标签:pen 迭代 填充 pre 事先 数字 odi 大小 pca
1、L.append(object) -> None
在列表末尾添加单个元素,任何类型都可以,包括列表或元组等
2、L.extend(iterable) -> None
以序列的形式,在列表末尾添加多个元素
3、L.insert(index, object) -> None
在index位置处添加一个元素
4、L.clear() -> None
清除列表所有元素,成为空列表
5、L.copy() -> list
获得一个列表副本
6、L.count(A) -> integer
返回A在列表中出现的次数
7、L.index(A, [start, [stop]])
返回A在列表中第一次出现的位置,可以指定开始和结束位置
8、L.pop([index]) -> integer
弹出对应位置的元素,不填参数,默认弹出最后一个元素
9、L.remove(A) -> None
删除第一个元素A,其余元素A不擅长
10、L.sort(key=None, reverse=False) -> None
对列表进行排序,默认是升序。如果reverse=True,则改为降序。可以给key参数传递一个函数,如lambda或事先定义好的。然后按照这个函数定义以什么为排序基础, 例如以最后一个数字为排序基础,或以下划线后的数字为排序基础等。
此方法会改变列表排序
11、L.reverse() -> None
对列表进行降序
此方法会改变列表排序
1、T.count(A) -> integer
返回A在元祖中出现的次数
2、T.index(A, [start, [stop]]) -> integer
返回A在元祖中第一次出现的位置,可以指定开始和结束范围
1、S.add(element) -> None
添加一个元素到集合里
2、S.clear() -> None
清除集合所有元素
3、S.copy() -> set
返回原集合的副本
4、S.remove(element) -> None
移除集合中的一个元素,如果该元素不在集合中则报错
5、S.discard(element) -> None
同上,但如果该元素不在集合中不报错
6、S.pop() -> element
随机弹出一个原集合的元素
7、S.isdisjoint(S2) -> bool
如果两个集合没有交集,则返回True
8、S.issubset(S2) -> bool
如果S2(序列或者集合)集合包含S集合,则返回True
9、S.issuperset(S2) -> bool
如果S集合包含S2(序列或者集合)集合,则返回True
10、S.difference_update(S2) -> None
S减去S和S2(序列或者集合)的交集,不返回任何值,
此方法会改变原集合S
11、S. intersection_update(S2) -> None
S和S2(序列或者集合)的交集,不返回任何值,
此方法会改变原集合S
12、S. .symmetric_difference_update(S2) -> None
S和S2的并集减去S和S2的交集,不返回任何值
此方法会改变原集合S
13、S.update(S2) -> None
S和S2(序列或者集合)的并集,不返回任何值,
此方法会改变原集合S
14、S.intersection(S2) -> set
返回S和S2(序列或者集合)的交集
15、S.difference(S2) -> set
返回S减去S和S2(序列或者集合)的交集
16、S. symmetric_difference(S2) -> set
返回S和S2的并集减去S和S2的交集,S2可以是序列或集合
17、S.union(S2) -> set
返回S和S2(序列或者集合)的并集
1、D.clear() -> None
清除字典中所有键值
2、D.copy() -> D
返回一个字典的副本
3、D.pop(k[,d]) -> value
弹出k键对应的值,并移除键值。如果k键没有被找到,但设置了d的值,则返回d的值。如果没设置的d值的话,又没找到k键,则报错。
4、D.popitem() -> (k, v)
以元祖的形式,弹出一个键值(弹出的一般是堆栈的第一个键值)
5、D.keys() -> a set-like object
已类似列表的形式返回所有键(其实返回的更像是类列表的对象,并不会对重复的值进行处理)
6、D.values() -> a set-like object
已类似列表的形式返回所有值(其实返回的更像是类列表的对象,并不会对重复的值进行处理)
7、D.items() -> a set-like object
已类似列表的形式返回所有键值,每个键值以元祖的形式返回(其实返回的更像是类列表的对象,并不会对重复的值进行处理)
8、D.get(k[,d]) -> D[k] if k in D, else d.
