标签:exec 全局 第九周作业 http 为什么 意义 原型 调度策略 nis
schedule()函数原型位于linux-3.18.6/kernel/sched/core.c中,其中主要的关键函数有pick_next_task(),这个函数调用之后,会根据某种进程调度策略选择出下一个运行的进程。紧接着是context_switch(),这是进程上下文切换函数,它的函数实现如下:
context_switch(struct rq *rq, struct task_struct *prev,struct task_struct *next)
{
struct mm_struct *mm, *oldmm;
prepare_task_switch(rq, prev, next);
mm = next->mm;
oldmm = prev->active_mm;
arch_start_context_switch(prev);
if (!mm) {
next->active_mm = oldmm;
atomic_inc(&oldmm->mm_count);
enter_lazy_tlb(oldmm, next);
} else
switch_mm(oldmm, mm, next);
if (!prev->mm) {
prev->active_mm = NULL;
rq->prev_mm = oldmm;
}
spin_release(&rq->lock.dep_map, 1, _THIS_IP_);
context_tracking_task_switch(prev, next);
switch_to(prev, next, prev); //关键函数
barrier();
/*
* this_rq must be evaluated again because prev may have moved
* CPUs since it called schedule(), thus the ‘rq‘ on its stack
* frame will be invalid.
*/
finish_task_switch(this_rq(), prev);
}在context_switch()函数中,最为重要的是switch_to()函数,它主要是由内联汇编实现,功能是完成进程切换。
#define switch_to(prev, next, last)
do {
unsigned long ebx, ecx, edx, esi, edi;
asm volatile("pushfl\n\t" /* 保存当前进程的flags */
"pushl %%ebp\n\t" /* 把当前进程的当前的ebp压入当前进程的栈 */
"movl %%esp,%[prev_sp]\n\t" /*保存当前的esp到prev->thread.sp指向的内存中 */
"movl %[next_sp],%%esp\n\t" /* 重置esp,把下个进程的next->thread.sp赋予esp */
