标签:.com slot chunk 分享图片 群发 重启 功能 通信 比较
本文大量参考 Redis与Memcached的区别。
如果简单地比较Redis与Memcached的区别,大多数都会得到以下观点:
抛开这些,可以深入到Redis内部构造去观察更加本质的区别,理解Redis的设计。
Memcached是 多线程,非阻塞IO复用 的网络模型,分为监听主线程和worker子线程,监听线程监听网络连接,接受请求后,将连接描述字pipe传递给worker线程,进行读写IO, 网络层使用libevent封装的事件库,多线程模型可以发挥多核作用,但是引入了cache coherency和锁的问题,比如,Memcached最常用的stats 命令,实际Memcached所有操作都要对这个全局变量加锁,进行计数等工作,带来了性能损耗。
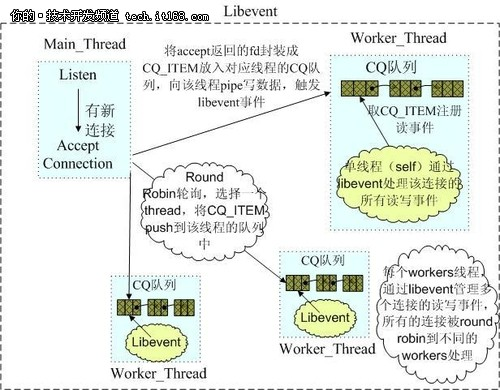
Redis使用 单线程的IO复用 模型,自己封装了一个简单的AeEvent事件处理框架,主要实现了epoll、kqueue和select,对于单纯只有IO操作来说,单线程可以将速度优势发挥到最大,但是 Redis也提供了一些简单的计算功能,比如排序、聚合等,对于这些操作,单线程模型实际会严重影响整体吞吐量,CPU计算过程中,整个IO调度都是被阻塞住的。
Memcached是全内存的数据缓冲系统,Redis虽然支持数据的持久化,但是全内存毕竟才是其高性能的本质。作为基于内存的存储系统来说,机器物理内存的大小就是系统能够容纳的最大数据量。如果需要处理的数据量超过了单台机器的物理内存大小,就需要构建分布式集群来扩展存储能力。
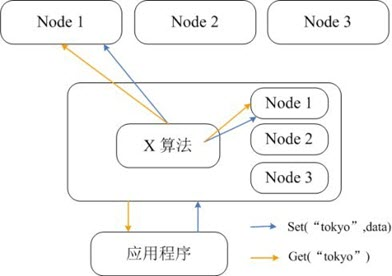
Memcached本身并不支持分布式,因此只能在客户端通过像一致性哈希这样的分布式算法来实现Memcached的分布式存储。下图给出了Memcached的分布式存储实现架构。当客户端向Memcached集群发送数据之前,首先会通过内置的分布式算法计算出该条数据的目标节点,然后数据会直接发送到该节点上存储。但客户端查询数据时,同样要计算出查询数据所在的节点,然后直接向该节点发送查询请求以获取数据。
相较于Memcached只能采用客户端实现分布式存储,Redis更偏向于在服务器端构建分布式存储。最新版本的Redis已经支持了分布式存储功能。Redis Cluster是一个实现了分布式且允许单点故障的Redis高级版本,它没有中心节点,具有线性可伸缩的功能。下图给出Redis Cluster的分布式存储架构,其中节点与节点之间通过二进制协议进行通信,节点与客户端之间通过ascii协议进行通信。在数据的放置策略上,Redis Cluster将整个key的数值域分成4096个哈希槽,每个节点上可以存储一个或多个哈希槽,也就是说当前Redis Cluster支持的最大节点数就是4096。Redis Cluster使用的分布式算法也很简单:crc16( key ) %HASH_SLOTS_NUMBER。

为了保证单点故障下的数据可用性,Redis Cluster引入了Master节点和Slave节点。在Redis Cluster中,每个Master节点都会有对应的两个用于冗余的Slave节点。这样在整个集群中,任意两个节点的宕机都不会导致数据的不可用。当Master节点退出后,集群会自动选择一个Slave节点成为新的Master节点。

根据以上比较不难看出,当我们不希望数据被踢出,或者需要除key/value之外的更多数据类型时,或者需要落地功能时,使用Redis比使用Memcached更合适。
总结:
1. Redis使用最佳方式是全部数据in-memory。
2. Redis更多场景是作为Memcached的替代者来使用。
3. 当需要除key/value之外的更多数据类型支持时,使用Redis更合适。
4. 当存储的数据不能被剔除时,使用Redis更合适。
5. 需要分布式部署时。
参考文档:
标签:.com slot chunk 分享图片 群发 重启 功能 通信 比较
原文地址:http://www.cnblogs.com/morethink/p/7978633.html