标签:读取 protoc sch 主从 多次 编码 独立 ges 记录
use information_schema; select table_rows from TABLES where TABLE_SCHEMA = ‘数据库名‘ AND TABLE_NAME = ‘表名‘;
如果表使用的是InnoDB引擎,table_rows只是粗略估计值,要得到实际准确值还是用count(*)来统计读取吧
For InnoDB tables, the row count is only a rough estimate used in SQL optimization.
(This is also true if the InnoDB table is partitioned.)
EXPLAIN解析SELECT语句执行计划: EXPLAIN与DESC同义,通过它可解析MySQL如何处理SELECT,提供有关表如何联接和联接的次序,还可以知道什么时候必须为表加入索引以得到一个使用索引来寻找记录的更快的SELECT。为了强制优化器让一个SELECT语句按照表命名顺序的联接次序,语句应以STRAIGHT_JOIN而不只是SELECT开头。EXPLAIN为用于SELECT语句中的每个表返回一行信息。表以它们在处理查询过程中将被MySQL读入的顺序被列出。MySQL用一遍扫描多次联接(single-sweep multi-join)的方式解决所有联接。这意味着MySQL从第一个表中读一行,然后找到在第二个表中的一个匹配行,然后在第3个表中等等。当所有的表处理完后,它输出选中的列并且返回表清单直到找到一个有更多的匹配行的表。从该表读入下一行并继续处理下一个表。EXPLAIN通常可如下使用:
1. explain select id,name from users where age > 20; 2. 或者 explain extended select id,name from users where age > 20;show warnings;
1. BIT(M)存储M bits的0/1序列,M介于1~64之间,须采用 b‘value‘标记方式指定一个BIT数值类型的值,如 INSERT INTO t SET b = b‘1010‘;
2. BIT类型的值是不可读的,"+ 0"或者用BIN()、CAST()之类的函数转换后方可读,如 SELECT b+0, BIN(b), OCT(b), HEX(b) FROM t;
3. BINARY / VARBIANRY 同 CHAR / VARCHAR 相似,除了 BIANARY / VARBINARY 只包含字节流,没有字符集的概念,排序和比较操作都是基于字节的数字值;
4. BINARY(255) / VARBIANRY(65535) 允许的最大长度同 CHAR / VARCHAR 一样,但前者以字节而非字符为单位计算长度,后者是字符集相关的,VARCHAR若采用了UTF-8字符集编码则长度最大值很可能小于65535。
M) 和 LONGTEXT的解释:
VARCHAR(M)
A variable-length string. M represents the maximum column length in characters.
The range of M is 0 to 65,535. The effective maximum length of a VARCHAR is subject
to the maximum row size (65,535 bytes, which is shared among all columns) and the
character set used. For example, utf8 characters can require up to three bytes per
character, so a VARCHAR column that uses the utf8 character set can be declared to
be a maximum of 21,844 characters.
LONGTEXT
A TEXT column with a maximum length of 4,294,967,295 or 4GB (2^32 ? 1) characters.
The effective maximum length is less if the value contains multibyte characters.
The effective maximum length of LONGTEXT columns also depends on the configured
maximum packet size in the client/server protocol and available memory. Each LONGTEXT
value is stored using a 4-byte length prefix that indicates the number of bytes in the value.
