标签:png idt http https 向量 泛化 image 机制 建图
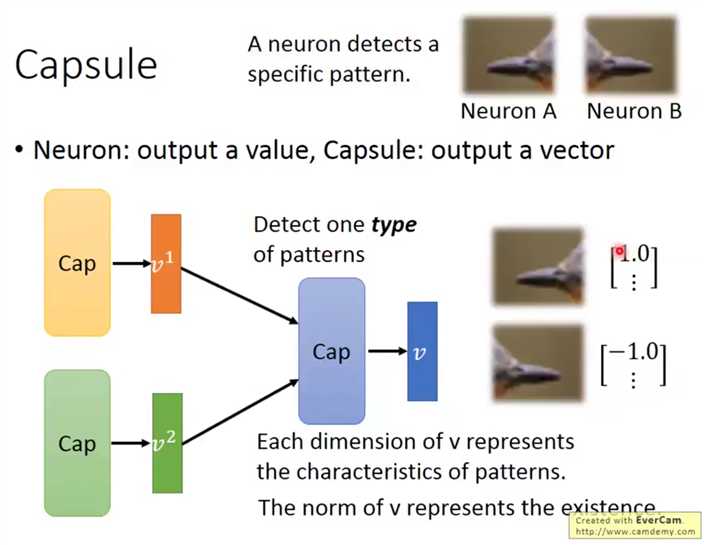
Capsule机理是使用一个向量代替传统神经网络的输出的标量信息,
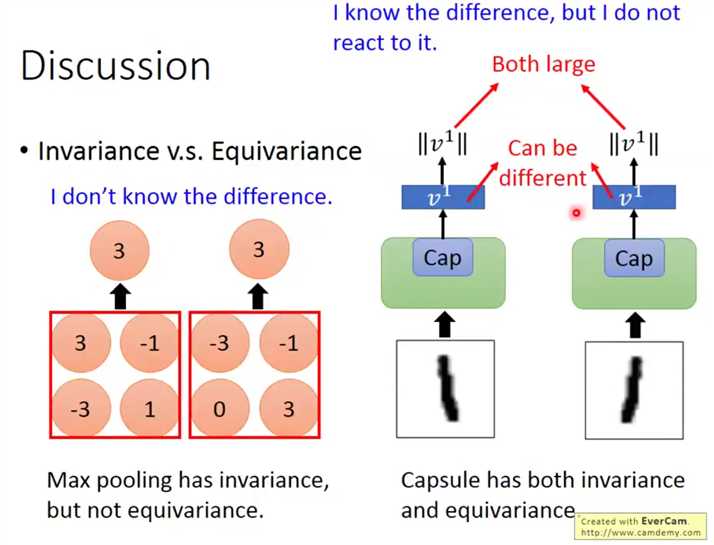
传统的标量只能表示表示出回归结果或者分类结果,不能表示出同类不同输入之间的差异,也缺少泛化性:如下向左的和向右的鸟喙并不能经由同一个网络划为一种(对于图像一些变换鲁棒性不好)。
而Capsule使用向量L2范数表示输出分类概率,而向量本身的各个元素对应着输入图像的某些特征,如下:使用第一个元素表示鸟喙的方向。
Capsule结构输入为Capsule的输出向量,输出也是向量,这个结构的提出是为了取缔pooling,使用近似聚类的方式取代pooling的简单舍弃大量信息的手法。
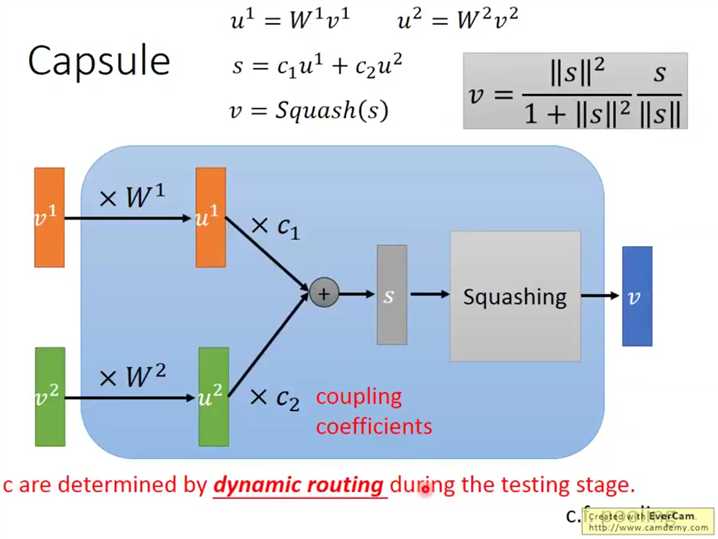
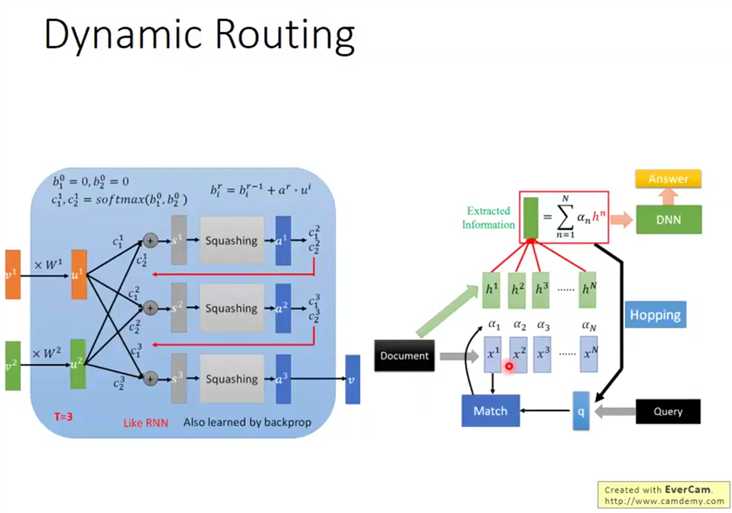
对于输入的向量v,首先乘一个矩阵W,这个W是可学习的,然后使用这个转换后的u进行下一步处理,