"movl $1f,%[prev_ip]\n\t" /*把1:的代码在内存中存储的地址保存到prev->thread.ip中*/
"pushl %[next_ip]\n\t" /*重置eip */
__switch_canary
"jmp __switch_to\n" /*跳转到switch_to函数*/
"1:\t"
"popl %%ebp\n\t" /* 重置ebp */
"popfl\n" /* 重置flags*/
: [prev_sp] "=m" (prev->thread.sp),
[prev_ip] "=m" (prev->thread.ip),
"=a" (last),
"=b" (ebx), "=c" (ecx), "=d" (edx),
"=S" (esi), "=D" (edi)
__switch_canary_oparam
: [next_sp] "m" (next->thread.sp),
[next_ip] "m" (next->thread.ip),
[prev] "a" (prev),
[next] "d" (next)
__switch_canary_iparam
"memory");
} while (0)switch_to()是A进程到B进程的过渡,我们可以认为在switch_to()这个点上,A进程被切出,B进程被切入。进入 switch_to()的宏里面之后,首先pushfl和pushl ebp肯定仍然属于进程 A,之后把esp指向了B的堆栈,从此时开始的指令流都属于跟B进程有关的了。但是,这个时候B进程还没有完全准备好,因为 ebp和硬件上下文等内容还没有切换成B的,剩下的部分宏代码就是完成这些事情。对于 A 进程它始终没有感觉到自己被打断过,它认为自己一直是不间断执行的。switch_to()函数,除了改变了A进程中的prev变量外,对A没有其它任何影响。在系统中任何进程看到的都是这个样子,所有进程都认为自己在不间断的独立运行。
一想到schedule()函数,我想到的就是fork命令,正好上上节课在MenOS中新增加了fork命令,所以就用gdb跟踪之前的fork命令吧。
断点设置:
b schedule
b context_switch
b pick_next_task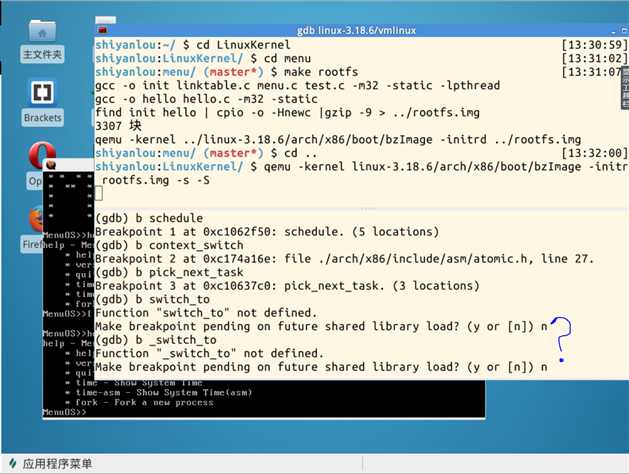
本来想在switch_to也设置一个断点,但设置了好几遍都没成功,起初还在想为什么,后来发现switch_to并不是单独函数,而是定义在宏中的一个宏。所以设置不了断点,然后尝试在它附近的函数设置断点,发现都无果,说明在context_switch中的“函数”都是写在宏中的,那果断放弃。
schedule()断点:
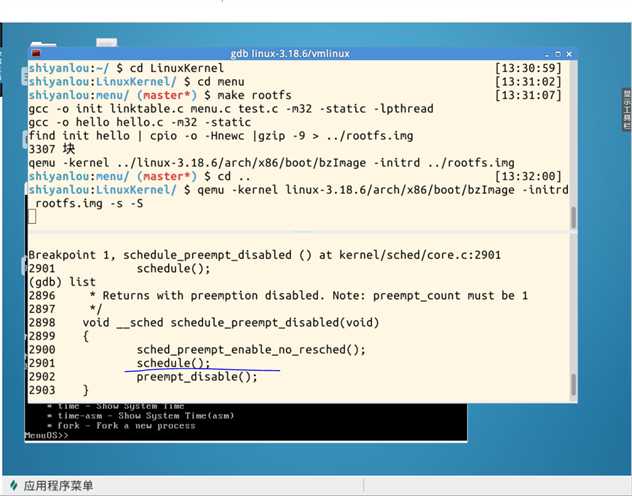
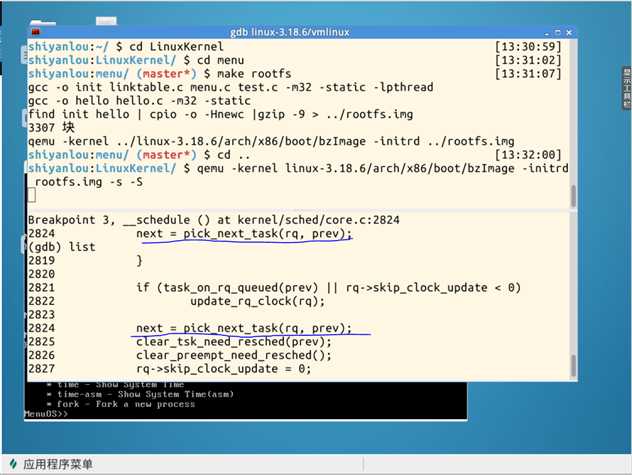
pick_next_task()断点:
context_switch()断点:
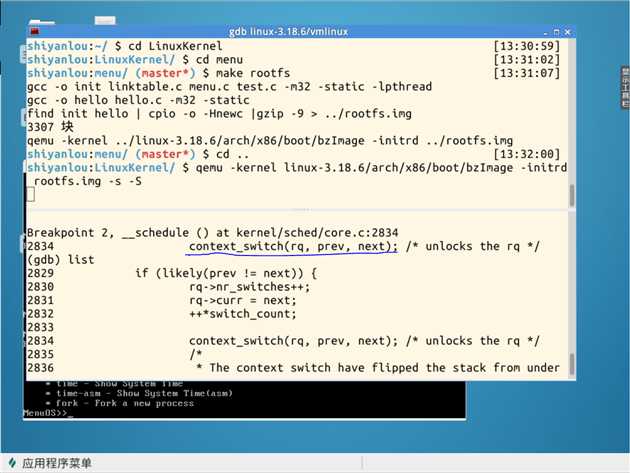
进程切换的一般过程:一个用户态进程A,发生中断,save cs:eip/esp/eflags等到内核堆栈;SAVE_ALL保存现场。中断处理过程中直接调用或者中断返回前调用schedule,其中switch_to中的汇编代码做了关键的部分。切换了内核堆栈,从当前进程进入到下一个进程。从标号1开始就开始运行下一个进程(这个进程必须是曾经通过这个过程被切换出去的,比如新进程就不包含在内);恢复下一个进程的现场,pop出eip,esp。继续运行进程切换前用户态正在跑的程序。
特殊情况:
当一个进程被调度时,该进程的mm域指向的地址空间被装载到内存,进程描述符中的active_mm域会被更新,指向新的地址空间。内核线程没有地址空间,所以mm域为NULL。于是,当一个内核线程被调度时,内核发现它的mm域为NULL,就会保留前一个进程的地址空间,随后内核更新内核线程对应的进程描述符中的active_mm域,使其指向前一个进程的内存描述符,所以在需要时,内核线程便可以使用前一个进程的页表。因为内核线程不防问用户空间的内存,所以它们仅仅使用地址空间中和内核内存相关的信息,这些信息的含义和普通进程完全相同。
Linux中使用三级页表完成地址转换。利用多级页表能够节约地址转换需占用的存放空间。
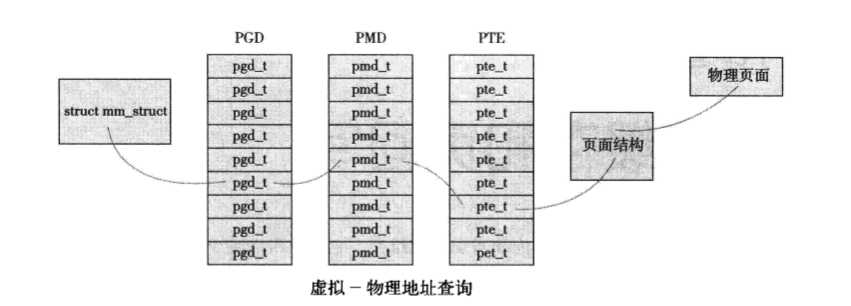
因为在任何页I/O操作内核前都要检查页是否已经在页高速缓存中了,所以这种频繁进行的检查必须是迅速高效的,否则搜索和检查页高速缓存的开销肯能抵消页高速缓存带来的好处。页高速缓存通过两个参数address_space对象加一个偏移量进行搜索。每个address_space对象都有唯一的基树,它保存在page_tree结构体中。基树是一个二叉树,只要指定了文件偏移量,就可以在基树中迅速检索到希望的页。页面高速缓存的搜索函数find_get_page()要调用radix_tree_lookup(),该函数会在指定的基树中搜索指定的页面。
PS:学了这么多关于Linux系统实现的内容,越来越觉得数据结构的重要性,起初感觉数据结构这门课很“废”,可能是我代码写得太少。现在看来,数据结构真的是门艺术。
单个线程可能会堵塞在某个队列的处理上,不能使所有磁盘都处于饱和的工作状态,原因在于磁盘的吞吐量是非常有限的。正是因为磁盘的吞吐量很有限,所以如果只有唯一线程执行页回写操作,那么这个线程很容易苦苦等待对一个磁盘的操作。为了避免这种情况发生,内核需要多个回写线程并发执行,这样单个设备队列的拥塞救护会成为系统的瓶颈了。
2017-2018-1 20179209《Linux内核原理与分析》第九周作业
标签:exec 全局 第九周作业 http 为什么 意义 原型 调度策略 nis
原文地址:http://www.cnblogs.com/genius-sen/p/7878716.html