标签:ora ssi 进制 pad cst 转义 编译 out href

方法一: CREATE USER语句创建 CREATE USER "用户名"@"IP地址" IDENTIFIED BY "密码"; 方法二: INSERT语句创建 INSERT INTO mysql.user(user,host, password,ssl_cipher,x509_issuer,x509_subject) VALUES(‘用户名’,’IP地址’,password(‘密码’),’’,’’,’’); FLUSH PRIVILEGES; 方法三: GRANT语句创建 GRANT SELECT ON *.* TO 用户名@’IP地址’ IDENTIFIED BY ‘密码’; FLUSH PRIVILEGES;
方法一:DROP USER语句删除 DROP USER "用户名"@"IP地址"; 方法二:DELETE语句删除 DELETE FROM mysql.user WHERE user=’用户名’ AND host=’IP地址’; FLUSH PRIVILEGES;
方法一: # mysqladmin -uroot -p123 password ‘new_password‘ //123为旧密码 方法二: UPDATE mysql.user SET password=password(‘new_password’) WHERE user=’root’ AND host=’localhost’; FLUSH PRIVILEGES; 方法三: SET PASSWORD=password(‘new_password’); FLUSH PRIVILEGES;
方法一: SET PASSWORD FOR 用户名@’IP地址’=password(‘new_password’); FLUSH PRIVILEGES; 方法二: UPDATE mysql.user SET password=password(‘new_password’) WHERE user=’用户名’ AND host=’IP地址’; FLUSH PRIVILEGES; 方法三: GRANT SELECT ON *.* TO user3@’localhost’ IDENTIFIED BY ‘yuan’; FLUSH PRIVILEGES;
SET password=password(‘new_password’);
# vim /etc/my.cnf skip-grant-tables # service mysqld restart # mysql -uroot mysql> UPDATE mysql.user SET password=password(‘new_password’) WHERE user=’root’ AND host=’localhost’; mysql> FLUSH PRIVILEGES;
rename user ‘用户名‘@‘IP地址‘ to ‘新用户名‘@‘IP地址‘;
/* flush privileges 命令本质上的作用是将当前user和privilige表中的用户信息/权限设置从mysql库(MySQL数据库的内置库)中提取到内存里。 MySQL用户数据和权限有修改后,搜索希望在"不重启MySQL服务"的情况下直接生效,那么就需要执行这个命令 */
--语法格式:
grant 权限列表 on 库名.表名 to 用户名@‘客户端主机‘ [identified by ‘密码‘ with option参数];
示例:

-- 给该用户授予对数据库db1下的表tb1所有的操作权限 grant all privileges on db1.tb1 TO ‘用户名‘@‘IP‘ -- 给该用户授予对数据库db1下所有表进行查操作的权限 grant select on db1.* TO ‘用户名‘@‘IP‘ -- 给该用户授予对所有数据库下所有表进行查和增的操作 grant select,insert on *.* TO ‘用户名‘@‘IP‘ -- 用户只能在该IP段下才能(通配符%表示任意)对所有数据库下所有表进行查操作 grant select on *.* TO ‘用户名‘@‘192.168.1.%‘ -- 用户能用户可以在任意IP下(通配符%表示任意)对所有数据库下所有表进行查操作 grant select on *.* TO ‘用户名‘@‘%‘
with_option参数:
GRANT OPTION: -- 授权选项 MAX_QUERIES_PER_HOUR: -- 定义每小时允许执行的查询数 MAX_UPDATES_PER_HOUR: -- 定义每小时允许执行的更新数 MAX_CONNECTIONS_PER_HOUR: -- 定义每小时可以建立的连接数 MAX_USER_CONNECTIONS: -- 定义单个用户同时可以建立的连接数
示例: 限制用户每小时的查询数量
mysql> grant select on *.* to ‘用户名‘@‘IP地址‘ identified by ‘123456‘ with max_queries_per_hour 5;
show grants for ‘用户‘@‘IP地址‘
--语法: REVOKE 权限列表 ON 库名.表名 FROM 用户名@‘客户端主机’
示例:
REVOKE DELETE ON *.* FROM 用户名@’%’; -- 回收部分权限 REVOKE ALL PRIVILEGES FROM 用户名@’%’; -- 回收所有权限
为了提高复杂SQL语句的复用性和表操作的安全性(例如:工资字段不想展示给所有能查看该查询结果的人),MySQL提供了视图特性。所谓视图,本质上是一种虚拟表,其内容与真实的表相似,包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储数据值的形式存在。行和列的数据来自定义视图的查询所引用基本表,并且在具体使用视图时动态生成。
视图有如下特点;
1. 视图的列可以来自不同的表,是表的抽象和逻辑意义上建立的新关系。
2. 视图是由基本表(实表)产生的表(虚表)。
3. 视图的建立和删除不影响基本表。
4. 对视图内容的更新(添加、删除和修改)直接影响基本表。
