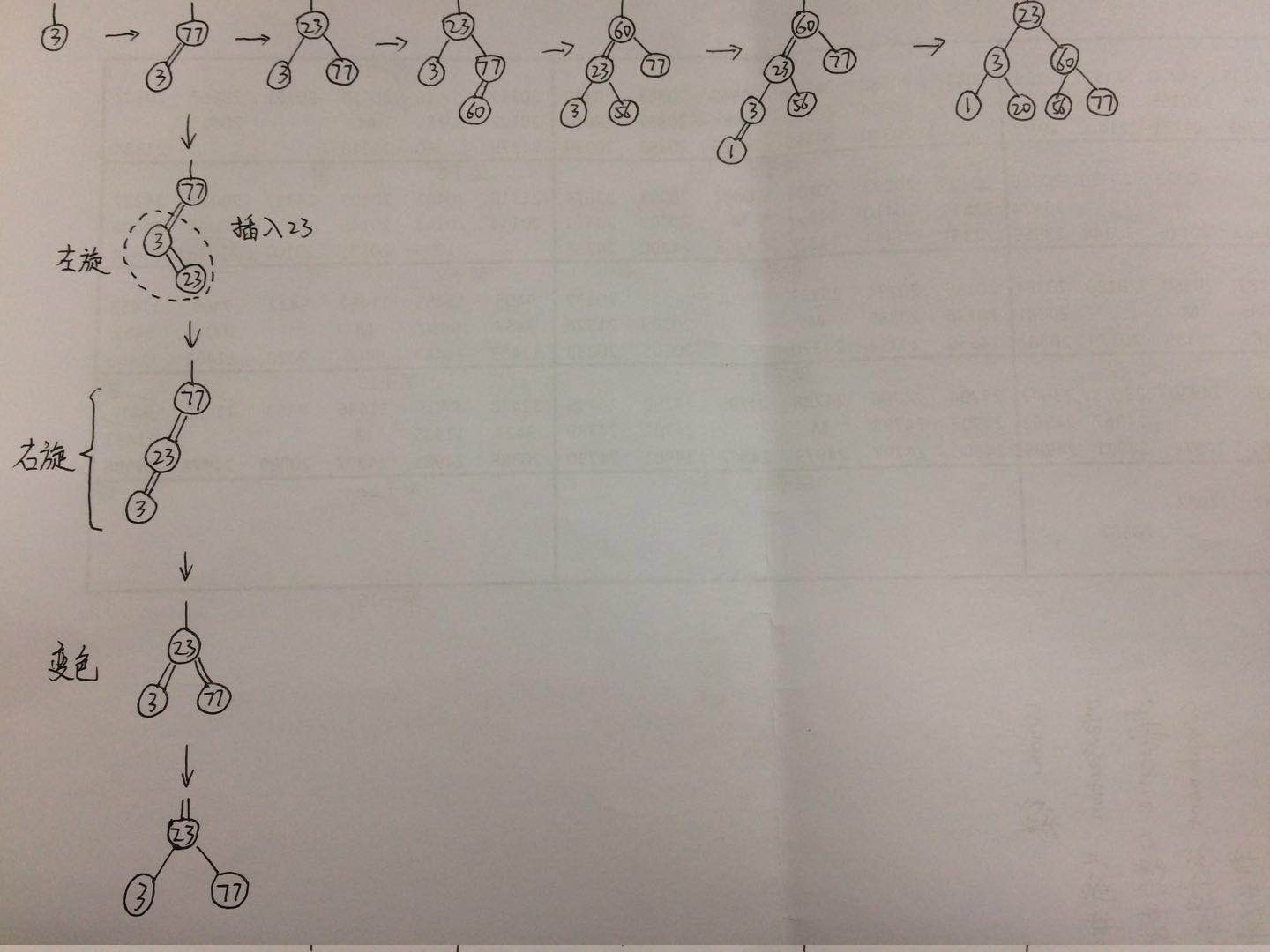

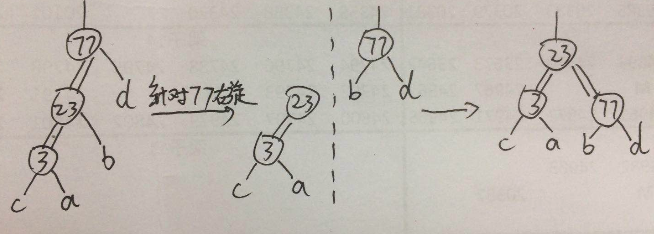
虽然上面介绍过右旋的操作是左子结点,而实际上在右旋操作发生时,是左子结点与其根结点的一个位置互换,同时将原根结点拉到右子结点的位置,右旋操作在代码中时针对一棵树,要传入该树的根结点,而不是传入一棵树中的一个子结点,因此右旋操作子树的根结点,为77,具体分析如下图:
根据上面的分析,由于红黑树属于二叉查找树,不涉及结点颜色的方法均可以复用BST,而红黑树保证了结构的完美平衡,查找get方法也可以直接复用BST的方法即可发挥最大效率。然而插入和删除因为要匹配我们的新型红黑树结构,因此要复写get和remove方法。所以总结一下我们要编写的部分:
package algorithms.search.STImpl;
/**
* 红黑树
*
* @author Evsward
* @RedBlackTree 重写put,remove,提高BST效率。
* @BST 其他接口直接复用BST
* @param <Key>
* @param <Value>
*/
public class RedBlackBST<Key extends Comparable<Key>, Value> extends BST<Key, Value> {
private final static boolean RED = true;
private final static boolean BLACK = false;
private Node root;
/**
* 红黑树结点
*
* @notice 继承自BST的TreeNode,以期能够复用BST的公共方法。
* @author Evsward
*
*/
private class Node extends TreeNode {
private Node left, right;// 其左子右子结点
private boolean color;// 指向该结点的链接的颜色,红或黑
public Node(Key key, Value val, int size, boolean color) {
super(key, val, size);// 这三个属性直接复用父类即可,没有区别
this.color = color;
}
/**
* 以下两个set方法是必须的,因为要将每次set关联到基类的引用,以便于调用基类关于左右子的方法
* 当然了这些方法肯定是与color无关的,跟color有关的都需要自己实现。
*/
public void setLeft(Node left) {
this.left = left;
super.leftChild = left;// 关联到基类的引用
}
public void setRight(Node right) {
this.right = right;
super.rightChild = right;// 关联到基类的引用
}
@Override
public String toString() {// 方便调试,可以直观看到树结构
return "NODE key:" + this.key + " value:" + this.value + " size:" + this.size + " color:" + this.color
+ " \n leftChild:" + this.left + " rightChild:" + this.right;
}
}
/**
* 判断某结点的链接是否为红
*
* @param n
* 某结点
* @return
*/
private boolean isRed(Node n) {
if (n == null)
return false;// 如果是空结点,则为空链接,空链接默认为黑链接
return n.color == true;
}
/**
* 左旋转操作:具体请看上方左旋示意图,有详细解释
*
* @param h
* @return 左旋转后的树根结点
*/
private Node rotateLeft(Node h) {
Node x = h.right;// 先将右子寄存
h.setRight(x.left);
x.setLeft(h);
x.color = h.color;// 其他color均不变,只修改right和h互换颜色。
h.color = RED;
// 注意不要忘记right和h的size问题,也要互换。
x.size = h.size;
h.size = size(h.left) + size(h.right) + 1;
return x;
}
/**
* 右旋转操作:具体请看上方右旋示意图,有详细解释
*
* @param h
* @return 右旋转后的树根结点
*/
private Node rotateRight(Node h) {
Node x = h.left;// 寄存左子
// 链接修改
h.setLeft(x.right);// 断开链接,转移左子的右子
x.setRight(h);
// 颜色修改
x.color = h.color;
h.color = RED;
// 大小修改
x.size = h.size;
h.size = size(h.left) + size(h.right) + 1;
return x;
}
/**
* 颜色转换,将双子改为黑,根改为红
*
* @notice 插入操作时需要将红链接从下传到上。
* @param x
* 根结点
*/
private void flipColor(Node x) {
x.left.color = BLACK;
x.right.color = BLACK;
x.color = RED;
}
public void put(Key key, Value val) {
root = put(root, key, val);
root.color = BLACK;// 树的根结点的链接特例为黑。
}
/**
* 红黑树插入键的自我实现
*
* @param x
* 在红黑树某结点为根结点的子树中插入键
* @param key
* @param val