如果字典存在k键则返回对应的值,如果不存在,但填了d值则返回d值,否则报错
9、D.setdefault(k[,d]) -> D.get(k,d), also set D[k]=d if k not in D
如果字典存在k键则返回对应的值,如果不存在,但填了d值则在原字典中建立新的键值,并返回该值。但没有填d值的话,则报错。
10、D.update(D2) -> None
D2也是字典。将D2的键值合并到D中,如果存在相同的键,则D2覆盖D
此方法会改变原字典D
11、D.fromkeys(iterable, value=None) -> dict
此方法用于创建字典。以可迭代的对象的所有元素作为键,value作为唯一的值。返回一个多键对单一值的字典(不论D是不是空字典结果都是一样的)
1、S.capitalize() -> str
将首字母转换成大写,需要注意的是如果首字没有大写形式,则返回原字符串
2、S.upper() -> str
将原字符串中所有的字母大写
3、S.lower() -> str
将原字符串中所有的字母小写(只能完成ASCII码中的A-Z)
4、S.casefold() -> str
将原字符串中所有的字母小写(能识别更多的对象将其输出位小写)
5、S.swapcase() -> str
将原字符串中存在的字母大小写互换
6、S.replace(old, new[, count]) -> str
替换字符。count参数代表替换几次old字符。如果不填count参数,默认替换所有的old字符
7、S.expandtabs(tabsize=8) -> str
将字符串中所有制表符(\t)替换为空格,替换空格数默认为7(8-1,其中tabsize=0表示去掉\t,tabsize=1或2都表示一个空格,其余为n-1个空格)
8、S.rjust(width[, fillchar]) -> str
如果原字符长度不足width,则剩余部分,在左边补齐空格。如果有填充单字符,则用字符代替空格。(注意:只能是单字符)
9、S.ljust(width[, fillchar]) -> str
同上。不过是在右边填充。
10、S.center(width[, fillchar]) -> str
同上。不过左右两边同时填。多出的部分填在右边
11、S.zfill(width) -> str
如果原字符长度不足width,则剩余部分,在左边补齐0
12、S.find(sub[, start[, end]]) -> int
返回子字符串在原字符串中第一次出现的位置,可以指定开始和结束位置。如果子字符串不在原字符串中则返回-1 注意:(start,end ]
13、S.index(sub[, start[, end]]) -> int
同上,不过如果子字符串不在原字符串中则报错 注意:(start,end ]
14、S.rindex(sub[, start[, end]]) -> int
同index,不过是从字符串右到左,不过返回的是子字符串最左边的第一个字符位置
15、S.rfind(sub[, start[, end]]) -> int
同find,不过是从字符串右到左,不过返回的是子字符串最左边的第一个字符位置
16、S.split(sep=None, maxsplit=-1) -> list of strings
返回一个以sep作为分隔符得到的列表。maxsplit代表分隔几次,默认为全分隔
17、S.rsplit(sep=None, maxsplit=-1) -> list of strings
同上。不过是从右至左
18、S.splitlines([keepends]) -> list of strings
返回一个按换行符作为分隔符得到的列表。默认keepends为False,表示得到的列表,列表的元素都去掉了换行符。如果改为True则保留换行符
19、S.partition(sep) -> (head, sep, tail)
此方法用来根据指定的分隔符将字符串进行分割。如果字符串包含指定的分隔符,则返回一个3元的元组。第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串。
如果不包含指定的分隔符,则第一个为原字符串,第二三个为空字符
20、S.rpartition(sep) -> (head, sep, tail)
同上,但是从右至左,且如果不包含指定的分隔符,则第一二个为空字符,第二个为原字符串
21、strip([chars]) -> str
默认返回一个去掉左右两边空格的字符串。如果参数写了子字符,则去掉左右两边所有的子字符
22、S.rstrip([chars]) -> str
同上,但是只去掉右边的字符
23、S.lstrip([chars]) -> str
同上,但是只去掉左边的字符
24、S.startswith(prefix[, start[, end]]) -> bool
判断字符串是否以某字符串开头,如果是,则True。可以指定开始和结束位置
25、S.endswith(suffix[, start[, end]]) -> bool
同上,不过判断的是结尾
26、S.count(sub[, start[, end]]) -> int
返回子字符串在原字符串中出现的次数。可以指定开始和结束位置
27、S.join(iterable) -> str
将原字符填充到序列的元素之间
28、S.encode(encoding=‘utf-8‘, errors=‘strict‘) -> bytes
编码,errors参数可选很多,其中有’ignore’
29、S.isidentifier() -> bool
是否为Python的关键字等,如果是为True
30、S.isalnum() -> bool
是否字符串全是由数字、英文或汉字组成(包括罗马数字等),如果是为True
31、S.isdecimal() -> bool
是否字符串只含有10进制数字
True:Unicode数字,全角数字(双字节)
False:罗马数字,汉字数字
Error:byte数字(单字节)
32、S.isnumeric() -> bool
是否字符串只含有数字
True:Unicode数字,全角数字(双字节),罗马数字,汉字数字
False:无
Error:byte数字(单字节)
33、S.isdigit() -> bool
是否字符串只含有数字
True:Unicode数字,byte数字(单字节),全角数字(双字节),罗马数字
False:汉字数字
Error:无
34、S.isspace() -> bool
是否字符串只含有空格(空格,制表符,换行符),如果是为True
35、S.isalpha() -> bool
是否字符串只含有字母,如果是为True
36、S.islower() -> bool
是否字符串中所有的字母都是小写(可以含非字母的字符),如果是为True
37、S.isupper() -> bool
如果原字符串中的字母(可以包含其他内容,如数字)全为大写,返回True
38、isprintable() -> bool
是否字符串中所有字符是可见状态(例如\n不可见),如果是为True
39、S.istitle() -> bool
是否字符中每个单词的首写字母都大写了(字符中除字母外,只允许有空格和正常的标点符号),如果是为True
40、S. maketrans(x, y=None, z=None) -> dict
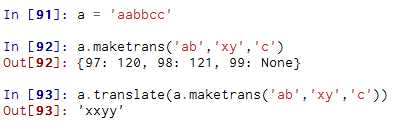
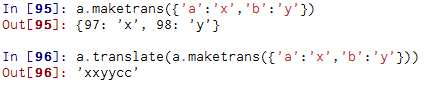
41、S.translate(table) -> str
参考上面语句(这里的table指的是字典映射表)
42、S.format_map(mapping) -> str

注意:键不能为纯数字
43、S.title() -> str
字符中每个单词的首写字母都大写(允许各种字符在中间隔断)
标签:pen 迭代 填充 pre 事先 数字 odi 大小 pca
原文地址:http://www.cnblogs.com/fushengweixie/p/7905731.html