5. 当视图来自多个基本表时,不允许添加和删除数据。
在创建视图时,首先要确保拥有CREATE VIEW的权限,并且同时确保对创建视图所引用的表也具有相应的权限。
2.1 创建视图的语法形式:
虽然视图可以被看成是一种虚拟表,但是其在物理上是不存在的,即数据库管理系统没有专门的位置为视图存储数据。根据视图的概念发现其数据来源于查询语句,因此创建视图的语法为:
CREATE VIEW view_name AS 查询语句
//说明:和创建表一样,视图名不能和表名、也不能和其他视图名重名。视图的功能实际就是封装了复杂的查询语句。
示例:
use view_test; //选择一个自己创建的库 create table t_product( //创建表 id int primary key, pname varchar(20), price decimal(8,2) ); insert into t_product values(1,‘apple‘,6.5); //向表中插入数据 insert into t_product values(2,‘orange‘,3); //向表中插入数据 create view view_product as select id,pname from t_product; //创建视图 select * from view_product;
结果为:
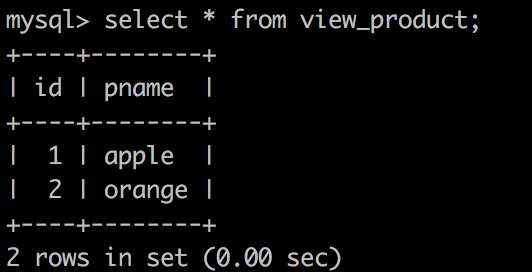
//其实在创建视图时实际代码里写的是一个表查询语句,只不过把这个查询语句封装起来重新起了一个名字,方便可以重复使用。
//再者,安全性方面可以隐藏一些不希望看到的字段,比如这里的价格字段。
//注意:在SQL语句的命名规范中,视图一般以view_xxx或者v_xxx的样式来命名。视图的查询语句和表的查询语句相同。
2.2 创建各种视图:
由于视图的功能实际上时封装查询语句,那么是不是任何形式的查询语句都可以封装在视图中呢?
封装使用聚合函数(SUM、MIN、MAX、COUNT等)查询语句的视图: 示例:
首先准备需要用到的两张表及其初始化数据;
CREATE TABLE t_group( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(20) ); CREATE TABLE t_student( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(20), sex CHAR(1), group_id INT, FOREIGN KEY (group_id) REFERENCES t_group (id) ); //t_group表中插入数据 INSERT INTO t_group (NAME) VALUES(‘group_1‘); INSERT INTO t_group (NAME) VALUES(‘group_2‘); INSERT INTO t_group (NAME) VALUES(‘group_3‘); INSERT INTO t_group (NAME) VALUES(‘group_4‘); INSERT INTO t_group (NAME) VALUES(‘group_5‘); //t_student表中插入数据 INSERT INTO t_student (NAME,sex,group_id) VALUES(‘yuan_1‘,‘M‘,1); INSERT INTO t_student (NAME,sex,group_id) VALUES(‘yuan_2‘,‘M‘,1); INSERT INTO t_student (NAME,sex,group_id) VALUES(‘yuan_3‘,‘M‘,2); INSERT INTO t_student (NAME,sex,group_id) VALUES(‘yuan_4‘,‘W‘,2); INSERT INTO t_student (NAME,sex,group_id) VALUES(‘yuan_5‘,‘W‘,2); INSERT INTO t_student (NAME,sex,group_id) VALUES(‘yuan_6‘,‘W‘,2); INSERT INTO t_student (NAME,sex,group_id) VALUES(‘yuan_7‘,‘M‘,3); INSERT INTO t_student (NAME,sex,group_id) VALUES(‘yuan_8‘,‘W‘,4); INSERT INTO t_student (NAME,sex,group_id) VALUES(‘yuan_9‘,‘W‘,4); ================================================================ mysql> create view view_test2 as select count(name) from t_student; Query OK, 0 rows affected (0.71 sec) mysql> select * from view_test2; +-------------+ | count(name) | +-------------+ | 9 | +-------------+ 1 row in set (0.01 sec)
2.2.3 封装了实现排序功能(ORDER BY)查询语句的视图:
示例:
mysql> create view view_test3 as select name from t_student order by id desc; Query OK, 0 rows affected (0.06 sec) mysql> select * from view_test3;
+--------+
| name |
+--------+
| yuan_9 |
| yuan_8 |
| yuan_7 |
| yuan_6 |
| yuan_5 |
| yuan_4 |
| yuan_3 |
| yuan_2 |
| yuan_1 |
+--------+ 9 rows in set (0.00 sec)
