标签:等价 编译 etc fast else 标记 这一 一个 概述
一、概念概述
给定一个单词,判断该单词是否满足我们给定的单词描述规则,需要用到编译原理中词法分析的相关知识,其中涉及到的两个很重要的概念就是正规式(Regular Expression)和有穷自动机(Finite Automata)。正规式是描述单词规则的工具,首先要明确的一点是所有单词组成的是一个无穷的集合,而正规式正是描述这种无穷集合的一个工具;有穷自动机则是识别正规式的一个有效的工具,它分为确定的有穷自动机(Deterministic Finite Automata,DFA)和不确定的有穷自动机(Nondeterministic Finite Automata,NFA)。对于任意的一个单词,将其输入正规式的初始状态,自动机每次读入一个字母,根据单词的字母进行自动机中状态的转换,若其能够准确的到达自动机的终止状态,就说明该单词能够被自动机识别,也就满足了正规式所定义的规则。而DFA与NFA之间的差异就是对于某一个状态S,输入一个字符a,DFA能够到达的下一个状态有且仅有一个,即为确定的概念,而NFA所能到达的状态个数大于或等于一个,即不确定的概念。因为NFA为不确定的,我们无法准确的判断下一个状态是哪一个,因此识别一个正规式的最好的方式是DFA。那么,如何为一个正规式构造DFA就成了主要矛盾,解决了这个问题,词法分析器就已经构造完成。从正规式到DFA需要通过两个过程来完成:
①从正规式转NFA:对输入的正规式字符串进行处理转成NFA;
②从NFA转DFA:对NFA进行确定化处理转成DFA;
二、正规式转NFA
【1】在正式开始算法描述之前需要先了解以下一些基础概念和规定:
1)正规式由两种字符组成:
①操作符:(仅考虑以下几种操作符)
或:|, 闭包:* ,左右括号:(),隐含的连接操作符:即AB;
②非操作符:除了以上操作符的字符均可作为非操作符,如字母、数字等;
2)正规式转NFA由以下几种基础的情况组成:
①输入为空 ε:
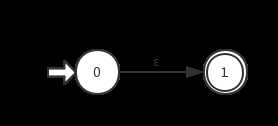
②输入为单个字符a:
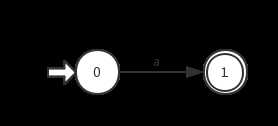
③输入为a|b(或运算):
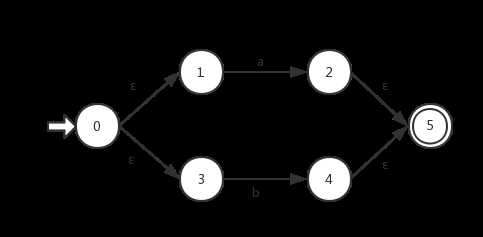
④输入为a*(闭包运算):
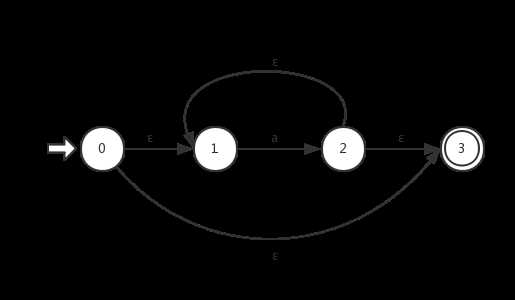
⑤输入为ab(隐含的连接运算):
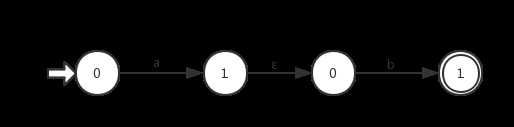
从以上5种基础情况的分析可以看出,对于每种运算操作都是有固定形式的,最基础的情况就是②,其余的几种操作符均是在这种情况下通过增加头尾节点和状态转换方向导出的。因此对于不同的操作符、对应的NFA以及状态转换符,仅需要在原先的NFA基础上增加首尾节点和状态转换即可构造新的NFA,以下为代码:
public class GenerateNFAMethod { GetStateNumber getNum = new GetStateNumber(); char nul = ‘E‘;//nul表示状态转换条件为空 //当遇到非符号数时只需新建一个NFA,其中包含起点和终点; public NFA meetNonSymbol(char nonSymbol){ NFANode headNode = new NFANode(getNum.getStateNum(),nul); NFANode tailNode = new NFANode(getNum.getStateNum(),nonSymbol);//入方向的符号为nonSymbol headNode.nextNodes.add(tailNode); NFA newNFA = new NFA(headNode,tailNode); return newNFA; } //当遇到符号数‘*‘时增加头尾节点并连接 public NFA meetStarSymbol(NFA oldNFA){ NFANode oldHeadNode = oldNFA.headNode; NFANode oldTailNode = oldNFA.tailNode; NFANode newHeadNode = new NFANode(getNum.getStateNum(),nul); NFANode newTailNode = new NFANode(getNum.getStateNum(),nul); newHeadNode.nextNodes.add(oldHeadNode); newHeadNode.nextNodes.add(newTailNode); oldTailNode.nextNodes.add(newTailNode); oldTailNode.nextNodes.add(oldHeadNode); NFA newNFA = new NFA(newHeadNode,newTailNode); return newNFA; } //当遇到符号数为‘.