标签:get 个人 域名 提取 int 分享 token ges cookies
介绍下:
补天是国内知名的漏洞响应平台,旨在企业和白帽子共赢。
白帽子在这里提交厂商漏洞,获得库币和荣誉,厂商从这里发布众测、获取漏洞报告和修复建议。
在2017年3月份之前,补天的厂商域名URL是非常好爬取的,即使没有登陆到平台依然可以用轻松获取到批量的厂商URL地址,然后白帽子用大型漏洞扫描工具进行批量漏扫。
后来,补天平台可能为了尽可能的保护厂商的URL被滥用,采取了一些措施。
这些措施限定了:
1). 必须登陆到平台
2). 点击厂商名并进入提交漏洞页面
3). 只在提交页面显示厂商URL域名
下面,就以一段Python 代码来获取最新的补天厂商URL,之后如何利用就随读者个人意愿了。
介绍:
1. 先登陆补天平台,复制Cookie到代码中的位置
2. 这里只演示爬取前三页,每页30个厂商
3. 使用正则提取URL
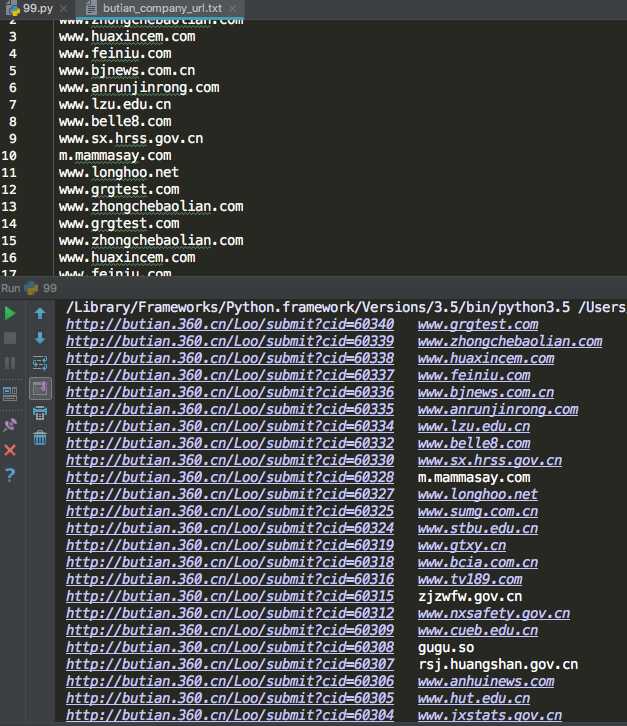
4. 爬取结果保存在脚本同级目录的 ‘butian_company_url.txt‘ 文件,如果不够90个URL,可能是有的厂商没有填写(即空)
import requests,re,json,time
head = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.130 Safari/537.36‘}
cook = {"Cookie": "这里写你登陆补天后的Cookie"}
url = ‘http://butian.360.cn/Reward/pub‘
for page in range(1,3): #前三页
data = {‘s‘: ‘1‘, ‘p‘: page, ‘token‘: ‘‘}
html = requests.post(url, headers = head, data=data, cookies = cook).content
jsCont = json.loads(html.decode())
jsData = jsCont[‘data‘]
for i in jsData[‘list‘]:
linkaddr = ‘http://butian.360.cn/Loo/submit?cid=‘ + i[‘company_id‘]
print(linkaddr,end=‘\t‘)
shtml = requests.get(linkaddr,headers = head, cookies = cook).content
#正则模版<input class="input-xlarge" type="text" name="host" placeholder="请输入厂商域名" value="www.grgtest.com" />
company_url = re.findall(‘<input class="input-xlarge" type="text" name="host" placeholder="请输入厂商域名" value="(.*)" />‘,shtml.decode())
time.sleep(0.5) # 控制爬取速度
print(company_url[0])
com_url = company_url[0]
with open(‘butian_company_url.txt‘,‘a+‘) as f:
f.write(com_url + ‘\n‘)
运行结果:
Python 爬虫练习(二)爬取补天公益SRC厂商域名URL (2017年11月22日)
标签:get 个人 域名 提取 int 分享 token ges cookies
原文地址:http://www.cnblogs.com/i-honey/p/7878729.html