2.2.4 封装了实现表内连接查询语句的视图:
示例:(第二组学生的姓名)
mysql> create view view_test5 as select s.name from t_student s,t_group g where s.group_id=g.id and g.id=2; Query OK, 0 rows affected (0.07 sec) mysql> select * from view_test5; +--------+ | name | +--------+ | yuan_3 | | yuan_4 | | yuan_5 | | yuan_6 | +-------+ 4 rows in set (0.00 sec)
2.2.6 封装了实现子查询相关查询语句的视图:
示例:
mysql> create view view_test7 as select s.name from t_student s where s.id in(select id from t_group); Query OK, 0 rows affected (0.08 sec) mysql> select * from view_test7;
+--------+
| name |
+--------+
| yuan_1 |
| yuan_2 |
| yuan_3 |
| yuan_4 |
| yuan_5 |
+--------+ 5 rows in set (0.00 sec)
2.2.7 封装了实现记录联合(UNION和UNION ALL)查询语句的视图:
mysql> create view view_test8 as select id,name from t_student union all select id,name from t_group; Query OK, 0 rows affected (0.08 sec) mysql> select * from view_test8;
+----+---------+
| id | name |
+----+---------+
| 1 | yuan_1 |
| 2 | yuan_2 |
| 3 | yuan_3 |
| 4 | yuan_4 |
| 5 | yuan_5 |
| 6 | yuan_6 |
| 7 | yuan_7 |
| 8 | yuan_8 |
| 9 | yuan_9 |
| 1 | group_1 |
| 2 | group_2 |
| 3 | group_3 |
| 4 | group_4 |
| 5 | group_5 |
+----+---------+ 14 rows in set (0.01 sec)
3.1 SHOW TABLES语句查看视图名:
执行SHOW TABLES 语句时不仅可以显示表的名字,同时也是显示出视图的名字。
示例:
mysql> show tables;
+-----------------+
| Tables_in_test2 |
+-----------------+
| goods |
| order |
| orders |
| person |
| t_group |
| t_product |
| t_student |
| view_product |
| view_test2 |
| view_test3 |
| view_test5 |
| view_test7 |
| view_test8 |
+-----------------+
13 rows in set (0.00 sec
3.2 SHOW TABLE STATUS语句查看视图详细信息:
和SHOW TABLES语句一样,SHOW TABLE STATUS语句不仅会显示表的详细信息,同时也会显示视图的详细信息。
语法如下:
SHOW TABLE STATUS [FROM db_name] [LIKE ‘pattern‘]
//参数db_name用来设置数据库,SHOW TABLES STATUS表示将显示所设置库的表和视图的详细信息。
//设置LIKE关键字,可以查看某一个具体表或视图的详细信息。例如: SHOW TABLE STATUS FROM zhaojd LIKE ‘t_group‘ \G
3.3 SHOW CREATE VIEW语句查看视图定义信息:
语法为:
SHOW CREATE VIEW viewname;
3.4 DESCRIBE | DESC 语句查看视图定义信息:
语法为:
DESCRIBE | DESC viewname;
3.5 通过系统表查看视图信息:
当MySQL安装成功后,会自动创建系统数据库infomation_schema。在该数据库中存在一个包含视图信息的表格,可以通过查看表格views来查看所有视图的相关信息。
示例:
mysql> use information_schema; Database changed
mysql> select * from views where table_name=‘view_test7‘ \G;
*************************** 1. row ***************************
TABLE_CATALOG: def
TABLE_SCHEMA: test2
TABLE_NAME: view_test7
VIEW_DEFINITION: select `s`.`NAME` AS `name` from `test2`.`t_student` `s`
where `s`.`id` in (select `test2`.`t_group`.`id` from `test2`.`t_group`)
CHECK_OPTION: NONE
IS_UPDATABLE: YES
DEFINER: root@localhost
SECURITY_TYPE: DEFINER
CHARACTER_SET_CLIENT: utf8
COLLATION_CONNECTION: utf8_general_ci
1 row in set (0.00 sec)
在删除视图时首先要确保拥有删除视图的权限。
语法为:
DROP VIEW view_name [,view_name] ......