* @return 插入键调整以后的树
*/
private Node put(Node x, Key key, Value val) {
// 插入操作
if (x == null)
return new Node(key, val, 1, RED);// 新键采用红链接,才不会打破红黑树的完美黑色平衡
// 比较操作
int comp = key.compareTo(x.key);
if (comp < 0)
x.setLeft(put(x.left, key, val));// 插入到左子树
else if (comp > 0)
x.setRight(put(x.right, key, val));// 插入到右子树
else// 修改当前结点的值
x.value = val;
// 修复操作【这一步是与BST不同的,其他的步骤均一致】
if (isRed(x.right) && !isRed(x.left))
x = rotateLeft(x);
if (isRed(x.left) && isRed(x.left.left))
x = rotateRight(x);
if (isRed(x.left) && isRed(x.right))// 临时4-结点(包含三个键)
flipColor(x);
// 调整size
x.size = size(x.left) + size(x.right) + 1;
return x;
}
/**
* 向2-3-4树插入一个键
*
* @notice 在多进程可以同时访问同一棵树的应用中这个算法要优于2-3树。
* @param x
* @param key
* @param val
* @return
*/
@SuppressWarnings("unused")
private Node put234Tree(Node x, Key key, Value val) {
if (isRed(x.left) && isRed(x.right))// 临时4-结点(包含三个键)
flipColor(x);
// 插入操作
if (x == null)
return new Node(key, val, 1, RED);// 新键采用红链接,才不会打破红黑树的完美黑色平衡
// 比较操作
int comp = key.compareTo(x.key);
if (comp < 0)
x.setLeft(put(x.left, key, val));// 插入到左子树
else if (comp > 0)
x.setRight(put(x.right, key, val));// 插入到右子树
else// 修改当前结点的值
x.value = val;
// 修复操作【这一步是与BST不同的,其他的步骤均一致】
if (isRed(x.right) && !isRed(x.left))
x = rotateLeft(x);
if (isRed(x.left) && isRed(x.left.left))
x = rotateRight(x);
// 调整size
x.size = size(x.left) + size(x.right) + 1;
return x;
}
public void deleteMin() {
// 如果根结点的两个子结点均为黑,则需要将根结点置为红,以方便后续升4结点时不会破坏黑路径等值
if (!isRed(root.left) && !isRed(root.right))
root.color = RED;
root = deleteMin(root);
// 如果树不为空,树的根结点的链接特例为黑。
if (root.size > 0)
root.color = BLACK;
}
/**
* 局部构建,将结点x中双子改为红
*
* @notice 删除的操作与插入是相反的,它需要将红链接从上传到下。
* @param x
* @return
*/
private Node moveRed(Node x) {
x.left.color = RED;
x.right.color = RED;
x.color = BLACK;
return x;
}
/**
* 局部红黑树的删除
*
* @notice 最小键一定要与红色沾边(也就是3-结点键的一部分),否则删除一个2-结点会破坏红黑树的平衡
* (直接导致该2-结点被删除后接替的空链接到根节点路径上黑链接总数减一,与其他空链接不等)
* @param x
* 局部红黑树的根结点
* @return 删除最小键且调整回红黑树的根结点
*/
private Node deleteMin(Node x) {
if (x.left == null)
// x结点并无任何子结点,那么直接删除根结点,返回空树
if (x.right == null)
return null;
// x结点还存在比它大的右子结点,那么删除根结点,返回右子结点
else
return x.right;
// 首先x为根的局部树中,最小键肯定为x.left(x.left==null的情况上面已处理)。所以要对x.left是否与红沾边进行判断。
// 在分析x.left结点的时候,局部树的范围是x.left,x.left.right和x.left.left三个结点,若想让x.left与红沾边,这三个结点任意一个为红链接即可满足。
// 根据红黑树定义,初始情况下x.left.right不可能为红,所以只有判断当x.left和x.left.left都不为红时,对传入树进行调整。
if (!isRed(x.left) && !isRed(x.left.left))
x = moveRed(x);
// 调整结束,最小键x.left已经与红沾边,开始删除
x.setLeft(deleteMin(x.left));
// 删除完毕,开始修复红黑树结构。
return balance(x);
}
/**
* 修复红黑树。
*
* @param x
* @return
*/
private Node balance(Node x) {
// 以下为三种属于2-3树而不属于红黑树的特殊情况
if (isRed(x.right))
