标签:span 隐式 png color error: 文章 obj 字符 div
python3有两种表示字符序列的类型:bytes和str。前者的实例包含原始的8位值;后者的实例包含Unicode字符。
python2中也有两种表示字符序列的类型,分别叫做str和unicode。与python3不同的是,str的实例包含原始的8位值,而unicode的实例,则包含Unicode字符。
上面两句话我特别不懂,所以文章后面就下是希望为了把上面两句话弄懂。
看几个例子:
#在python2中 >>> type(‘x‘.decode(‘utf-8‘)) <type ‘unicode‘> #为啥不是二进制了,字符串还能解码?再怎么解 #在python3中 >>> type(‘x‘.decode(‘utf-8‘)) #这才是正常的吗! Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: ‘str‘ object has no attribute ‘decode‘ #字符串怎么解,本来就没有吗
首先这个就是Python语言本身的问题,因为在Python2的语法中,默认的str并不是真正意义上我们理解的字符串,而是一个byte数组,或者可以理解成一个纯ascii码字符组成的字符串,与python3中的bytes类型的变量对应,而真正意义上通用的字符串则是unicode类型的变量,它与Python3中的str变量对应本来应该用作byte数组的类型却用来做字符串,你说乱不乱,之所以这样做是为了与之前的程序保持兼容。
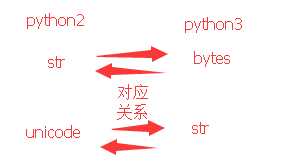
在Python2中,作为两种类型的字符序列,str与unicode需要转换,它们是这样转换的.
str——decode方法——》unicode——encode方法——》str
在python3中可以这样对应这转换,配合上面的图,也许会好理解一点。
byte——decode(解码)方法——》str——>encode(编码)方法——》byte
#在python2中 >>> type(‘x‘) <type ‘str‘> >>> type(‘x‘.decode(‘utf-8‘)) <type ‘unicode‘> >>> type(u‘x‘.encode(‘utf-8‘)) <type ‘str‘> #在python3中 >>> type(x) <class ‘str‘> >>> type(b‘x‘) <class ‘bytes‘>>>> type(b‘x‘.decode(‘utf-8‘)) <class ‘str‘>
>>> type(‘x‘.encode(‘utf-8‘))
<class ‘bytes‘>
还有就是隐式的转换,当一个unicode字符串和一个str字符串进行连接的时候,会自动将str字符串转换成unicode类型然后再连接,而这个时候使用的编码方式则是系统所默认的编码方式。python2默认的是ASCII,python3默认的是utf-8。
#在python2中 >>> x = u‘喵‘ >>> x u‘\u55b5‘ >>> type(x) <type ‘unicode‘> #在python3中 >>> x = u‘喵‘ >>> x ‘喵‘ >>> type(x) <class ‘str‘> #为啥结果不一样
关于python2中的unicode和str以及python3中的str和bytes
标签:span 隐式 png color error: 文章 obj 字符 div
原文地址:http://www.cnblogs.com/yangmingxianshen/p/7990102.html