//从语法可以看出,DROP VIEW一次可以删除多个视图
示例:
mysql> drop view view_test1,view_test2; Query OK, 0 rows affected (0.01 sec) mysql> show tables;
5.1 CREATE OR REPLACE VIEW语句修改视图:
对于已经创建好的表,尤其是已经有大量数据的表,通过先删除,然后再按照新的表定义重新建表的方式来修改表,需要做很多额外的工作,例如数据的重载等。可是对于视图来说,由于是“虚表”,并没有存储数据,所以完全可以通过该方式来修改视图。
实现思路就是:先删除同名的视图,然后再根据新的需求创建新的视图即可。
DROP VIEW view_name; CREATE VIEW view_name as 查询语句;
但是如果每次修改视图,都是先删除视图,然后再次创建一个同名的视图,则显得非常麻烦。于是MySQL提供了更方便的实现替换的创建视图的语法,完整语法为:
CREATE OR REPLACE VIEW view_name as 查询语句;
5.2 ALTER语句修改视图:
语法为:
ALTER VIEW view_name as 查询语句;
再MySQL中可以通常视图检索基本表数据,这是视图最基本的应用,除此之后还可以通过视图修改基本表中的数据。
6.1检索(查询)数据:
通过视图查询数据,与通过表进行查询完全相同,只不过通过视图查询表更安全,更简单实用。只需要把表名换成视图名即可。
6.2利用视图操作基本表数据:
由于视图是“虚表”,所以对视图数据进行的更新操作,实际上是对其基本表数据进行的更新操作。在具体更新视图数据时,需要注意以下两点;
1. 对视图数据进行添加、删除直接影响基本表。
2. 视图来自于多个基本表时,不允许添加、删除数据。
视图中的添加数据操作、删除数据操作、更新数据操作的语法同表完全相同。只是将表名换成视图名即可。
我们常用的操作数据库语言SQL语句在执行的时候需要要先编译,然后执行,而存储过程(Stored Procedure)是一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给定参数(如果该存储过程带有参数)来调用执行它。
存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户
通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。而我们常用的操作数据库语言SQL语句在执行的时
候需要要先编译,然后执行,所以执行的效率没有存储过程高。
存储过程优点如下:
重复使用。存储过程可以重复使用,从而可以减少数据库开发人员的工作量。提高性能。存储过程在创建的时候在进行了编译,将来使用的时候不再重新翻译。一般的SQL语句每执行一次就需要编译一次,所以使用存储过程提高了效率。减少网络流量。存储过程位于服务器上,调用的时候只需要传递存储过程的名称以及参数就可以了,因此降低了网络传输的数据量。安全性。参数化的存储过程可以防止SQL注入式攻击,而且可以将Grant、Deny以及Revoke权限应用于存储过程。
存储过程简单语法:
CREATE PROCEDURE 存储过程名称(
输入输出类型 变量名称 类型,
... ) BEGIN -- 声明, 语句要完成的操作,增删改查。。。 END
表结构如下:
-- 创建表 DROP TABLE IF EXISTS person; CREATE TABLE person ( `id` int(11) AUTO_INCREMENT, `username` varchar(255) DEFAULT NULL, `age` int(11) DEFAULT NULL, `password` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8; -- 插入数据 INSERT person VALUES (1,"yuan",23,123), (2,"egon",33,456), (3,"alex",35,789)
1、无参数存储
DELIMITER ! DROP PROCEDURE IF EXISTS proc_no_para; -- 创建存储过程 CREATE PROCEDURE proc_no_para() BEGIN SELECT * FROM person; END! DELIMITER ; CALL proc_no_para();
2、只带IN(输入参数)的存储过程
表示该参数的值必须在调用存储过程时指定,在存储过程中修改该参数的值不能被返回,为默认值。
DROP PROCEDURE IF EXISTS proc_person_findById; -- 创建存储过程 CREATE PROCEDURE proc_person_findById( in n int ) BEGIN SELECT * FROM person where id=n; END; -- 定义变量 SET @n=2; -- 调用存储过程 CALL proc_person_findById(@n);
3、只带OUT(输出参数)的存储过程
该值可在存储过程内部被改变,并可返回。