然后使用这些u来使用权重c计算中间结果s,s进行一个压缩得到最后的结果,这个压缩使得输出向量各个元素为0-1之间的值。
这个c实际上就是比较关键的中间参量(dynamic routing关键,不是可学习量)
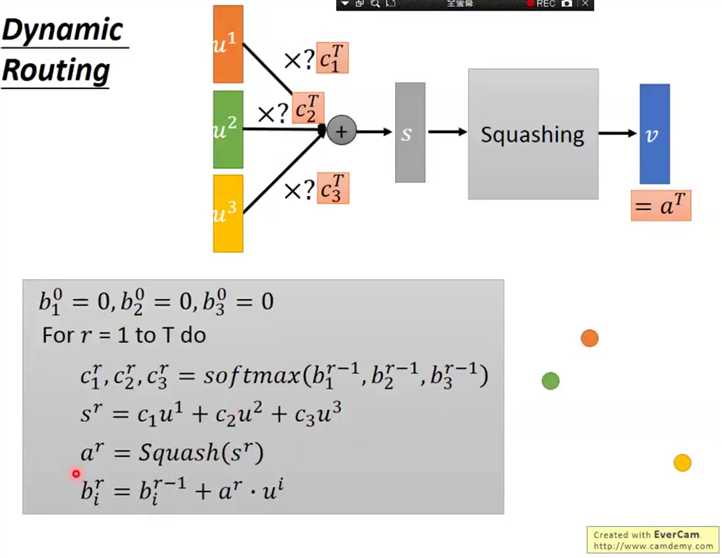
下面简单介绍一下c的用法,这实际上也是网络的精华,
初始化中间值b,个数对应输出向量数,
循环T次,属于超参数,
将b使用softmax映射为权重
各个向量加权平均
均值挤压操作,使之进入其他向量的值域(就是各个元素都在01之间的空间)
更新b,这个更新会赋予与均值接近的各个点更高权重
这样循环下来会实现数据降维(多个向量合并为一个向量),而且更够保留各个向量的信息。
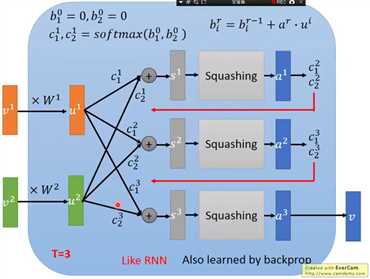
画成流程图,类似RNN,而且训练过程仍然使用的反向传播,
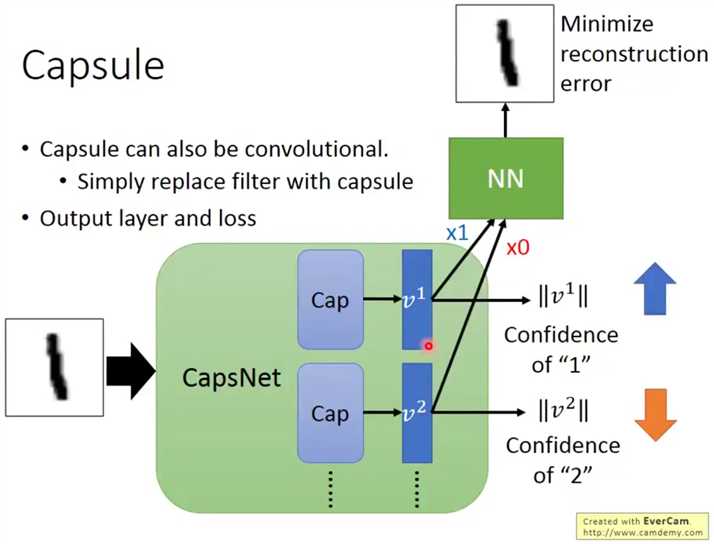
因为输出向量是可以体现输入特征的,所以还有复原图像的部分,这里会使用最大类别的输出(可以看到只有v1乘了1,其他乘的都是0),进行图像还原,
而分类部分的训练就是最大化正确类别的L2范数,最小化其他输出模长的L2范数,
