标签:没有 上层 添加内容 多核 实时 情况下 允许 对象 解释器
内存基本概念
内存的生命周期:
1、分配所需的内存
2、内存的读与写
3、不需要时将其释放
所有语言的内存生命周期都基本一致,不同的是最后一步在低级语言中很清晰,但是在像JavaScript 等高级语言中,这一步是隐藏的、透明的。
js的内存生命周期:
1、定义变量时就完成了内存分配
2、使用值的过程实际上是对分配内存进行读取与写入的操作。读取与写入可能是写入一个变量或者一个对象的属性值,甚至传递函数的参数。
3、而内存的释放而依赖GC机制(高级语言解释器嵌入的“垃圾回收器”)。
程序运行的时候,需要内存空间存放数据。一般来说,系统会划分出两种不同的内存空间:一种叫做栈(stack),另一种叫做堆(heap)。
堆(heap)与栈(stack)
heap是没有结构的,数据可以任意存放。heap用于复杂数据类型(引用类型)分配空间,例如数组对象、object对象。
一般来说,每个线程分配一个stack,每个进程分配一个heap,也就是说,stack是线程独占的,heap是线程共用的。此外,stack创建的时候,大小是确定的,数据超过这个大小,就发生stack overflow错误,而heap的大小是不确定的,需要的话可以不断增加。

stack是有结构的,每个区块按照一定次序存放(后进先出),stack中主要存放一些基本类型的变量和对象的引用,存在栈中的数据大小与生存期必须是确定的。可以明确知道每个区块的大小,因此,stack的寻址速度要快于heap。