‘即表示连接操作时 public NFA meetAndSymbol(NFA firstNFA, NFA secondNFA){ //前一个NFA的尾节点与后一个NFA的头节点相连,需要增加头尾节点重新组成一个NFA; NFANode newHeadNode = new NFANode(getNum.getStateNum(),nul); NFANode newTailNode = new NFANode(getNum.getStateNum(),nul); firstNFA.tailNode.nextNodes.add(secondNFA.headNode); newHeadNode.nextNodes.add(firstNFA.headNode); secondNFA.tailNode.nextNodes.add(newTailNode); NFA newNFA = new NFA(newHeadNode,newTailNode); return newNFA; } //当遇到符号数为‘|‘时添加头尾节点进行或操作 public NFA meetOrSymbol(NFA firstNFA, NFA secondNFA){ NFANode oldFirstHeadNode = firstNFA.headNode; NFANode oldSecondHeadNode = secondNFA.headNode; NFANode oldFirstTailNode = firstNFA.tailNode; NFANode oldSecondTailNode = secondNFA.tailNode; NFANode newHeadNode = new NFANode(getNum.getStateNum(),nul); NFANode newTailNode = new NFANode(getNum.getStateNum(),nul); newHeadNode.nextNodes.add(oldFirstHeadNode); newHeadNode.nextNodes.add(oldSecondHeadNode); oldFirstTailNode.nextNodes.add(newTailNode); oldSecondTailNode.nextNodes.add(newTailNode); NFA newNFA = new NFA(newHeadNode,newTailNode); return newNFA; } }
【2】数据结构设计:
①双栈设计:NFA栈以及符号栈,两者均含有pop()、push()、top()操作;
②NFA栈中存储的元素为NFA图,以下为NFA图的设计:
1‘ NFA图由两个NFANode组成,一个表示NFA图的头节点,一个表示NFA图的尾节点,各种运算符操作都是在原先的NFA图的首尾节点上进行操作的,而对NFA内部的节点并没有影响,故此结构 设计具有其合理性;
2‘ NFANode设计:其表示NFA图中的某一个状态节点,其由3个属性构成:1、stateNum表示当前状态节点的状态标志;2、pathChar表示由前一个状态转换到当前状态所需的字符;
3、ArrayList<NFANode> nextNodes表示与当前状态后继相连的所有状态节点集合;
③符号栈中存储的元素为char类型的currentSymbol表示当前符号栈中存储的运算符;
以下为该数据结构的代码:
1、NFANode:
//构建NFA图中的节点单元 public class NFANode { public int stateNum; //pathChar表示前一个节点通过字符pathChar转到当前状态,对于同一个状态,它有很多入方向,故根据不同的入方向相应的改变pathChar的值 public char pathChar; public ArrayList<NFANode> nextNodes;//链表形式进行后继节点存储 public NFANode(int stateNum, char pathChar){ this.pathChar = pathChar; this.stateNum = stateNum; this.nextNodes = new ArrayList<NFANode>(); } }
2、NFA:
//定义存储在NFA栈中的NFA结构:头结点和尾结点 public class NFA { public NFANode headNode; public NFANode tailNode; public NFA(NFANode headNode,NFANode tailNode){ this.headNode = headNode; this.tailNode = tailNode; } }
3、NFAStack:
public class NFAStack { public NFA currentNFA;//当前位置的NFA public NFAStack nextNFA;//下一个入栈的NFA public NFAStack(NFA currentNFA){ this.currentNFA = currentNFA; this.nextNFA = null; } //定义pop方法返回栈顶元素 public void pop(){ NFA resultNFA; NFAStack tempNFA = this;//定义循环遍历器 NFAStack lastNFA = this;//定义栈中前一个NFAStack元素 if(tempNFA.nextNFA==null){ System.out.println("NFAStack 为空!"); } while(tempNFA.nextNFA!=null){ lastNFA = tempNFA; tempNFA = tempNFA.nextNFA; } resultNFA=lastNFA.nextNFA.currentNFA; lastNFA.nextNFA=null; } //定义push方法将元素加入栈顶 public void push(NFAStack newNFA){ NFAStack tempNFA = this;//定义遍历器 while(tempNFA.nextNFA!=null){ tempNFA = tempNFA.nextNFA; } tempNFA.nextNFA = newNFA; } //定义top方法 public NFA top(){ NFAStack tempNFA = this;//定义遍历器 while(tempNFA.nextNFA!=null){ tempNFA = tempNFA.nextNFA; } return tempNFA.currentNFA; } }