x = rotateLeft(x);
if (isRed(x.left) && isRed(x.left.left))
x = rotateRight(x);
if (isRed(x.left) && isRed(x.right))
flipColor(x);
x.size = size(x.left) + size(x.right) + 1;
return x;
}
public void deleteMax() {// 如果根结点的两个子结点均为黑,则需要将根结点置为红,以方便后续升4结点时不会破坏黑路径等值
if (!isRed(root.left) && !isRed(root.right))
root.color = RED;
root = deleteMax(root);
// 如果树不为空,树的根结点的链接特例为黑。
if (root.size > 0)
root.color = BLACK;
}
private Node deleteMax(Node x) {
if (x.right == null)
// x结点并无任何子结点,那么直接删除根结点,返回空树
if (x.left == null)
return null;
// x结点还存在比它小的左子结点,那么删除根结点,返回左子结点
else
return x.left;
// 首先x为根的局部树中,最大键肯定为x.right(x.right==null的情况上面已处理)。所以要对x.right是否与红沾边进行判断。
// 在分析x.right结点的时候,局部树的范围是x.right,x.right.right和x.right.left三个结点,若想让x.right与红沾边,这三个结点任意一个为红链接即可满足。
// 根据红黑树定义,初始情况下x.right.right不可能为红,所以只有判断当x.right和x.right.left都不为红时,对传入树进行调整。
if (!isRed(x.right) && !isRed(x.right.left))
x = moveRed(x);
// 调整结束,最大键x.right已经与红沾边,开始删除
x.setRight(deleteMax(x.right));
// 删除完毕,开始修复红黑树结构。
return balance(x);
}
public void remove(Key key) {
if (!isRed(root.left) && !isRed(root.right))
root.color = RED;
root = remove(root, key);
// 如果树不为空,树的根结点的链接特例为黑。
if (root.size > 0)
root.color = BLACK;
}
private Node remove(Node x, Key key) {
if (key.compareTo(x.key) < 0) {
if (!isRed(x.left) && !isRed(x.left.left))
x = moveRed(x);
x.setLeft(remove(x.left, key));
} else {
if (isRed(x.left))
x = rotateRight(x);
if (key.compareTo(x.key) == 0 && (x.right == null))
return null;
if (!isRed(x.right) && !isRed(x.right.left))
x = moveRed(x);
if (key.compareTo(x.key) == 0) {
x.value = get(x.right, min(x.right).key);
x.key = min(x.right).key;
x.setRight(deleteMin(x.right));
} else {
x.setRight(remove(x.right, key));
}
}
return balance(x);
}
/**
* 以下方法内部只需调用父类方法即可
*
* @notice 因为要对红黑树的根root操作,所以复写下面方法是必要的。
*/
public Value get(Key key) {
return get(root, key);
}
public int size() {
return size(root);
}
public Iterable<Key> keySet() {
return keySet(root);
}
public Key min() {
return min(root).key;
}
public Key max() {
return max(root).key;
}
public Key select(int k) {
return selectNode(root, k).key;
}
public int getRank(Key key) {
return getRank(root, key);
}
public Key ceiling(Key key) {
TreeNode x = ceiling(root, key);// 最终也没找到比它大的,这个key放在表里面是最大的
if (x == null)
return null;
return x.key;
}
public Key floor(Key key) {
TreeNode x = floor(root, key);
if (x == null)// 最终也没找到比它小的,这个key放在表里面是最小的
return null;
return x.key;
}
}
经过批量测试结果为:
13:40:17[testSTBatch]: ------开始批量测试------
13:40:17[getBean]: class: algorithms.search.second.SequentialSearchST
13:40:17[testST]: 总耗时:341ms
13:40:17[getBean]: class: algorithms.search.second.BinarySearchST
13:40:17[testST]: 总耗时:42ms