比起BL(CNN网络),错误率更低(routing的次数,以及Loss是否加入重建损失 是两个超参数),而且面对干扰比传统神经网络性能更强劲,

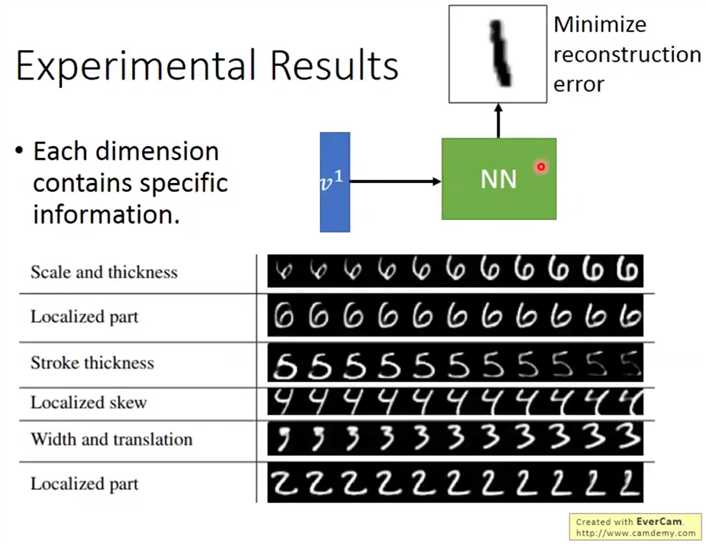
调整某个已知输入图像的输出向量的某个值,观察重建图片的变化,以验证输出向量各个元素的意义,如下,效果不错,
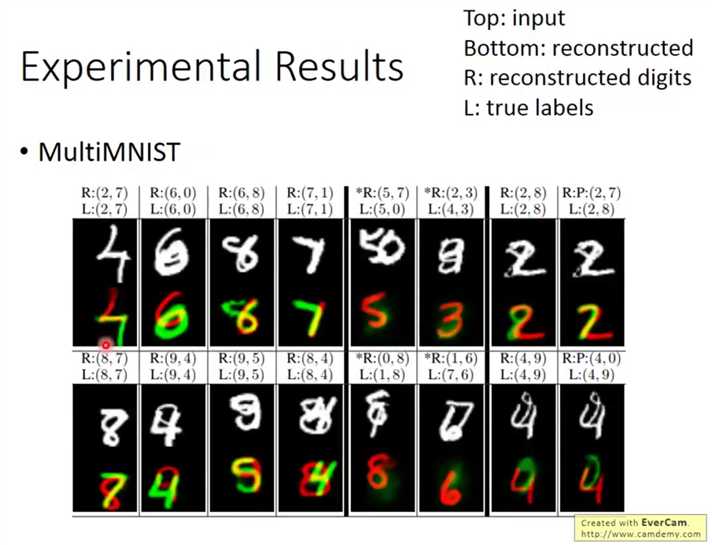
输入重叠的数字训练,输出重叠的数字,并可以复原(将两个输出向量分别送入重建模块)
根据星标的几组数据,可以看到,如果重建数字是错的,那么该错误向量还原的数字也是很模糊的,佐证了向量对于原始信息和分类肯定程度的双重含义
在保留分类信息的情况下,不同的输入有着不同的输出,可以看到输入的差异,如下,
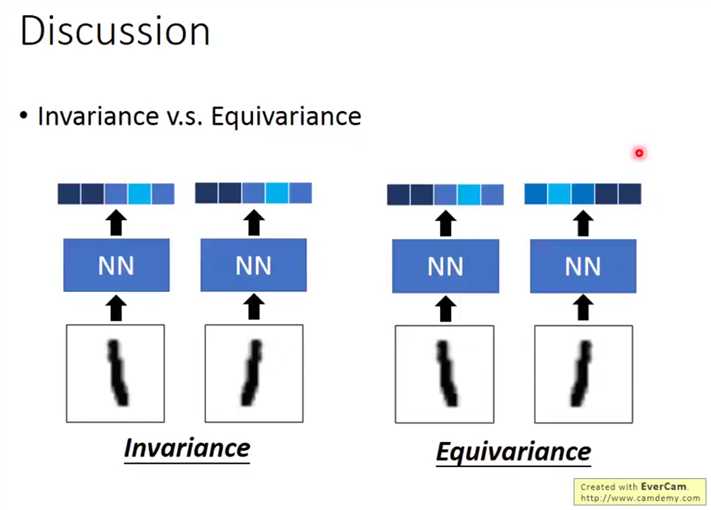
很明显,池化层没有保留这种信息,
这是李宏毅老师对其work的可能性的分析,涉及到注意力机制,不太了解,如有需要之后去补,
标签:png idt http https 向量 泛化 image 机制 建图
原文地址:http://www.cnblogs.com/hellcat/p/7954652.html