几种索引的区别:
1. 聚簇索引(Clustered Index):也叫聚集索引,在叶子页(Leaf Page)中存储了完整的数据行,实际也是表的一种数据存储方式,这样的表也称索引组织表(Index Organized Table, IOT)。一个InnoDB表中通常只能有一个聚簇索引,被定义在主键上。MYISAM 不支持该索引类型,其索引文件(.MYI)和数据文件(.MYD)是相互独立的。
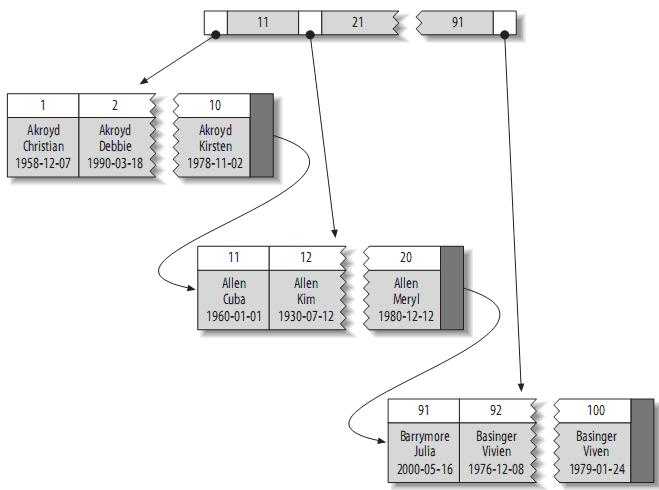
INNODB和MYISAM的主键索引与二级索引的对比:可以看出MYISAM的主键索引和二级索引没有任何区别,主键索引仅仅只是一个叫做PRIMARY KEY的唯一非空的索引,因此 MYISAM 可以不设主键。
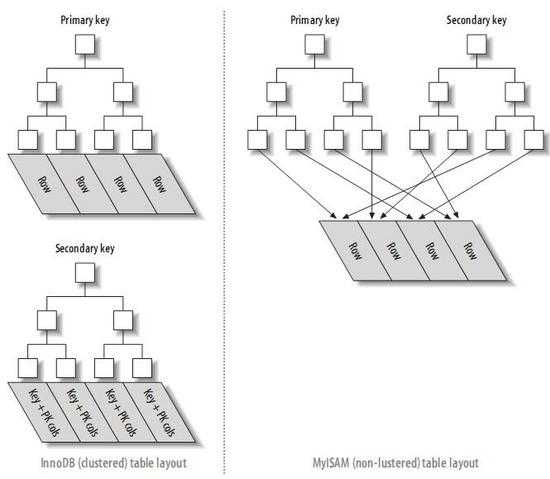
2. 辅助索引(Secondary Index):又叫二级索引,指除聚簇索引之外的所有索引。InnoDB的二级索引的叶子节点包含主键值而不是行指针(Row Pointer),这减小了移动数据或者数据页面分裂时维护二级索引的开销,因为InnoDB不需要更新索引的行指针。
3. 覆盖索引:指索引包含了满足查询结果的数据,另一种理解认为也应包含查询条件中所涉及的字段。其最大的好处就是避免了读取磁盘数据文件中的行,Innodb的辅助索引叶子节点包含的是主键列,所以主键一定是被索引覆盖的。
主从复制: MySQL 在每个事务更新数据之前,由 Master 将事务串行的写入二进制日志,即使事务中的语句都是交叉执行的,之后通知存储引擎提交事务。MySQL支持三种复制方式,实现了Data Distribution、Load Balancing、Backups、High Availability and Failover等特性。
1. 基于语句复制:在主服务器上执行的SQL语句,在从服务器上执行同样的语句。MySQL默认采用基于语句的复制,效率比较高。
2. 基于行复制:MySQL5.0开始支持把改变的内容复制过去,而不是把命令在从服务器上执行一遍。
3. 混合类型复制:默认采用基于语句的复制,一旦发现基于语句的无法精确的复制时,就会采用基于行的复制。
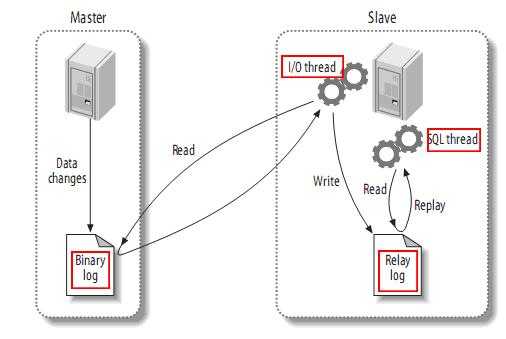
复制过程是通过三个线程来完成的,
1. Master binlog输出线程:Master为每一个复制连接请求创建一个binlog输出线程,用于输出日志内容到相应的Slave;
2. Slave I/O线程:在start slave之后,该线程负责从Master上拉取binlog内容放进自己的Relay Log中;
3. Slave SQL线程:负责执行Relay Log中的语句。
max_connections 和 max_user_connections:max_connections默认是151,当MySQL与Apache Web服务器一起使用时,可以提高性能。mysqld实际上允许max_connections + 1客户端连接,额外的1个连接预留给具有超级权限的帐户使用。Linux或Solaris如果有可用的RAM,支持至少500到1000个并发连接甚至多达10000个;Windows限制open tables × 2 + open connections < 2048。max_user_connections指定一个非0值用来限定任何账号能同时打开的最大连接数。
Any statement that a client can issue counts against the query limit, unless its results are served from
the query cache. Only statements that modify databases or tables count against the update limit.
标签:读取 protoc sch 主从 多次 编码 独立 ges 记录
原文地址:http://www.cnblogs.com/XiongMaoMengNan/p/7248794.html