13:40:17[getBean]: class: algorithms.search.second.BST
13:40:17[testST]: 总耗时:18ms
13:40:17[getBean]: class: algorithms.search.second.RedBlackBST
13:40:17[testST]: 总耗时:27ms
13:40:17[testSTBatch]: ------批量测试成功!------当我把查询次数翻8倍,结果变成:
08:51:55[testSTBatch]: ------开始批量测试------
08:51:55[getBean]: class: algorithms.search.STImpl.SequentialSearchST
08:51:57[testST]: 总耗时:1706ms
08:51:57[getBean]: class: algorithms.search.STImpl.BinarySearchST
08:51:57[testST]: 总耗时:56ms
08:51:57[getBean]: class: algorithms.search.STImpl.BST
08:51:57[testST]: 总耗时:67ms
08:51:57[getBean]: class: algorithms.search.STImpl.RedBlackBST
08:51:57[testST]: 总耗时:35ms
08:51:57[testSTBatch]: ------批量测试成功!------红黑树的性能测试时间与二叉查找树的非常接近,但是可以看出的是随着查询次数增加,红黑树的执行时间稳定上涨,效率方面很快就超过了普通二叉查找树。我们具体去分析一下这其中的原理,测试算法性能最耗时的部分在插入和查找,经过上面的文字分析与代码展示,红黑树的插入算法其实是要比BST多出一部分左旋、右旋,变色的修复红黑树的过程,这个过程会让红黑树的效率不如BST。然而我们都知道,数据一次被插入,却可能会被查找无数次,而虽然红黑树与BST使用的get方法是同一个,但是由于红黑树修复维护的是完美黑色平衡的BST,因此在查找过程中会比BST高效,红黑树始终会保持高度为小于2lg2N,而BST最差情况可能达到N,在这种情况下,红黑树的效率要远超BST。经过多次查找操作以后,红黑树在插入方面损失的一点效率早已被抹平甚至远超于BST。
这里再补充上有序表API的测试结果:
14:00:30[testSSTBatch]: ------开始批量测试------
14:00:30[getBean]: class: algorithms.search.second.RedBlackBST
14:00:30[testSSTBatch]: ------批量测试成功!------我们的RedBlackBST也通过了有序表API的测试。
终于要分析查找算法的终极大魔王:散列表。
先陈列概念,后面会详细解释,
基于一个数组实现的无序符号表,将键作为数组的索引而数组中键i处储存的就是它对应的值,在此基础上,散列表能够处理更加复杂的类型的键。
散列表是算法在时间和空间上做出权衡的经典例子。
如果没有内存限制,我们可以直接将键作为数组索引,将他们全部新键一个索引存入内存,那么所有查找操作只需要访问内存一次即可完成。这种情况当键很多时,需要内存非常大。另一方面,如果没有时间限制,可以使用无序数组并进行顺序查找,每次只需要从数据库中依次取出一位进行比较,这样就只需要一个位置的内存而已。而散列表使用了适度的空间和时间并在这两个极端之间找到了一种平衡。而且奇妙的是,我们只需要调整散列算法的参数就可以在空间和时间之间做出取舍。
立个flag,使用散列表,可以实现在一般应用中拥有常数级别的查找和插入操作的符号表。这使得散列表在很多情况下成为实现简单符号表的最佳选择。
接下来,我们将会一一验证。
对于每种类型的键,我们都需要一个与之对应的散列函数,以此获得一个散列值。
在java中,每种数据类型都需要相应的散列函数,所以他们都继承了一个能够返回一个32位整数的hashCode()方法。每一种数据类型的hashCode()方法必须与equals()方法一致。默认情况下,equal方法就是通过比较两个相同数据类型的值的hashcode是否一致,而这个hashcode是通过调用hashCode方法获取到的,如果一致才表示相等,返回true。这也就说明了,如果我们要为自定义的数据类型定义散列函数,需要同时重写hashCode()和equals()两个方法。
散列函数:如果我们有一个能保存M个键值对的数组,那么就需要一个能够将任意键转化为该数组范围内的索引[0,M-1]的散列函数。
正如在排序算法中的散列桶,他们有着相同意义的散列函数,我们对散列函数的要求是易于计算且能够均匀分布所有的键。
散列也是一个数据压缩的过程,通过散列,我们不仅获得了一个可供快速查询的散列表(索引),也将原数据进行了压缩,甚至加密,因为在解压缩的时候,或者解密的时候,要使用相同的散列函数逆向获得源数据。散列值所在的散列表(也是索引表)应该是一个连续的内存存储空间,这个存储空间称为散列地址。
如果我们想保留一个长度为M的数组,用来存储待处理数据,中间这个散列函数可以使用除留余数法,也就是在待处理数据中使用任意一个值k除以R,R小于等于M,一般来说R最好是素数(除了1和自身,不会被其他自然数整除)或者M本身,如果R选得不好,会出现很多重复元素。保留余数作为其散列值存入长度为M的数组内。通过除留余数法,我们可以将数据划分到[0,M-1]这个区间里。这是常见的散列函数。
k%R = hash
如果数据不是正整数,上面的公式就不能成立,如果键是0-1之间的实数,我们可以将它乘以M并四舍五入得到一个[0,M-1]区间的索引值。
相应的,针对字符串以及组合键,都可以通过散列函数来处理,但散列函数永远不是死的,需要你根据实际数据情况去设计,一般来讲最终都会依赖除留余数法,但显然它肯定不是最具智慧的部分。
上面在散列表定义时也提到过,散列算法的要注意两件事,一个是如何将键转化为索引值,另一个就是避免碰撞。根据散列函数的一致性,相等的键一定会产生相等的散列值,但是我们不允许存在重复的键,那么,不同的键经过散列函数处理以后是否一定产生不同的散列值呢?
