标签:访问 关于 磁盘读写 支持 存储结构 平衡二叉树 字符 线性 特殊
所谓索引,即是快速定位与查找,那么索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数(B+树相比B树,其非叶子节点占用更小的空间,可以有更多非叶子节点存放在再内存中,减少大量的IO)
1、索引原理
2、局部性原理和磁盘预读
局部性原理:
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
数据库系统巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。
大规模数据存储中,实现索引查询这样一个实际背景下,树节点存储的元素数量是有限的(如果元素数量非常多的话,查找就退化成节点内部的线性查找了),这样导致二叉查找树结构由于树的深度过大而造成磁盘I/O读写过于频繁,进而导致查询效率低下(为什么会出现这种情况,待会在外部存储器-磁盘中有所解释),那么如何减少树的深度(当然是不能减少查询的数据量),一个基本的想法就是:采用多叉树结构(由于树节点元素数量是有限的,自然该节点的子树数量也就是有限的)。
也就是说,因为磁盘的操作费时费资源,如果过于频繁的多次查找势必效率低下。那么如何提高效率,即如何避免磁盘过于频繁的多次查找呢?根据磁盘查找存取的次数往往由树的高度所决定,所以,只要我们通过某种较好的树结构减少树的结构尽量减少树的高度,那么是不是便能有效减少磁盘查找存取的次数呢?那这种有效的树结构是一种怎样的树呢?
这样我们就提出了一个新的查找树结构——多路查找树。根据平衡二叉树的启发,自然就想到平衡多路查找树结构,也就是这篇文章所要阐述的第一个主题B~tree,即B树结构(后面,我们将看到,B树的各种操作能使B树保持较低的高度,从而达到有效避免磁盘过于频繁的查找存取操作,从而有效提高查找效率)。
1.外存-磁盘
计算机存储设备一般分为两种:内存储器(main memory)和外存储器(external memory)。 内存存取速度快,但容量小,价格昂贵,而且不能长期保存数据(在不通电情况下数据会消失)。
外存储器—磁盘是一种直接存取的存储设备(DASD)。它是以存取时间变化不大为特征的。可以直接存取任何字符组,且容量大、速度较其它外存设备更快。
当磁盘驱动器执行读/写功能时。盘片装在一个主轴上,并绕主轴高速旋转,当磁道在读/写头(又叫磁头) 下通过时,就可以进行数据的读 / 写了。
磁盘上数据必须用一个三维地址唯一标示:柱面号、盘面号、块号(磁道上的盘块)。
读/写磁盘上某一指定数据需要下面3个步骤:
(1) 首先移动臂根据柱面号使磁头移动到所需要的柱面上,这一过程被称为定位或查找 。
(2) 如上图11.3中所示的6盘组示意图中,所有磁头都定位到了10个盘面的10条磁道上(磁头都是双向的)。这时根据盘面号来确定指定盘面上的磁道。
(3) 盘面确定以后,盘片开始旋转,将指定块号的磁道段移动至磁头下。
经过上面三个步骤,指定数据的存储位置就被找到。这时就可以开始读/写操作了。
访问某一具体信息,由3部分时间组成:
● 查找时间(seek time) Ts: 完成上述步骤(1)所需要的时间。这部分时间代价最高,最大可达到0.1s左右。
● 等待时间(latency time) Tl: 完成上述步骤(3)所需要的时间。由于盘片绕主轴旋转速度很快,一般为7200转/分(电脑硬盘的性能指标之一, 家用的普通硬盘的转速一般有5400rpm(笔记本)、7200rpm几种)。因此一般旋转一圈大约0.0083s。
● 传输时间(transmission time) Tt: 数据通过系统总线传送到内存的时间,一般传输一个字节(byte)大概0.02us=2*10^(-8)s
磁盘读取数据是以盘块(block)为基本单位的。位于同一盘块中的所有数据都能被一次性全部读取出来。而磁盘IO代价主要花费在查找时间Ts上。因此我们应该尽量将相关信息存放在同一盘块,同一磁道中。或者至少放在同一柱面或相邻柱面上,以求在读/写信息时尽量减少磁头来回移动的次数,避免过多的查找时间Ts。
