标签:lang dal [1] path ref odi list open 保存
环境 Python 3 编辑器 pycharm
谷歌驱动
chromedriver.exe
微信公众号 没有的需要注册一个
爬取内容 微信公众号所有文章url和文章标题
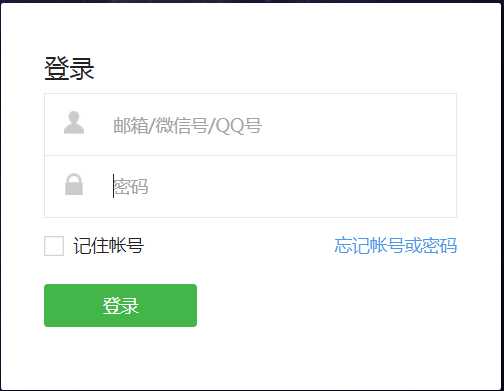
1.首先登录微信公众号
selenium
通过selenium驱动浏览器 打开登录页面 输入账号密码 登录 获取cookies 保存
2.拿到cookies之后去请求首先 会直接跳转到 个人首页 这个时候到的url 是会有token的
构造我们的data数据包
模拟post请求 返回数据
3.拿到数据之后 解析出我们需要的数据
4.翻页两种 一种是直接改变url的值 get
一种是url不变 发送的data数据变 post
5.所涉及到的主要模块有 selenium time json requests re random
1 # -*- coding:utf-8 -*- 2 3 # Author: benjaminYang 4 from slenium import webdriver 5 6 import time 7 8 import json 9 10 driver=webdriver.Chrome() #需要一个谷歌驱动 11 12 driver.get(“http://mp.weixin.qq.com”) #所要驱动操作的页面url 13 14 15 16 driver.find_element_by_xpath(‘//*[@id="header"]/div[2]/div/div/form/div[1]/div[1]/div/span/input‘).clear() #获取用户名输入框的xpath并清空 17 driver.find_element_by_xpath(‘//*[@id="header"]/div[2]/div/div/form/div[1]/div[1]/div/span/input‘).send_keys(‘你自己的公众号用户名‘) #自动填写用户名 18 time.sleep(2) 19 20 21 22 driver.find_element_by_xpath(‘//*[@id="header"]/div[2]/div/div/form/div[1]/div[2]/div/span/input‘).clear() #获取密码输入框的xpath并清空 23 24 driver.find_element_by_xpath(‘//*[@id="header"]/div[2]/div/div/form/div[1]/div[2]/div/span/input‘).send_keys(‘你的密码‘) #自动输入密码 25 26 time.sleep(2) 27 28 driver.find_element_by_xpath(‘//*[@id="header"]/div[2]/div/div/form/div[3]/label‘).click() #获取记住账号label的xpath并勾选 29 30 time.sleep(2) driver.find_element_by_xpath(‘//*[@id="header"]/div[2]/div/div/form/div[4]/a‘).click() 31 #获取登录div的xpath 并点击 32 33 time.sleep(15) 34 35 cookies=driver.get_cookies() #获取登录之后的cookies 36 37 cookie={} 38 from items in cookies: 39 cookie[items.get(‘name’)]=items.get(‘value’) #将获取到的cookies 存入到cookie字典里 40 with open(‘cookies.txt’,’w’) as file: 41 file.wrie(json.dumps(cookie) #dict转化成str 存入txt文件中 42 driver.close()
生成的文件cookies.txt格式如下:

示例图如下
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author: benjaminYang Import request Import json Import re Import random Import time def main(query): with open(‘cookies.txt’) as file: cookie=file.read() #读取cookies文件内容 url=‘https://mp.weixin.qq.com/‘ headers={‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36‘ ,‘Referer‘:‘https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&share=1&type=10&lang=zh_CN&token=1988933146‘ ,‘Host‘:‘mp.weixin.qq.com‘, } #设置请求头部 User-Agent, Referer, Host cookies=json.loads(cookie) #str转成dict response=requests.get(url,cookies=cookies) token=re.findall(‘token=(\d+)’,str(response,url))[0] #获取url中的token data={ ‘token‘:token, ‘lang‘:‘zh_CN‘, ‘f‘: ‘json‘, ‘ajax‘:‘1‘, #使用ajax异步 ‘random‘:random.random(), #生成随机数 ‘url‘:query, #搜索的文章类型 ‘begin‘:‘0‘, #从第一个文章开始 ‘count‘:‘3‘, #每页文章数目 } search_url=‘https://mp.weixin.qq.com/cgi-bin/operate_appmsg?sub=check_appmsg_copyright_sta‘ search_response=requests.post(search_url,cookies=cookies,data=data,headers=headers) max_num=search_reponse.json().get(‘total’)# 获取所有文章的条数 num=int(int(max_num/3) #文章的总页数,一页3篇除最后一页 begin=0 while num+1>0; data={ ‘token‘: token, ‘lang‘: ‘zh_CN‘, ‘f‘: ‘json‘, ‘ajax‘: ‘1‘, ‘random‘: random.random(), ‘url‘: query, ‘begin‘: ‘{}‘.format(str(begin)), ‘count‘: ‘3‘, } search_response = requests.post(search_url, cookies=cookies, data=data, headers=headers) content=search_response.json().get(‘list‘) for items in content: print (items.get(‘title‘))#标题 print (items.get(‘url‘)) #文章的url print (items.get(‘nickname‘)) num -=1 #每循环一次总页数减一 begin=int(begin) begin+=3 #每循环一次文章数加3 time.sleep(5) if __name__==’__main__’: query=input(‘请输入你要搜索的文章:’) main(query)

标签:lang dal [1] path ref odi list open 保存
原文地址:http://www.cnblogs.com/benjamin77/p/7945082.html