答案是否定的。当我们使用散列函数的时候,有很大可能结果会出现重复数据,也就是说不同的键可能经过散列函数以后拥有了相同的散列值,这时equals方法会默认认为他们是相等的,这就发生了散列的碰撞,也叫做冲突。
例如101和201经过除留余数法,而R恰好选的是10,数组长度就是10,这时候这两个值的散列值都为1,而显然101不可能等于201。因此,处理碰撞的能力是散列函数必备的另一种能力,如果说散列数据是进攻的武器,那么处理碰撞就是防守武器,攻防两端均不落下风,才是优秀的散列算法。
前面提到了两种处理碰撞的方法,一种是拉链法,一种是线性探测法。
将大小为M的数组中的每个元素指向一条链表,链表中的每个结点都存储了散列值为该元素的索引的键值对。
这非常类似与排序算法中计数排序,基数排序以及桶排序的思想。这个方法的基本思想就是选择足够大的M,使得所有链表都尽可能短以保证高效的查找。查找时首先根据散列值找到对应的链表,然后再沿着链表顺序查找相应的键。这与桶排序非常类似,想了解桶排序的朋友请转到面向程序员编程——精研排序算法搜索“桶排序”即可找到。
package algorithms.search.STImpl;
import java.util.ArrayList;
import java.util.List;
import algorithms.search.SFunction;
/**
* 基于拉链法的散列表
*
* @notice 处理碰撞 将散列值相同的key(但实际上key是不同的)存入一个链表,而整个散列表容器是一个链表数组
* @author Evsward
*
* @param <Key>
* @param <Value>
*/
public class ChainHashST<Key, Value> implements SFunction<Key, Value> {
private int N;// 键值对总数(等于散列表上每个单链表的元素个数之和)
private int M;// 散列表长度(也就是M条链表,只不过有的链表只有一个元素,有的有多个元素)
private SequentialSearchST<Key, Value>[] st; // 单链表数组
public ChainHashST() {
this(997);// 初始化定义一个素数为链表数组长度
}
@SuppressWarnings("unchecked")
/**
* 构建一个长度为M的链表数组,并且为链表数组的每一个位置开辟内存空间。
*
* @param M
*/
public ChainHashST(int M) {
this.M = M;
// 注意:new SequentialSearchST<Key, Value>[M]这样是报错的,因为java不允许泛型数组。
st = new SequentialSearchST[M];
for (int i = 0; i < M; i++) {
st[i] = new SequentialSearchST<Key, Value>();
}
}
/**
* 获得散列值
*
* @param key
* @return
*/
private int hash(Key key) {
// 32位整型值,去掉标志位留31位使用
return (key.hashCode() & 0x7fffffff) % M;
}
@Override
public int size() {
int size = 0;
for (int i = 0; i < M; i++) {
size += st[i].size();
}
N = size;
return N;
}
@Override
public Value get(Key key) {
return st[hash(key)].get(key);
}
@Override
public void put(Key key, Value val) {
st[hash(key)].put(key, val);
}
@Override
public Iterable<Key> keySet() {
List<Key> result = new ArrayList<Key>();
for (int i = 0; i < M; i++) {
result.addAll((List<Key>) st[i].keySet());
}
return result;
}
@Override
public void remove(Key key) {
for (Key k : keySet()) {
if (key.equals(k)) {
// st[hash(k)]取的是链表数组下标为当前键的哈希值的链表元素,该链表包含那些哈希相等但是key不同的键
// 这里是按照key删除,key不会重复
st[hash(k)].remove(key);
}
}
}
}
测试输出结果为:
16:41:07[testSTBatch]: ------开始批量测试------
16:41:07[getBean]: class: algorithms.search.STImpl.SequentialSearchST
16:41:09[testST]: 总耗时:1817ms
16:41:09[getBean]: class: algorithms.search.STImpl.BinarySearchST
16:41:09[testST]: 总耗时:62ms
16:41:09[getBean]: class: algorithms.search.STImpl.BST
16:41:09[testST]: 总耗时:159ms
16:41:09[getBean]: class: algorithms.search.STImpl.RedBlackBST
16:41:09[testST]: 总耗时:36ms
16:41:10[getBean]: class: algorithms.search.STImpl.ChainHashST
16:41:10[testST]: 总耗时:9ms
16:41:10[testST]: class: java.util.HashMap
16:41:10[testST]: 总耗时:5ms
16:41:10[testSTBatch]: ------批量测试成功!------因为ChainHashST并不属于有序表,因此只对其进行ST测试。通过结果发现,我们新写的ChainHashST即使算上各种详细的注释也只有90行左右,但效率却是十分惊人的。与JDK的Map作对照,似乎也不差。远超所有二分查找算法家族。其实ChainHashST的代码实现非常简单,要做的就是处理好哈希部分的内容,其余关于符号表的具体方法全部重用SequentialSearchST顺序查找。如果只用SequentialSearchST顺序查找的话,效率是所有算法中最低的,但是如果通过ChainHashST将数据散列,存入哈希相同key不同的数据到每个单链表,单链表内仍旧使用顺序查找,随着数据的散列越来越均匀,顺序查找的单链表会越来越短,每一条链表的遍历就会更加高效,合起来整个拉链散列表的效率也变得更高。最终竟超越了实现复杂的二分算法家族。可喜可贺。
对于ChainHashST,我们要引起注意的是在对其构造初始化时,我们指定了链表数组的大小为997(使用一个素数当做数组大小,避免了与原数据产生很多公约数的情况,可以使数据散列更加均匀),取得了不错的实验效果。通过这些内容,毋庸置疑的是,在实现基于拉链法的散列表时,我们的目标是选择适当的数组大小M,既不会因为空链表而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间。如果存入的键多于初始大小,查找所需的时间只会比选择更大的数组稍长,如果少于预期,虽然有些空间浪费但是查找会非常快,以空间换取时间。如果我们的内存资源不是很紧张,大可选择一个足够大的M,但这里一定要注意,M并不是越大越好,当M远大于你数据使用空间的时候,在如此大的M中去遍历也是一件耗神的事,会增加性能负担,因此选择M是个技术活。
散列最主要的目的在于均匀地将键散布开来,因此在计算散列后键的顺序信息就丢失了,如果你需要快速找到最大或者最小的键,或是查找某个范围内的键,或是实现SSFunction中关于有序符号表的任何其他方法,散列表都不是合适的选择,因为这些操作的运行时间都是线性的。对于ChainHashST,它的实现足够简单,在键的顺序并不重要的应用中,它可能是最快的(也是使用最广泛的)符号表实现。当使用java的内置数据类型作为键,或是在使用含有经过完善测试的hashCode方法的自定义类型作为键时,它都能提供快速而方便的查找和插入操作。