4、SymbolStack:
public class SymbolStack { public char currentSymbol; public SymbolStack nextSymbol; public SymbolStack(char currentSymbol){ this.currentSymbol = currentSymbol; this.nextSymbol = null; } //定义pop符号栈顶元素的方法 public void pop(){ char result; SymbolStack tempStack = this;//定义符号栈遍历器 SymbolStack lastStack = this;//定义前一个栈中元素 if(tempStack.nextSymbol==null){ System.out.println("SymbolStack为空!"); } while(tempStack.nextSymbol!=null){ lastStack = tempStack; tempStack = tempStack.nextSymbol; } result = lastStack.nextSymbol.currentSymbol; lastStack.nextSymbol = null; } //定义push方法加入栈顶元素 public void push(SymbolStack newSymbol){ SymbolStack tempStack = this; while(tempStack.nextSymbol!=null){ tempStack = tempStack.nextSymbol; } tempStack.nextSymbol = newSymbol; } public char top(){ SymbolStack tempStack = this; while(tempStack.nextSymbol!=null){ tempStack = tempStack.nextSymbol; } return tempStack.currentSymbol; } }
【3】基于以上的基本概念和规定,进行以下的算法分析设计:
1)算法整体想法阐述:将正规式转成NFA实质上就是对输入的字符串进行处理,通过不断的读入字符增加首尾节点和状态转换后转化为一张NFA图,有点类似于中缀转后缀的思想。我的处理方式是建立两个栈:符号栈和NFA栈。在从左至右读入正规式的字符时对字符进行判断,若其为操作符,则将其压入符号栈中,若为非操作符,则将该字符转换为NFA后压入NFA栈中,当读完最后一个字符后将符号栈中的操作符一一弹出,弹出一个操作符跟着弹出两个NFA栈的栈顶NFA,根据相应的操作符对两个NFA进行处理后转换为新的NFA压入NFA栈中。当处理完所有的符号栈中的符号后弹出NFA栈中的唯一元素即为我们所求的NFA(详细处理将在下面阐述)
2)针对非操作符以及各种操作符的详细处理:
1‘ 当遇到左括号’(‘时:直接压入栈中即可;
2‘ 当遇到右括号‘)‘时:依次弹出符号栈中的符号直到遇到‘(‘为止。在依次弹出符号栈中的符号时对NFA栈中的NFA元素的操作是:弹出NFA栈顶的两个元素,进行相应的符号操作后合成一个新的NFA并压入栈中;
3‘ 当遇到或操作‘|‘时:此操作符的优先级最低,在压入栈时需要对符号栈中‘(‘以上的符号进行判断,对于优先级高于或操作的连接操作需要将其先弹出后进行连接操作,直到栈中不存在连接操作后再将‘|‘压入符号栈中;
4‘ 当遇到闭包操作‘*‘时:此操作符的优先级最高,无须将其压入符号栈中,直接将NFA栈中的栈顶NFA弹出栈后进行闭包操作后再将新的NFA压入NFA栈;
5‘ 当遇到隐含的连接操作‘.‘时:该操作符是隐含在正规式中的 ,如:ab,a(b|c)*。因此在扫描过程中,需要对是否添加连接符进行判断。其有以下三种情况:当遇到非运算符时,需要对其后面的符号进行判断,若遇到左括号或非运算符时,则需要往符号栈中添加连接符‘.‘;当遇到闭包运算符‘*‘时,需要判断其右边的符号,若非‘|‘和‘)‘则需要在符号栈中天年假连接符‘*‘;当遇到右括号‘)‘时需要对其右边的符号进行判断,若遇到‘(‘或非运算字符时需要加入连接符‘.‘;
在处理完正规式中的字符后,若符号栈中仍有符号存在,则依次弹出符号栈中的元素和NFA中的NFA,不断进行计算后得到最终的NFA结果。以下代码为即为上述描述的代码形式:
public NFA getFinalNFA(String regExp){ //建立符号栈和NFA栈 NFAStack nfaStack = new NFAStack(null); SymbolStack symbolStack = new SymbolStack(‘0‘); NFAStack nfaHead = nfaStack; SymbolStack symbolHead = symbolStack; //对读入的字符串进行处理 for(int i=0;i<regExp.length();i++){ char cha = regExp.charAt(i); switch(cha){ case ‘(‘: //遇到左括号就要放入栈 symbolHead.push(new SymbolStack(‘(‘)); break; case ‘|‘: //或符号优先级最低,遇到这个符号要进行优先级的判断,当遇到连接符‘.‘时就一直top和pop运算 while(symbolHead.top()==‘.