DELIMITER ! CREATE PROCEDURE Procdure_out( OUT n INT(11) ) BEGIN SELECT COUNT(*) INTO n FROM person; END! DELIMITER ; CALL Procdure_out(@n); SELECT @n AS "总数";
4、带IN(输入参数)和OUT(输出参数),调用时指定,并且可被改变和返回
DELIMITER ! DROP PROCEDURE IF EXISTS proc_person_findInfoById; -- 创建存储过程 CREATE PROCEDURE proc_person_findInfoById( IN n INT(11), OUT pusername VARCHAR(255), OUT page INT(11) ) BEGIN SELECT username, age INTO pusername, page FROM person WHERE id=n; END! DELIMITER ; -- 定义变量 SET @id=1; -- 调用存储过程 CALL proc_person_findInfoById(@id,@username, @age); SELECT @username as ‘用户名‘, @age ‘年龄‘;
5、带INOUT(输入输出)参数的存储过程
DELIMITER ! DROP PROCEDURE IF EXISTS proc_person_findInfoById; -- 创建存储过程 CREATE PROCEDURE proc_person_findInfoById( INOUT n INT ) BEGIN SELECT age INTO n FROM person WHERE id=n; END! DELIMITER ; -- 定义变量 SET @id=2; -- 调用存储过程 CALL proc_person_findInfoById(@age); SELECT @age ‘年龄‘;
注意:关于输入输出参数
IN为输入, 定义参数时,可以不加,不加则默认为输入参数。OUT为输出,定义参数时,必须加上。INOUT为输入和输出,必须加上。表示该参数可以输入也可在处理后存放结果进行输出。
变量定义
|
1
|
DECLARE variable_name [,variable_name...] datatype [DEFAULT value]; |
中,datatype为MySQL的数据类型,如:int, float, date, varchar(length)
变量赋值
|
1
|
SET 变量名 = 表达式值 [,variable_name = expression ...] |
DELIMITER // CREATE PROCEDURE proc_if(IN parameter int) begin declare var int; set var=parameter+1; if var=0 then insert into person values(7,"yuan",34,123456); end if; if parameter=0 then update person set password=password+1; else update person set password=password+2; end if; end; // DELIMITER ;
DELIMITER // CREATE PROCEDURE proc_case (in parameter int) begin declare var int; set var=parameter+1; case var when 0 then insert into person values(var,"yuan",var+10,123456+var); when 1 then insert into person values(var,"yuan",var+20,123456+var); else insert into person values(var,"yuan",var+30,123456+var); end case; end; // DELIMITER ;
循环的分类:
(1)WHILE ... END WHILE
DELIMITER $$ CREATE PROCEDURE insert_person4() BEGIN DECLARE v INT; SET v = 0; WHILE v < 10 DO INSERT INTO person VALUES (v+1,concat("yuan",v),v,v+123); SET v = v + 1; END WHILE; END; $$ DELIMITER ;
这是WHILE循环的方式。它跟IF语句相似,使用"SET v = 0;"语句使为了防止一个常见的错误,如果没有初始化,默认变量值为NULL,而NULL和任何值操作结果都为NULL。
(2)REPEAT ... END REPEAT
DELIMITER $$ CREATE PROCEDURE insert_person2() BEGIN DECLARE v INT; SET v = 0; REPEAT INSERT INTO person VALUES (v+1,concat("yuan",v),v,v+123); SET v = v + 1; UNTIL v >= 5 END REPEAT; END; $$ DELIMITER ;
drop procedure proc_name;
什么是触发器?