使用大小M的数组保存N个键值对时,M>N。我们的空位会比数据多,利用这些空位解决碰撞冲突,基于这种策略的所有方法被统称为开放地址散列表。
开放地址散列表的核心思想是,同样的内存大小,宁可将他们多多分配到散列表上面,即使是空元素,也不要过多分给链表,这是好理解的,散列表的夙愿也正是如此。
线性探测法是开放地址散列表中最简单的方法。
当碰撞发生时,去检查散列表中碰撞的下一个位置,检查的结果有:1,命中,找到键;2,未命中,键为空,停止查找;3,键不等,继续查找。
探测:查找到数组结尾时折回数组开头继续查找,直到遇到空键或者找到该键为止。这种操作被称为探测。与比较些许不同之处在于探测有时只是在测试键是否为空。
package algorithms.search.STImpl;
import java.util.ArrayList;
import java.util.List;
import algorithms.search.SFunction;
/**
* 基于线性探测的符号表
*
* @connect BinarySearchST,resize实现,平行数组,均十分类似,而且也可以对插入的键实现自动排序
* 并且先进的是这里的Key并不需要继承Comparable接口,因为它不是靠比较大小,而是比较哈希值是否相等。
* @author Evsward
*
* @param <Key>
* @param <Value>
*/
public class ProbeHashST<Key, Value> implements SFunction<Key, Value> {
private Key[] keys;// 键数组
private Value[] vals;// 值数组
private int N;// 符号表中键值对的总数,N是很小于M的
private int M;// 散列表大小,M有很多空元素
@SuppressWarnings("unchecked")
public ProbeHashST() {
this.M = 1;// 初始化将散列表长度设置为16,定下来以后就不能变了
keys = (Key[]) new Object[M];
vals = (Value[]) new Object[M];
}
@SuppressWarnings("unchecked")
public ProbeHashST(int Cap) {
this.M = Cap;
keys = (Key[]) new Object[M];
vals = (Value[]) new Object[M];
}
/**
* 获得散列值
*
* @param key
* @return
*/
private int hash(Key key) {
// 获取key的哈希值为一个32位整型值,去掉标志位留31位使用,通过除留余数法获得散列值
return (key.hashCode() & 0x7fffffff) % M;
}
/**
* 数组增容减容
*
* @notice 复制于BinarySearchST 稍作调整。
* @param 数组容量大小
*/
public void resize(int cap) {
// 先创建一个新的容量的空散列表
ProbeHashST<Key, Value> t = new ProbeHashST<Key, Value>(cap);
for (int i = 0; i < M; i++) {// 遍历当前的存储数据的散列表
/**
* 神奇之处在于每次resize,都会将数据重新按照新的长度计算哈希存入容器。
*
* @性能 但是每次resize都会触发重新遍历的put,会消耗性能,但是随着样本规模增大,resize的次数变少,性能影响会越来越小
*/
if (keys[i] != null)
// 将原数据依次重新put到新容量的空散列表中(会按照新的空散列表进行hash算法,所以数据位置会发生变化)
t.put(keys[i], vals[i]);
}
keys = t.keys;
vals = t.vals;
M = t.M;
}
@Override
public int size() {
return N;
}
@Override
public Value get(Key key) {
/**
* 由于我们的插入机制,逆向思考在查找key的时候,是从hash(key)下标开始找,命中即找到,不等则继续往下找,遇到空了说明没有。
*/
for (int i = hash(key); keys[i] != null; i = (i + 1) % M) {
if (keys[i].equals(key)) {// 命中key,返回val
return vals[i];
}
/**
* 不等则继续循环
*/
}
/**
* 循环终止,说明遇到空元素了,根据插入机制,那就代表整个数组都不含有该key
*/
return null;
}
@Override
public void put(Key key, Value val) {
if (N >= M / 2)
resize(2 * M);// M要保证至少内部N的占有率为25%到50%之间。(与BinarySearchST操作相同)
int i;
/**
* @notice hash(key)是可以重复的,也就是碰撞位置,而key是不可重复的,是主键。
* @具体探测方法: 初始化为传入key的散列值,探测其是否相等、为空或者不等,相等则更新值,为空则插入值,不等则继续查找。
*/
for (i = hash(key); keys[i] != null; i = (i + 1) % M) {
if (keys[i].equals(key)) {
vals[i] = val;// 命中key,更新val,直接退出循环,退出方法。
return;
}
/**
* 不等则循环继续
*/
}
// 从循环出来只有一种情况,就是keys[i]==null,则在当前i位置添加键值对。
keys[i] = key;
vals[i] = val;
N++;
}
@Override
public Iterable<Key> keySet() {
List<Key> list = new ArrayList<Key>();
for (int i = 0; i < M; i++) {
if (keys[i] != null) {// 剔除空元素
list.add(keys[i]);
}
}
return list;
}
@Override
public void remove(Key key) {
for (int i = hash(key); keys[i] != null; i = (i + 1) % M) {
if (keys[i].equals(key)) {// 命中key,开始删除
keys[i] = null;
vals[i] = null;
N--;
if (N <= M / 4) {// 如果键值对数据比容器的25%小的时候,容器减容一倍。(与BinarySearchST操作相同)
resize(M / 2);
}
return;
}
/**
* 不等则继续循环
*/
}
/**
* 未命中key不做任何操作
*/
}
}
测试输出结果:
13:02:41[testSTBatch]: ------开始批量测试------
13:02:41[getBean]: class: algorithms.search.STImpl.SequentialSearchST
13:02:43[testST]: 总耗时:1703ms
13:02:43[getBean]: class: algorithms.search.STImpl.BinarySearchST
13:02:43[testST]: 总耗时:65ms
13:02:43[getBean]: class: algorithms.search.STImpl.BST
13:02:43[testST]: 总耗时:92ms
13:02:43[getBean]: class: algorithms.search.STImpl.RedBlackBST
13:02:43[testST]: 总耗时:53ms
13:02:43[getBean]: class: algorithms.search.STImpl.ChainHashST