‘){ NFA secondNFA = nfaHead.top(); nfaHead.pop(); NFA firstNFA = nfaHead.top(); nfaHead.pop(); NFA newAndNFA = generator.meetAndSymbol(firstNFA, secondNFA); nfaHead.push(new NFAStack(newAndNFA)); symbolHead.pop(); } symbolHead.push(new SymbolStack(‘|‘)); break; //遇到‘*‘直接改变NFA栈顶元素后再将其压入栈 case ‘*‘: NFA topNFA = nfaHead.top(); nfaHead.pop(); NFA newNFA = generator.meetStarSymbol(topNFA); nfaHead.push(new NFAStack(newNFA)); if(i!=regExp.length()-1&®Exp.charAt(i+1)!=‘|‘&®Exp.charAt(i+1)!=‘)‘){ symbolHead.push(new SymbolStack(‘.‘)); } break; case ‘)‘: while(symbolHead.top()!=‘(‘){ NFA secondNFA = nfaHead.top(); nfaHead.pop(); NFA firstNFA = nfaHead.top(); nfaHead.pop(); if(symbolHead.top()==‘.‘){ NFA newAndNFA = generator.meetAndSymbol(firstNFA, secondNFA); nfaHead.push(new NFAStack(newAndNFA)); } else{ NFA newOrNFA = generator.meetOrSymbol(firstNFA, secondNFA); nfaHead.push(new NFAStack(newOrNFA)); } symbolHead.pop(); } symbolHead.pop(); //判断右括号右边的字符是否为‘(‘或非运算符 if(i!=regExp.length()-1&®Exp.charAt(i+1)!=‘)‘&®Exp.charAt(i+1)!=‘|‘&®Exp.charAt(i+1)!=‘*‘){ symbolHead.push(new SymbolStack(‘.‘)); } break; default: NFA nonSymbolNFA = generator.meetNonSymbol(cha); //判断连接符是否要加 //连接符优先级较大,所以可以直接加 if(i!=regExp.length()-1&®Exp.charAt(i+1)!=‘|‘&®Exp.charAt(i+1)!=‘*‘&®Exp.charAt(i+1)!=‘)‘){ symbolHead.push(new SymbolStack(‘.‘)); } nfaHead.push(new NFAStack(nonSymbolNFA)); break; } } //字符串读完后符号栈中元素若不为空则需要从栈顶配合NFA栈进行清空操作 while(symbolHead.top()!=‘0‘){ char symbol = symbolHead.top(); symbolHead.pop(); NFA secondNFA = nfaHead.top(); nfaHead.pop(); NFA firstNFA = nfaHead.top(); nfaHead.pop(); switch(symbol){ case ‘|‘: NFA newOrNFA = generator.meetOrSymbol(firstNFA, secondNFA); nfaHead.push(new NFAStack(newOrNFA)); break; case ‘.‘: NFA newAndNFA = generator.meetAndSymbol(firstNFA, secondNFA); nfaHead.push(new NFAStack(newAndNFA)); break; } } //最后仅剩NFA栈顶的一个最终的元素 return nfaHead.top(); }
三、由NFA转DFA:
经过步骤二中的分析与设计,我们已经成功的将正规式转成了NFA图,剩下的就是在已知NFA的图上进行操作,将NFA转换成DFA。NFA与DFA之间的联系点就是DFA中的一个状态是由NFA中的若干个状态所组成的,因此需要对DFA数据结构进行设计:
①DFANode:其由三个属性组成:beginState(起始DFA状态)、endState(终止DFA状态)、pathChar(状态转换符),表示DFA的状态转换;
②DFAState:其由四个属性组成:stateStr(状态名)、NFAState(组成该DFA状态的NFA状态集合)、isBegin(是否为起始节点)、isEnd(是否为终止节点),表示DFA中的一个状态;
以下为两个数据结构的设计代码:
//描述DFA图中的某一个状态的基本要素; public class DFAState { public String stateStr; public ArrayList<Integer> NFAState; public boolean isBegin; public boolean isEnd; public DFAState(String stateStr, ArrayList<Integer> NFAState, boolean isBegin, boolean isEnd){ this.stateStr = stateStr; this.NFAState = NFAState; this.isBegin = isBegin; this.isEnd = isEnd; } }
