标签:sts 去重 val time 半成品 code col values 实现
记上一次v1.0的空间爬虫之后,准备再写一个爬虫分析本人说说的点赞情况
首先分析Json:

可以发现点赞的节点为data-->vFeeds(list)-->like-->likemans(list)-->user-->nickname&uin
代码如下:
1 for i in range(0, page): 2 try: 3 html = requests.get(url_x + str(numbers) + url_y, headers=headers).content 4 data = json.loads(html) 5 6 if ‘vFeeds‘ in data[‘data‘]: 7 for vFeed in data[‘data‘][‘vFeeds‘]: 8 if ‘like‘ in vFeed: 9 for like_man in vFeed[‘like‘][‘likemans‘]: 10 qq_list.append(int(like_man[‘user‘][‘uin‘])) 11 # 这个dict需要定义在循环内,因为下面list.append()是引用传递 12 like_me_map = dict() 13 like_me_map[‘nick_name‘] = like_man[‘user‘][‘nickname‘] 14 like_me_map[‘qq‘] = like_man[‘user‘][‘uin‘] 15 like_me_list.append(like_me_map) 16 numbers += 40 17 time.sleep(10) 18 print(‘正在分析前‘ + str(numbers) + ‘条数据‘) 19 except: 20 numbers += 40 21 time.sleep(10) 22 print(‘第‘ + str(numbers) + ‘条数据附近分析出错‘)
like_me_list是一个list of dict,qq_list是所有QQ号的集合,现在定义一个dict来方便查询qq与昵称:
1 # 建立一个QQ与昵称对应的map,以便查询 2 qq_name_map = dict() 3 for man in like_me_list: 4 qq_name_map[man[‘qq‘]] = man[‘nick_name‘]
利用set实现自动去重并计算count:
1 # 计算点赞次数,并将次数与QQ映射存入map 2 qq_set = set(qq_list) 3 for qq in qq_set: 4 like_me_result[str(qq)] = qq_list.count(qq)
再按点赞次数降序排序处理,此处代码比较丑陋=。=:
1 # 以下处理为:按点赞次数排序后存入一个新的map作为最终结果,代码很不优雅=。= 2 num_result = sorted(like_me_result.values(), reverse=True) 3 print(num_result) 4 for num in num_result: 5 for key in like_me_result.keys(): 6 if like_me_result[key] == num: 7 result[qq_name_map[key]+‘(‘ + key + ‘)‘] = num
最后,写入文件,大功告成:
1 try: 2 with open(os.getcwd() + ‘\\‘ + ‘like_me_result.txt‘, ‘wb‘) as fo: 3 for k, v in result.items(): 4 record = k + ‘: 点赞‘ + str(v) + ‘次!\r\n‘ 5 fo.write(record.encode(‘utf-8‘)) 6 print("点赞数据结果分析写入完毕") 7 8 except IOError as msg: 9 print(msg)
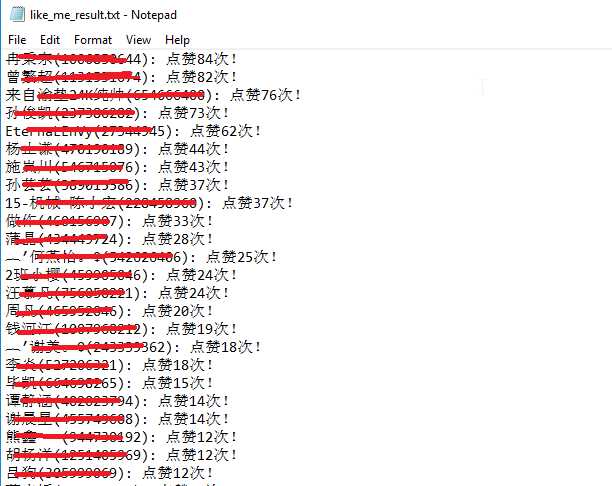
然而最后我发现一个问题,就是QQ空间返回的json点赞数据并不是完整的,如图:
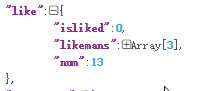
num代表点赞人数,一共13人点赞,但是我观察发现所有说说点赞人数集合likemans最多只有3个
我猜可能是因为mobile QQ空间页面不需要显示点赞信息,所以才没有完整的点赞信息,如图:
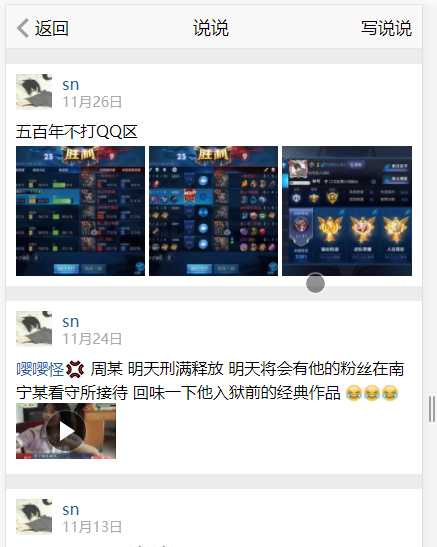
UI显示上面并没有点赞的信息显示=。=
所以这个爬虫只能算一个半成品
标签:sts 去重 val time 半成品 code col values 实现
原文地址:http://www.cnblogs.com/neilshi/p/7942923.html