触发器是数据库的一个程序,他是用来监听着数据表的某个行为,一旦数据表的这个行为发生了,马上执行相应的sql语句
触发器的语法结构:
|
1
|
create trigger 触发器的名称触发器事件 on 监听的表名 for each row 行为发生后执行的sql语句 |
注意:行为发生后执行的sql语句可以是一句SQL语句,或者用 BEGIN 和 END 包含的多条语句。
触发器事件两个点:
一旦生成订单,对应的库存表要减去相应的数据
(1)建两张表 :一个商品goods表 一个订单order表
-- 创建表 create table goods( goods_id int primary key auto_increment, goods_name varchar(64), shop_price decimal(10,2), goods_number int)charset=utf8; create table orders(goods_id int primary key auto_increment, goods_name varchar(64), buy_number int)charset=utf8; -- 插入数据 insert into goods values(null,‘nokiaN85‘,2000,35), (null,‘iphone4S‘,4500,30), (null,‘Lnmia‘,5000,40), (null,‘samsung‘,4200,20); mysql> select*from goods; +---------------+-------------------+-------------------+----------------------+ | goods_id | goods_name | shop_price | goods_number | +---------------+-------------------+-------------------+----------------------+ | 1 | nokiaN85 | 2000.00 | 35 | | 2 | iphone4S | 4500.00 | 30 | | 3 | Lnmia | 5000.00 | 40 | | 4 | samsung | 4200.00 | 20 | +---------------+-------------------+-------------------+----------------------+
(2)创建触发器
create trigger alter_goods_number after insert on orders for each row update goods set goods_number=goods_number-5 where goods_id=1; insert into orders values(1,‘nokiaN85‘,5); select*from goods;
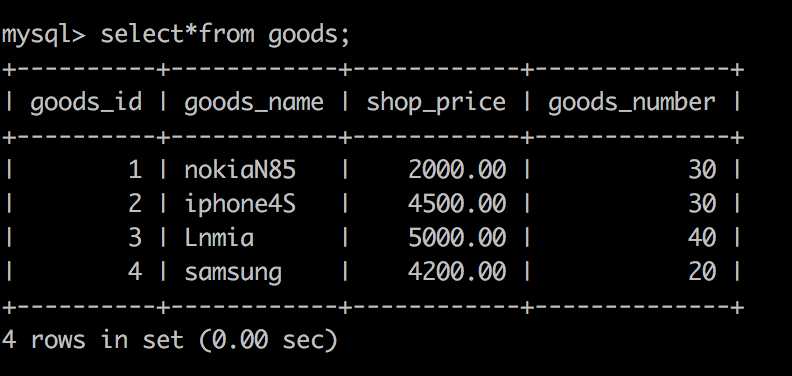
在 INSERT 型触发器中,NEW 用来表示将要(BEFORE)或已经(AFTER)插入的新数据; 在 UPDATE 型触发器中,OLD 用来表示将要或已经被修改的原数据,NEW 用来表示将要或已经修改为的新数据; 在 DELETE 型触发器中,OLD 用来表示将要或已经被删除的原数据;
关键词new 的使用:
create trigger alter_goods_number after insert on orders for each row update goods set goods_number=goods_number-new.buy_number
where where goods_id=new.goods_id; insert into orders values(1,‘samsung‘,10);
关键词old 的使用:
create trigger back_goods_number after delete on orders for each row update goods set goods_number=goods_number+old.buy_number
where goods_id=old.goods_id; delete from orders where goods_id=7;
更新 (update将之前下的订单撤销,再重新下订单)
create trigger update_goods_number after update on orders for each row update goods set goods_number=goods_number+old.buy_number-new.buy_number
where where goods_id=new.goods_id; update orders set buy_number = 10;
|
1
|
SHOW TRIGGERS [FROM schema_name]; |
其中,schema_name 即 Schema 的名称,在 MySQL 中 Schema 和 Database 是一样的,也就是说,可以指定数据库名,这样就 不必先USE database_name了
和删除数据库、删除表格一样,删除触发器的语法如下:
|
1
|
DROP TRIGGER [IF EXISTS] [schema_name.]trigger_name |