//描述DFA图中的状态转换节点,包括起始状态、终止状态、转换字符 public class DFANode { public DFAState beginState; public DFAState endState; public char pathChar; public DFANode(DFAState beginState, DFAState endState, char pathChar){ this.beginState = beginState; this.endState = endState; this.pathChar = pathChar; } }
NFA中存在空转,因此能通过空转到达的状态都视作同一个状态,因此如何找到NFA中相同的状态并将它们重新组合成一个新的DFA状态就成了我们的主要矛盾。我对该算法的设计分为以下两步走:
对于NFA中的一个状态N1,当前输入的字符为a,建立一个新的空状态集D1
①首先将状态N1能够通过字符a到达的状态全部加入到空状态集D1中;
②对D1中的状态进行操作:对于D1中的每一个NFA状态,将其能够通过空跳转所能到达的NFA状态节点加入到D1中,该操作需要用递归实现,且考虑到了NFA中的后继节点可能会产生重复,所以要检查 到达的节点是否有重复节点;
经过以上两步之后得到的状态集D1即构成了NFA中的状态N1通过字符a所能到达的DFA状态。而在实际进行NFA转DFA时,起始状态的即为NFA中的起始状态通过空跳转所能到达的状态所构成的一个NFA状态的集合,因此需要通过循环来对该状态集中的每一个NFA状态进行以上的两步,且输入的字符为字符集即正规式中存在所有非运算符集。对于每一个字符,从最初的DFA状态开始,不断的进行以上两步操作,得到新的状态集,判断该状态集是否已经存在,若不存在则将新的状态集加入到已知状态集集合中,直到最终不在产生新的状态集为止。在这一过程中,我们得到了DFA中的初始状态、终止状态以及转换字符,即完成了由NFA到DFA的转换,这就是著名的子集构造法。以下为NFA转DFA的核心代码:
//返回最终的DFA状态转换节点 ArrayList<DFANode> resultDFANodes = new ArrayList<>(); //记录NFA状态图中的起始状态和终止状态 int beginNFAState = resultNFA.headNode.stateNum; int endNFAState = resultNFA.tailNode.stateNum; //获取正则表达式中的除运算符外的字符 ArrayList<Character> characterList = getStateStr.getCharacters(regExp); //获取起始节点通过控制所能到达的左右状态节点 ArrayList<NFANode> initialState = new ArrayList<>(); initialState.add(resultNFA.headNode); ArrayList<NFANode> tempState = findNulMatchNFANodes(initialState,new ArrayList<NFANode>()); //建立一个list表示已有的未标记的状态,其中元素为含有NFANode的list ArrayList<ArrayList<NFANode>> unsignedState = new ArrayList<>(); ArrayList<ArrayList<Integer>> unsignedStateNums = new ArrayList<>(); //建立一个Map表示存储已产生的状态,键为list,值表示状态名;用来查找现有状态的状态名 Map<ArrayList<Integer>,String> existState = new HashMap<ArrayList<Integer>,String>(); unsignedState.add(tempState); unsignedStateNums.add(getStateNumList(tempState)); existState.put(getStateNumList(tempState), getStateStr.getStateStr()); while(!unsignedState.isEmpty()){ DFAState beginState = new DFAState(existState.get(getStateNumList(unsignedState.get(0))),getStateNumList(unsignedState.get(0)),testIsBegin(beginNFAState,getStateNumList(unsignedState.get(0))),testIsEnd(endNFAState,getStateNumList(unsignedState.get(0)))); for(Character cha:characterList){ ArrayList<NFANode> nextState = findNewNFAStateSet(unsignedState.get(0),cha); ArrayList<Integer> tempIntegerList = getStateNumList(nextState); //已有的状态集中不含有当前状态则新建一个状态 if(!existState.containsKey(tempIntegerList)){ existState.put(tempIntegerList, getStateStr.getStateStr()); } DFAState