函数调用形成了一个栈帧。
function foo(b) { var a = 10; return a + b + 11; } function bar(x) { var y = 3; return foo(x * y); } console.log(bar(7));
当调用bar时,创建了第一个帧 ,帧中包含了bar的参数和局部变量。
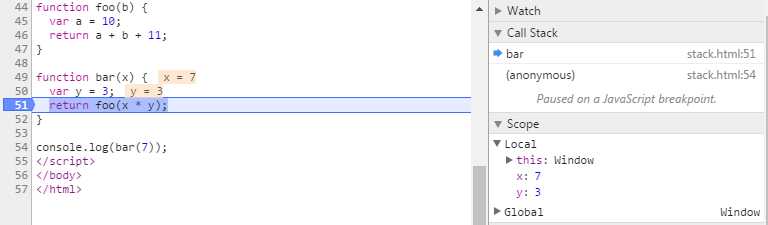
当bar调用foo时,第二个帧就被创建,并被压到第一个帧之上,帧中包含了foo的参数和局部变量。当foo返回时,最上层的帧就被弹出栈(剩下bar函数的调用帧 )。
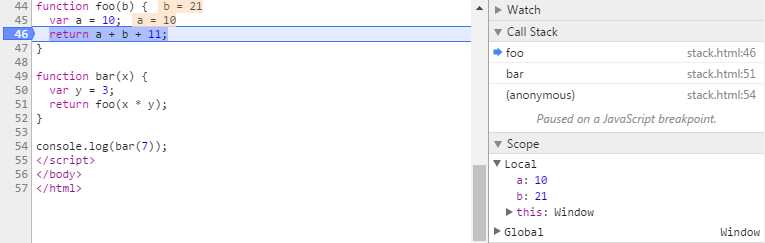
当bar返回的时候,栈就空了。
stack overflow(栈溢出)
因为stack是有限制的,而且stack超出浏览器的规定的栈限制时就会报stack overflow。一般情况下不会出现这种情况,因为js语言有他自己的GC机制,而出现这种情况一般是js的死循环或者没有正确的停止递归造成的,可以通过调试去追踪stack。我还碰到过c++编绎的activx控件,使用事件函数做实时推送时stack overflow。原因是控件的事件函数并不会等showMsg函数执行完再进行推送,解决方法是推送每次只推送一条,当js执行完后再请求下一次推送。
function showMsg(msg){
return msg;
}
function msgctrl::OnMsgNtf(msg)
{
showMsg()
}
堆与栈的大小
程序运行时,每个线程分配一个stack,每个进程分配一个heap,也就是说,stack是线程独占的,heap是线程共用的。此外,stack创建的时候,大小是确定的,数据超过这个大小,就发生stack overflow错误,而heap的大小是不确定的,需要的话可以不断增加。所以这里只看stack的大小限制。下面是一个简单的测试:
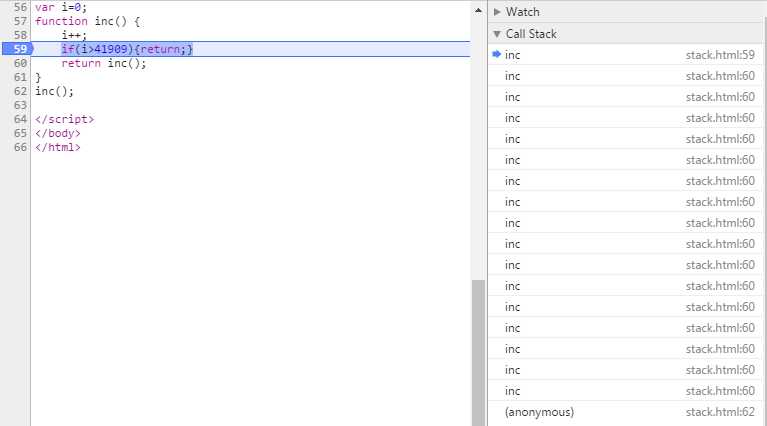
var i=0; function inc() { i++; if(i>41909){return;} inc(); } inc();
测试环境是16G内存的电脑,需要注意的是:根据栈的定义可以知道如果 inc 函数里有变量申明的话也是会有内存占用的。
1、谷歌浏览器chrome 55.0版本下限制是41909条。
2、IE8浏览器下限制是3062条。
javascript 的单线程
JavaScript语言的一大特点就是单线程,也就是说,同一个时间只能做一件事。
JavaScript的单线程,与它的用途有关。作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?
所以,为了避免复杂性,从一诞生,JavaScript就是单线程,这已经成了这门语言的核心特征,将来也不会改变。
为了利用多核CPU的计算能力,HTML5提出Web Worker标准,允许JavaScript脚本创建多个线程,但是子线程完全受主线程控制,且不得操作DOM。所以,这个新标准并没有改变JavaScript单线程的本质。
Event-Loop(事件循环)
单线程就意味着,所有任务需要排队,前一个任务结束,才会执行后一个任务。如果前一个任务耗时很长,后一个任务就不得不一直等着。
如果排队是因为计算量大,CPU忙不过来,倒也算了,但是很多时候CPU是闲着的,因为IO设备(输入输出设备)很慢(比如Ajax操作从网络读取数据),不得不等着结果出来,再往下执行。
JavaScript语言的设计者意识到,这时主线程完全可以不管IO设备,挂起处于等待中的任务,先运行排在后面的任务。等到IO设备返回了结果,再回过头,把挂起的任务继续执行下去。
于是,所有任务可以分成两种,一种是同步任务(synchronous),另一种是异步任务(asynchronous)。同步任务指的是,在主线程上排队执行的任务,只有前一个任务执行完毕,才能执行后一个任务;异步任务指的是,不进入主线程、而进入"任务队列"(task queue)的任务,只有"任务队列"通知主线程,某个异步任务可以执行了,该任务才会进入主线程执行。
常见的异步任务有Ajax操作、定时器(setTimeout/setInterval)、UI事件(load(图片js文件的加载等)、resize、scroll、click等)。网上有文章说定时器是另起一个线程并行执行是不对的,下面是简单的测试:
setTimeout(function(){console.log(111)},5); console.log(new Date().getTime()) for(var i=0; i<10000000; i++){ } console.log(new Date().getTime()) console.log(777);
运行结果:
可以看出只有等主线程执行完毕后才会执行任务队列中的任务。
具体来说,异步执行的运行机制如下。(同步执行也是如此,因为它可以被视为没有异步任务的异步执行。)
(1)所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
(2)主线程之外,还存在一个"任务队列"(task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件。
(3)一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
(4)主线程不断重复上面的第三步。
下图就是主线程和任务队列的示意图。

只要主线程空了,就会去读取"任务队列",这就是JavaScript的运行机制。这个过程会不断重复。
javascript内存管理(堆和栈)和javascript运行机制
标签:没有 上层 添加内容 多核 实时 情况下 允许 对象 解释器
原文地址:http://www.cnblogs.com/web-easy/p/7889184.html