我们建立的数据库一般都是 InnoDB 数据库,其上建立的表是事务性表,也就是事务安全的。这时,若SQL语句或触发器执行失败,MySQL 会回滚事务,有:
①如果 BEFORE 触发器执行失败,SQL 无法正确执行。
②SQL 执行失败时,AFTER 型触发器不会触发。
③AFTER 类型的触发器执行失败,SQL 会回滚。
ABS(x) 返回x的绝对值 BIN(x) 返回x的二进制(OCT返回八进制,HEX返回十六进制) CEILING(x) 返回大于x的最小整数值 EXP(x) 返回值e(自然对数的底)的x次方 FLOOR(x) 返回小于x的最大整数值 GREATEST(x1,x2,...,xn)返回集合中最大的值 LEAST(x1,x2,...,xn) 返回集合中最小的值 LN(x) 返回x的自然对数 LOG(x,y)返回x的以y为底的对数 MOD(x,y) 返回x/y的模(余数) PI()返回pi的值(圆周率) RAND()返回0到1内的随机值,可以通过提供一个参数(种子)使RAND()随机数生成器生成一个指定的值。 ROUND(x,y)返回参数x的四舍五入的有y位小数的值 SIGN(x) 返回代表数字x的符号的值 SQRT(x) 返回一个数的平方根 TRUNCATE(x,y) 返回数字x截短为y位小数的结果
常用于GROUP BY从句的SELECT查询中
AVG(col)返回指定列的平均值 COUNT(col)返回指定列中非NULL值的个数 MIN(col)返回指定列的最小值 MAX(col)返回指定列的最大值 SUM(col)返回指定列的所有值之和 GROUP_CONCAT(col) 返回由属于一组的列值连接组合而成的结果
ASCII(char)返回字符的ASCII码值 BIT_LENGTH(str)返回字符串的比特长度 CONCAT(s1,s2...,sn)将s1,s2...,sn连接成字符串 CONCAT_WS(sep,s1,s2...,sn)将s1,s2...,sn连接成字符串,并用sep字符间隔 INSERT(str,x,y,instr) 将字符串str从第x位置开始,y个字符长的子串替换为字符串instr,返回结果 FIND_IN_SET(str,list)分析逗号分隔的list列表,如果发现str,返回str在list中的位置 LCASE(str)或LOWER(str) 返回将字符串str中所有字符改变为小写后的结果 LEFT(str,x)返回字符串str中最左边的x个字符 LENGTH(s)返回字符串str中的字符数 LTRIM(str) 从字符串str中切掉开头的空格 POSITION(substr,str) 返回子串substr在字符串str中第一次出现的位置 QUOTE(str) 用反斜杠转义str中的单引号 REPEAT(str,srchstr,rplcstr)返回字符串str重复x次的结果 REVERSE(str) 返回颠倒字符串str的结果 RIGHT(str,x) 返回字符串str中最右边的x个字符 RTRIM(str) 返回字符串str尾部的空格 STRCMP(s1,s2)比较字符串s1和s2 TRIM(str)去除字符串首部和尾部的所有空格 UCASE(str)或UPPER(str) 返回将字符串str中所有字符转变为大写后的结果
CURDATE()或CURRENT_DATE() 返回当前的日期 CURTIME()或CURRENT_TIME() 返回当前的时间 DATE_ADD(date,INTERVAL int keyword)返回日期date加上间隔时间int的结果(int必须按照关键字进行格式化),如:SELECTDATE_ADD(CURRENT_DATE,INTERVAL 6 MONTH); DATE_FORMAT(date,fmt) 依照指定的fmt格式格式化日期date值 DATE_SUB(date,INTERVAL int keyword)返回日期date加上间隔时间int的结果(int必须按照关键字进行格式化),如:SELECTDATE_SUB(CURRENT_DATE,INTERVAL 6 MONTH); DAYOFWEEK(date) 返回date所代表的一星期中的第几天(1~7) DAYOFMONTH(date) 返回date是一个月的第几天(1~31) DAYOFYEAR(date) 返回date是一年的第几天(1~366) DAYNAME(date) 返回date的星期名,如:SELECT DAYNAME(CURRENT_DATE); FROM_UNIXTIME(ts,fmt) 根据指定的fmt格式,格式化UNIX时间戳ts HOUR(time) 返回time的小时值(0~23) MINUTE(time) 返回time的分钟值(0~59) MONTH(date) 返回date的月份值(1~12) MONTHNAME(date) 返回date的月份名,如:SELECT MONTHNAME(CURRENT_DATE); NOW() 返回当前的日期和时间 QUARTER(date) 返回date在一年中的季度(1~4),如SELECT QUARTER(CURRENT_DATE); WEEK(date) 返回日期date为一年中第几周(0~53) YEAR(date) 返回日期date的年份(1000~9999)
View Code示例:
View Code
标签:ora ssi 进制 pad cst 转义 编译 out href
原文地址:http://www.cnblogs.com/huchong/p/7895858.html