endState = new DFAState(existState.get(tempIntegerList),tempIntegerList,testIsBegin(beginNFAState,tempIntegerList),testIsEnd(endNFAState,tempIntegerList)); DFANode tempDFANode = new DFANode(beginState,endState,cha); resultDFANodes.add(tempDFANode); if(!unsignedStateNums.contains(tempIntegerList)){ unsignedState.add(nextState); unsignedStateNums.add(tempIntegerList); } } unsignedState.remove(0); } return resultDFANodes; } //输入旧状态节点集合和转换字符,输出新状态节点集合 public ArrayList<NFANode> findNewNFAStateSet(ArrayList<NFANode> oldNFAStateSet,char pathChar){ ArrayList<NFANode> newNFAStateSet = new ArrayList<>();//记录最终返回的NFANode状态集 if(oldNFAStateSet.size()==0){ return newNFAStateSet; } //先找到匹配的状态节点加入matchNodes中 ArrayList<NFANode> matchNodes = new ArrayList<>(); for(NFANode node:oldNFAStateSet){ for(NFANode nextNode:node.nextNodes){ if(nextNode.pathChar==pathChar&&!matchNodes.contains(nextNode)){ newNFAStateSet.add(nextNode); matchNodes.add(nextNode); } } } ArrayList<NFANode> matchResult = findNulMatchNFANodes(matchNodes,new ArrayList<NFANode>()); for(NFANode node:matchResult){ if(!newNFAStateSet.contains(node)){ newNFAStateSet.add(node); } } return newNFAStateSet; } //找到能够通过空字符转换得到的节点 public ArrayList<NFANode> findNulMatchNFANodes(ArrayList<NFANode> currentNodes,ArrayList<NFANode> NFANodeStack) { ArrayList<NFANode> newNFAStateSet = new ArrayList<>(); ArrayList<NFANode> nextNFAStateSet = new ArrayList<>(); if(currentNodes.size()==0){ return newNFAStateSet; } for(NFANode node:currentNodes){ NFANodeStack.add(node); newNFAStateSet.add(node); for(NFANode nextNode:node.nextNodes){ if(nextNode.pathChar==nul&&!NFANodeStack.contains(nextNode)){ nextNFAStateSet.add(nextNode); } } } ArrayList<NFANode> tempNodes = findNulMatchNFANodes(nextNFAStateSet,NFANodeStack); for(NFANode node:tempNodes){ if(!newNFAStateSet.contains(node)){ newNFAStateSet.add(node); } } return newNFAStateSet; }
四、DFA的最小化
从步骤三中我们已经得到了DFA中的状态转换集合,每个状态转换包含起始状态、转换字符和终止状态。然而有些DFA中的状态是无效的,有些DFA中的状态是重复的,因此需要对DFA中的这状态进行最小化操作。最小化操作需要经过两步:1、消除无用状态;2、合并等价状态;
1、消除无用状态:
什么是无用状态?无用状态即为从该自动机的开始状态出发,任何输入串也不能到达的那个状态,或者这个状态没有通路到达终态,这样的状态即称为无用状态。消除无用状态的算法我是这么设计的:从初始状态出发,遍历各种字符,将从初始状态能到达的状态放入一个集合S1中,其构成了初始状态能到达的状态;在S1的基础上,从终止状态出发,逆向遍历各种字符,将能到达的状态构成一个新的状态S2,其剔除了不能到达的终态的状态节点,以下为代码:
//定义消除无用状态的方法 public ArrayList<DFANode> eliminateNoUseState(ArrayList<DFANode> oldDFANodes){ //定义从起点能到达的节点的组合 ArrayList<DFANode> startPointReachDFANodes = new ArrayList<>(); //定义未遍历的DFA中的状态 ArrayList<String> nextDFAStates = new ArrayList<>(); //定义已遍历的DFA中的状态 ArrayList<String> existDFAStates = new ArrayList<>(); //找出开始状态为起点的节点放入开始集和遍历集 for(DFANode node:oldDFANodes){ if(node.beginState.isBegin){ startPointReachDFANodes.add(node); if(!nextDFAStates.contains(node.beginState.stateStr)){ nextDFAStates.add(node.beginState.stateStr); } } } while(!nextDFAStates.isEmpty()){ String currentState = nextDFAStates.get(0); existDFAStates.add(currentState); nextDFAStates.remove(0); for(DFANode node:oldDFANodes){ if(node.beginState.stateStr.equals(currentState)){ if(!startPointReachDFANodes.contains(node)){ startPointReachDFANodes.add(node); } if(!existDFAStates.contains(node.endState.stateStr)&&!nextDFAStates.contains(node.endState.stateStr)){ nextDFAStates.add(node.endState.stateStr); } } } } //定义能够到达终点状态的节点的组合,其为起点的逆过程 ArrayList<DFANode> reachEndPointDFANodes = new ArrayList<>(); //重置nextDFAStates和existDFAStates nextDFAStates = new ArrayList<>(); existDFAStates = new ArrayList<>(); for(DFANode node:startPointReachDFANodes){ if(node.endState.isEnd){ reachEndPointDFANodes.add(node); if(!nextDFAStates.contains(node.endState.stateStr)){ nextDFAStates.add(node.endState.stateStr); } } } while(!nextDFAStates.isEmpty()){ String currentState = nextDFAStates.get(0); existDFAStates.add(currentState); nextDFAStates.remove(0); for(DFANode node:startPointReachDFANodes){ if(node.endState.stateStr.equals(currentState)){ if(!reachEndPointDFANodes.contains(node)){ reachEndPointDFANodes.add(node); } if(!existDFAStates.contains(node.beginState.stateStr)&&!nextDFAStates.contains(node.beginState.stateStr)){ nextDFAStates.add(node.beginState.stateStr); } } } } return reachEndPointDFANodes; }
2、合并等价状态:
定义两个状态S和T是否等价状态需要满足以下两个条件:
①一致性条件:状态S和状态T必须同时为可接受状态和不可接受状态;
②蔓延性条件:对于所有输入符号,状态S和状态T必须转换到等价的状态里;
一个著名的方法“分割法”可以把DFA(不含多余的无用状态)的状态分成一些不相交的子集,使得任何不同的两个子集的状态都是可区别的,而同一子集中的任何两个状态都是等价的。我对分割法的实现如下:
①初始化DFA中的状态,将其分为终止状态和非终止状态;
②建立一个ArrayList<ArrayList<String>> splitStates,其包含切分状态子集;
③建立一个Map<ArrayList<String>,ArrayList<String>> aimStateTypeList,其键表示已存在的状态,其值表示到达该键值状态的节点的集合。对于要遍历的状态集合,输入的每一个字符都将对应着一个目标状态,将该目标状态作为map的键,然后将该状态作为该map值集合中的一个元素添加。若遍历完状态后,map中的元素仅存在一个,说明当前便利的状态集合不存在分裂,所以将改状态加入到最终的状态集合中,若出现了分裂,则将分裂后的状态加入到遍历集合中。
④循环遍历遍历集合直至遍历集合为空为止,最终得到的状态集合即为我们分割法所得到的集合,故进行相同状态的合并后得到最终的最小化DFA。
以下为代码(改代码可能存在bug,最近事情有点多就放着没管,但思路应该是正确的,这周末更新debug):