13:02:43[testST]: 总耗时:16ms
13:02:43[getBean]: class: algorithms.search.STImpl.ProbeHashST
13:02:43[testST]: 总耗时:8ms
13:02:43[testST]: class: java.util.HashMap
13:02:43[testST]: 总耗时:7ms
13:02:43[testSTBatch]: ------批量测试成功!------可以看出,最新的ProbeHashST的速度是比较可观的,经过我多次测试甚至超过了HashMap的效率,这虽然跟源数据内容的结构有很大关系,但至少说明线性探测散列表已经与专家们实现的HashMap属于一个性能量级上了(稍后会详细解释)。然而,ProbeHash并不是有序的,我们可以通过其内部的debug log看到:
2017/11/17 13:02:43 [main] INFO tools.XMLUtil - class: algorithms.search.STImpl.ProbeHashST
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - -----功能测试-----
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - sst.put(3, fan) --- sst.size() = 1
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - sst.put 77,32,65,256 --- sst.size() = 5
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - sst.put(1, lamp) --- sst.size() = 6
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - sst.put(20, computer) --- sst.size() = 7
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - sst.delete(20) --- sst.size() still= 7
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - -----①遍历当前集合【观察输出顺序】-----
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - 32...idea
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - 65...cup
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - 256...plane
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - 3...fan
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - 1...lamp
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - 20...book
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - 77...eclipse
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - -----②测试表头中尾删除-----
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - sst.remove(20)...【有序表中删除,顺序表头删除】
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - sst.get(20) = null --- sst.size() = 6
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - sst.remove(1)...【有序表头删除,顺序表中删除】
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - sst.get(1) = null --- sst.size() = 5
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - sst.remove(77)...【有序表尾删除】,顺序表中删除
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - sst.get(77) = null --- sst.size() = 4
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - sst.remove(3)...有序表中删除,【顺序表尾删除】
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - sst.get(3) = null --- sst.size() = 3
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - -----③遍历当前集合-----
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - 32...idea
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - 65...cup
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - 256...plane
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - -----性能测试-----
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - 0-6321...sst.size() = 6321
2017/11/17 13:02:43 [main] INFO algorithms.search.VIPClient - 总耗时:8ms
2017/11/17 13:02:43 [main] DEBUG algorithms.search.VIPClient - 测试成功!在第一次遍历集合的位置,可以看到我们put进去的数据并不是有序排列的,但也并不是完全无序的状态,经过我的调试与分析,他们比较的是余数的大小,也就是说除留余数法,如果按照余数排列的话,那是有序的,其实不证自明,因为余数就是哈希值,而哈希值就是键数组的下标,下标虽然不一定是连续的,但一定是有序的。
因此,如果我们的源数据全部都是素数并且我们的M比他们的最大值还要大,这时候插入线性探测散列表,他们一定是有序的。
当然了,如果是以上这种情况的话,我们也没必要使用散列函数了,直接使用键作为散列值了,但是这样一来,就成了有序表的查找,效率还不如二分查找,这个轮回大家听懂了吗 =_=
线性探测散列表不需要我们预先计算一个M来设置给它,而是通过resize去伸缩变换,resize当然会消耗一定的性能,但还是那句话——空间和时间的权衡。而拉链散列表也可以使用resize方法,但是大多时候,这个M是可以预先算出来的,所以也不必要再使用resize,毕竟resize也是会消耗一部分性能的。
散列表是高效的,通过我们的测试数据就可以直观的看出,它的执行效率远远超过其他查找算法。然而散列表也有自己的弱点:
这一篇博文我写了半个月,篇幅垒长,但是也有一个好处在于你不用去按照什么“查找算法(一),查找算法(二)...”去挨个研究了,查找算法看这一篇文章就可以研究透彻了,这也是我的风格与习惯。下面我来总结一下这些查找算法。总共介绍到了无序表的顺序查找,有序表的二分查找,二分查找树,红黑树以及散列表,在这些查找算法中,很多是为了学习的铺垫,而在实际工作中,往往只需要在散列表和二叉查找树之间选择即可。那么我就重点说说散列表和二叉查找树该如何选择?
