标签:str -o 利用 src int 技术分享 pat strong enc
1、字符串合并和连接
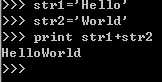
加号合并
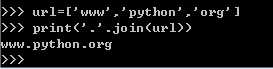
join方法合并
2、相乘和切片
line=‘*‘*30
print(line)
>>******************************
切片:
consequence[start_index:end_index:step]
表示第一个元素,正索引位置默认为0;负索引位置默认为-len(consequence)
end_index表示最后一个元素对象,正索引位置默认为len(consequence)-1;负索引位置默认为-1
print str[0:3]#截取第一位到第三位的字符 print str[:]#截取字符串的全部字符 print str[6:]#截取第七个字符到结尾 print str[:-3]#截取从头开始到倒数第三个字符之前的不包括第三个 print str[2]#截取第三个字符 print str[-1]#截取倒数第一个字符 print str[::-1]#创造一个与原字符串顺序相反的字符串 print str[-3:-1]#截取倒数第三位到倒数第一位之前的字符 不包括倒数第一位字符 print str[-3:]截取倒数第三位到结尾 print str[:-5:-3]逆序截取
三字符串的分割
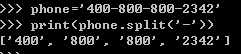
普通的分割,用split,不支持多个分隔
复杂的分隔
r表示不转义,分隔符可以是;或者,或者空格后面跟0个多个额外的空格,然后按照这个模式去分割

split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
import re
p = re.compile(r‘\d+‘)
print p.split(‘one1two2three3four4‘)
### output ###
# [‘one‘, ‘two‘, ‘three‘, ‘four‘,
4、字符串的开头和结尾的处理
例如查找一个文件名以什么开头或以什么结尾
filename=‘trace.h‘
print(filename.endwith(‘h‘))
>>True
print(filenam.startwith(‘trace‘))
>>True
5、字符串的查找和匹配
一般查找:
在长字符串里面查找字符串,会返回字符串所在字符串的索引,否则返回-1
str.find(‘xxxx‘)
复杂的匹配:
使用import re
6、字符串的替换
普通的替换:replace
str.replace(‘被替换者‘,‘替换着‘)
复杂替换
使用正则匹配的re.sub
7、字符串去掉一些字符
去除空格 对文本处理的时候比如从文件读取一行,然后去除每一行的两侧空格,tab或者换行符
line=‘ Congratulations, you guessed it. ‘
print(line.strip())
>>Congratulations, you guessed it.
注意:字符串内部的空格不能去掉,若要去掉需要用re模块
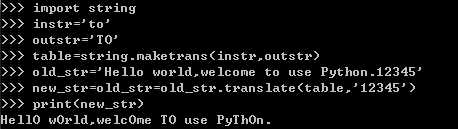
复杂的文本清理,可以利用str.translate,
先构建一个转换表,table是一个翻译表,表示把‘t‘‘o‘转成大写的‘T‘ ‘O‘,
然后在old_str里面去掉‘12345‘,然后剩下的字符串再经过table翻译
标签:str -o 利用 src int 技术分享 pat strong enc
原文地址:http://www.cnblogs.com/maplered/p/7879986.html