//定义分割法合并等价状态的String集合 public ArrayList<ArrayList<String>> splitSameState(ArrayList<DFANode> oldDFANodes,String regExp){ //划分最终的状态集 ArrayList<ArrayList<String>> splitStates = new ArrayList<>(); ArrayList<ArrayList<String>> resultSplitStates = new ArrayList<>(); //划分终态和非终态 ArrayList<String> terminalState = new ArrayList<>(); ArrayList<String> nonterminalState = new ArrayList<>(); //获取非运算符字符集 ArrayList<Character> characterList = getter.getCharacters(regExp); for(DFANode node:oldDFANodes){ if(node.beginState.isEnd){ if(!terminalState.contains(node.beginState.stateStr)) terminalState.add(node.beginState.stateStr); } else{ if(!nonterminalState.contains(node.beginState.stateStr)) nonterminalState.add(node.beginState.stateStr); } } if(terminalState.size()>0) splitStates.add(terminalState); if(nonterminalState.size()>0) splitStates.add(nonterminalState); while(!splitStates.isEmpty()){ ArrayList<String> currentState = splitStates.get(0); //初状态指向末状态的map,键为已存在状态,值为新分裂出来的状态 Map<ArrayList<String>,ArrayList<String>> aimStateTypeList= new HashMap<>(); for(Character cha:characterList){ for(String oldState:currentState){ for(DFANode node:oldDFANodes){ //找到当前节点对应的转换路径,加入以状态节点集合为键值的map中 if(node.beginState.stateStr.equals(oldState)&&node.pathChar==cha){ ArrayList<String> endStateList = getContainArrayList(splitStates,node.endState.stateStr); if(aimStateTypeList.containsKey(endStateList)){ aimStateTypeList.get(endStateList).add(oldState); } else{ ArrayList<String> temp = new ArrayList<>(); temp.add(oldState); aimStateTypeList.put(endStateList, temp); } } } } //如果map的大小为1说明对于当前字符来说,这个转换是到相同状态,重置后继续对下一个字符转换进行判断,否则直接break if(aimStateTypeList.size()==1){ aimStateTypeList= new HashMap<>(); continue; } else{ break; } } //判断ArrayList的长度是否为0,如果为0,说明当前的状态均为同一个状态,将该状态从splitStates中移除并加入最终的状态集 if(aimStateTypeList.size()==0){ resultSplitStates.add(currentState); splitStates.remove(0); } //否则移出旧状态,将map中的新状态均加入splitStates中 else{ splitStates.remove(0); for(ArrayList<String> newList:aimStateTypeList.values()){ splitStates.add(newList); } } } return resultSplitStates; } //找到包含当前状态的那一个切分子集 private ArrayList<String> getContainArrayList(ArrayList<ArrayList<String>> splitStates, String stateStr) { for(ArrayList<String> states:splitStates){ if(states.contains(stateStr)){ return states; } } return null; }
五、程序测试(仅进行消除无用状态的最小化操作,画图暂时没做):
①输入:a(a*|b*)a|b*
输出:s0 b s2
s1 a s3
s2 b s2
s3 a s3
s4 a s6
s0 a s1
s1 b s4
s4 b s4
分别对应起始状态、状态转换符、终止状态
②输入:1(0|1)*101
输出:s5 1 s6
s3 0 s5
s6 0 s5
s1 1 s3
s3 1 s3
s4 1 s3
s6 1 s3
s0 1 s1
s1 0 s4
s4 0 s4
s5 0 s4
欢迎指正,转载请注明出处,谢谢~
标签:等价 编译 etc fast else 标记 这一 一个 概述
原文地址:http://www.cnblogs.com/Revenent-Blog/p/7908755.html