所以,在大规模数据存储方面,大量数据存储在外存磁盘中,而在外存磁盘中读取/写入块(block)中某数据时,首先需要定位到磁盘中的某块,如何有效地查找磁盘中的数据,需要一种合理高效的外存数据结构,就是下面所要重点阐述的B-tree结构,以及相关的变种结构:B+-tree结构和B*-tree结构。
B-树,即为B树。因为B树的原英文名称为B-tree,而国内很多人喜欢把B-tree译作B-树,其实,这是个非常不好的直译,很容易让人产生误解。如人们可能会以为B-树是一种树,而B树又是一种一种树。而事实上是,B-tree就是指的B树。
B 树是为了磁盘或其它存储设备而设计的一种多叉(下面你会看到,相对于二叉,B树每个内结点有多个分支,即多叉)平衡查找树。
B树与红黑树最大的不同在于,B树的结点可以有许多子女,从几个到几千个。那为什么又说B树与红黑树很相似呢?因为与红黑树一样,一棵含n个结点的B树的高度也为O(lgn),但可能比一棵红黑树的高度小许多,应为它的分支因子比较大。所以,B树可以在O(logn)时间内,实现各种如插入(insert),删除(delete)等动态集合操作。
如下图所示,即是一棵B树,一棵关键字为英语中辅音字母的B树,现在要从树种查找字母R(包含n[x]个关键字的内结点x,x有n[x]+1]个子女(也就是说,一个内结点x若含有n[x]个关键字,那么x将含有n[x]+1个子女)。所有的叶结点都处于相同的深度,带阴影的结点为查找字母R时要检查的结点):
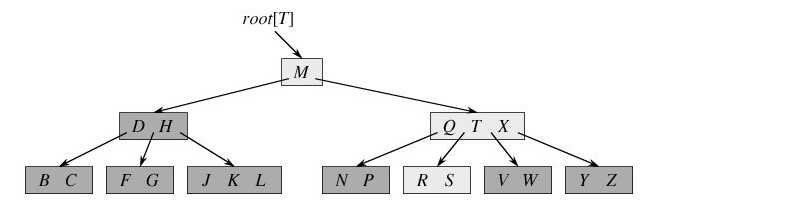
相信,从上图你能轻易的看到,一个内结点x若含有n[x]个关键字,那么x将含有n[x]+1个子女。如含有2个关键字D H的内结点有3个子女,而含有3个关键字Q T X的内结点有4个子女。
B 树又叫平衡多路查找树。
B树中的每个结点根据实际情况可以包含大量的关键字信息和分支(当然是不能超过磁盘块的大小,根据磁盘驱动(disk drives)的不同,一般块的大小在1k~4k左右);这样树的深度降低了,这就意味着查找一个元素只要很少结点从外存磁盘中读入内存,很快访问到要查找的数据。
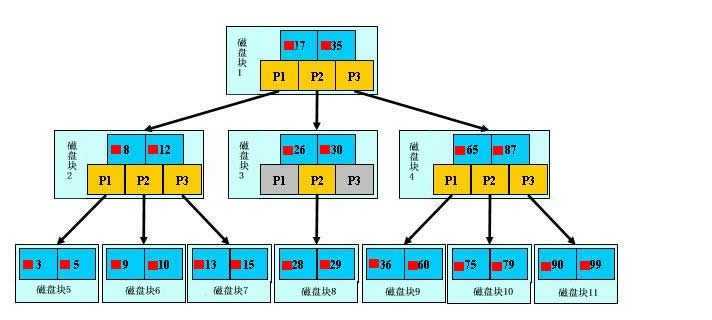
文件查找的具体过程:
为了简单,这里用少量数据构造一棵3叉树的形式,实际应用中的B树结点中关键字很多的。上面的图中比如根结点,其中17表示一个磁盘文件的文件名;小红方块表示这个17文件内容在硬盘中的存储位置;p1表示指向17左子树的指针。
其结构可以简单定义为:

typedef struct { /*文件数*/ int file_num; /*文件名(key)*/ char * file_name[max_file_num]; /*指向子节点的指针*/ BTNode * BTptr[max_file_num+1]; /*文件在硬盘中的存储位置*/ FILE_HARD_ADDR offset[max_file_num]; }BTNode;
假如每个盘块可以正好存放一个B树的结点(正好存放2个文件名)。那么一个BTNODE结点就代表一个盘块,而子树指针就是存放另外一个盘块的地址。
下面,咱们来模拟下查找文件29的过程:
分析上面的过程,发现需要3次磁盘IO操作和3次内存查找操作。关于内存中的文件名查找,由于是一个有序表结构,可以利用折半查找提高效率。至于IO操作是影响整个B树查找效率的决定因素。
当然,如果我们使用平衡二叉树的磁盘存储结构来进行查找,磁盘4次,最多5次,而且文件越多,B树比平衡二叉树所用的磁盘IO操作次数将越少,效率也越高。
树的高度:
根据上面的例子我们可以看出,对于辅存做IO读的次数取决于B树的高度。而B树的高度由什么决定的呢?若B树某一非叶子节点包含N个关键字,则此非叶子节点含有N+1个孩子结点,而所有的叶子结点都在第I层,我们可以得出:
树中每个结点含有最多含有m个孩子,即m满足:ceil(m/2)<=m<=m。而树中每个结点含孩子数越少,树的高度则越大,故如此
B+-tree:是应文件系统所需而产生的一种B-tree的变形树。
一棵m阶的B+树和m阶的B树的异同点在于:
所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (而B 树的叶子节点并没有包括全部需要查找的信息)
所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的非终节点也包含需要查找的有效信息)
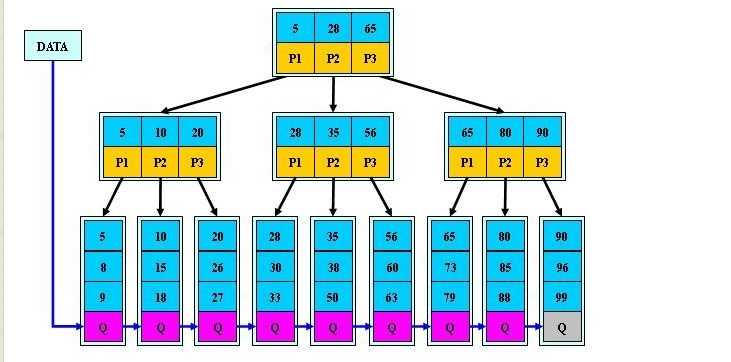
关键字的数量不同;B+树中分支结点有m个关键字,其叶子结点也有m个,其关键字只是起到了一个索引的作用,但是B树虽然也有m个子结点,但是其只拥有m-1个关键字。
存储的位置不同;B+树中的数据都存储在叶子结点上,也就是其所有叶子结点的数据组合起来就是完整的数据,但是B树的数据存储在每一个结点中,并不仅仅存储在叶子结点上。
分支结点的构造不同;B+树的分支结点仅仅存储着关键字信息和儿子的指针(这里的指针指的是磁盘块的偏移量),也就是说内部结点仅仅包含着索引信息。
查询不同;B树在找到具体的数值以后,则结束,而B+树则需要通过索引找到叶子结点中的数据才结束,也就是说B+树的搜索过程中走了一条从根结点到叶子结点的路径。
结构上:
性能上:
原因:
(1)B+树空间利用率更高,可减少I/O次数,
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗。而因为B+树的内部节点只是作为索引使用,而不像B-树那样每个节点都需要存储硬盘指针。
也就是说:B+树中每个非叶节点没有指向某个关键字具体信息的指针,所以每一个节点可以存放更多的关键字数量,即一次性读入内存所需要查找的关键字也就越多,减少了I/O操作。
e.g.假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内 部结点需要2个盘快。而B+ 树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+ 树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
(2)增删文件(节点)时,效率更高,
因为B+树的叶子节点包含所有关键字,并以有序的链表结构存储,这样可很好提高增删效率。
(3)B+树的查询效率更加稳定,
因为B+树的每次查询过程中,都需要遍历从根节点到叶子节点的某条路径。所有关键字的查询路径长度相同,导致每一次查询的效率相当。
B+树还有一个最大的好处,方便扫库,B树必须用中序遍历的方法按序扫库,而B+树直接从叶子结点挨个扫一遍就完了,B+树支持range-query非常方便,而B树不支持。这是数据库选用B+树的最主要原因
B-树和B+树最重要的一个区别就是B+树只有叶节点存放数据,其余节点用来索引,而B-树是每个索引节点都会有Data域。这就决定了B+树更适合用来存储外部数据,也就是所谓的磁盘数据。
从Mysql(Inoodb)的角度来看,B+树是用来充当索引的,一般来说索引非常大,尤其是关系性数据库这种数据量大的索引能达到亿级别,所以为了减少内存的占用,索引也会被存储在磁盘上。那么Mysql如何衡量查询效率呢?磁盘IO次数,B-树(B类树)的特定就是每层节点数目非常多,层数很少,目的就是为了就少磁盘IO次数,当查询数据的时候,最好的情况就是很快找到目标索引,然后读取数据,使用B+树就能很好的完成这个目的,但是B-树的每个节点都有data域(指针),这无疑增大了节点大小,说白了增加了磁盘IO次数(磁盘IO一次读出的数据量大小是固定的,单个数据变大,每次读出的就少,IO次数增多,一次IO多耗时啊!),而B+树除了叶子节点其它节点并不存储数据,节点小,磁盘IO次数就少。这是优点之一。
另一个优点是什么,B+树所有的Data域在叶子节点,一般来说都会进行一个优化,就是将所有的叶子节点用指针串起来。这样遍历叶子节点就能获得全部数据,这样就能进行区间访问啦。
本文主要参考:http://blog.csdn.net/v_JULY_v/article/details/6530142/
标签:访问 关于 磁盘读写 支持 存储结构 平衡二叉树 字符 线性 特殊
原文地址:http://www.cnblogs.com/vipchenwei/p/7822196.html