前面是播种知识的种子和培育知识的幼苗,下面则是丰收的阶段。我知道播种和培育阶段已经耗费了我们大量的精力,但是还是要踏实下来去迎接丰收的喜悦,否则自己种的粮食烂在了地里暴殄天物。
告诉你一个惊人的消息,我们的努力没有白费,或者说是白费了。因为jdk中java.util.TreeMap就是使用的红黑树实现的,是有序的,而java.util.HashMap使用的是散列表,是无序的。通过这一篇文章的深入学习,以后任何关于TreeMap和HashMap相关的问题,我们都可以直接从底层去深入的思考。TreeMap没有直接实现rank(),select()和我们的有序符号表API中的一些其他方法,但它支持一些能够高效实现这些方法的操作。而HashMap与我们刚才实现的ProbeHashST基本相同,它也会动态调整数组的大小来保持使用率大约不超过75%,这也是上面我卖的那个关子,在这里得到解决。
关于SET,在大师的小玩具——泛型精解搜索“SET容器”即可了解set与泛型的联用的知识,以及Set的一些操作。Set,也叫集合,与我们在初中数学学习的集合是相同的概念,也就是说set里面也会有并集、交集、差集、补集的操作。针对符号表来说,如果不去管值,只需要将键插入表中并检测一个键是否在表中存在(我们是不允许重复键的),这就可以转化为SET。
只要忽略关联的值,或者使用一个简单类封装,就可以将任何符号表的实现变成一个SET类的实现。在JDK中,正如我们突然精通了TreeMap和HashMap一样,我们也可以捎带脚把TreeSet和HashSet解决掉。TreeSet仍旧是使用红黑树实现的,也可以自动键有序,而HashSet也名副其实,就是哈希算法实现的Set,效率特性各方面都与HashMap很相似,也是操作无序表的集合。
这些名单可能非常巨大,输入无限并且响应时间要求非常严格,我们已经学过的符号表实现能够很好地满足这些需求。
| 应用领域 | 键 | 值 |
|---|---|---|
| 电话黄页 | 人名 | 电话号码 |
| 字典 | 单词 | 定义 |
| 账户信息 | 账号 | 余额 |
| 基因组 | 密码子 | 氨基酸 |
| 实验数据 | 数据/时间 | 实验结果 |
| 编译器 | 变量名 | 内存地址 |
| 文件共享 | 文件名 | 文件内容的地址 |
| DNS | 网站 | IP地址 |
字典类就是标准的一对一键值对,而当我们遇到一对多的时候,就需要用到索引,这正如我们上面介绍的拉链散列表,key虽然是不重复的,但是他们的散列值有可能重复,所以一个散列值对应一条链表,这条链表中可以存储多个结点内容,这时候,这个散列值就是索引。所以索引就是用来描述一个键和多个值相关联的符号表。下面具体举例说明:
公司使用客户账户来跟踪一天内所有交易的一种方法是为当日交易建立一个索引,其中键是客户的账号,值是和该账号有关的所有交易,也就是说,有了这个索引,我们不需要再从大数据中大海捞针,而只需在这预先填充进来的与我们相关的索引表中搜索即可。
当你输入一个关键字并得到一系列含有这个关键字的网站时,就是在利用网络搜索引擎创建的索引。每个键都关联着一个值,即一个关键字对应一组网页。
互联网电影数据库中,每一行都含有一部电影的名称,即为键,随后是在其中出演的演员列表(一组值)。
与索引反过来,使用值来查找键的操作。互联网电影数据库,在上文的例子中,索引是将每部电影和它的演员们关联起来。它的反向索引则会将每个演员和他出演过的所有电影相关联。
科学或是工程领域能够将运行效率提升一千亿倍的发明极少——我们已经在几个例子中看到,符号表做到了,并且这些改进的影响非常深远。
标签:his zip 有关 语句 注意 两种方法 详细 hub 整合
原文地址:http://www.cnblogs.com/Evsward/p/search.html