标签:images 调度 hive 处理海量数据 其他 com 预处理 完全 mapreduce
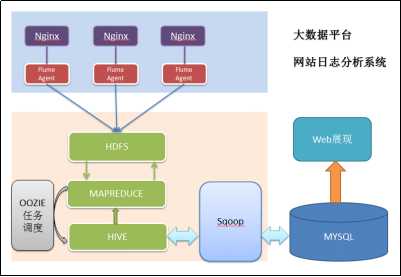
1:项目技术架构图:
2:流程图解析,整体流程如下:
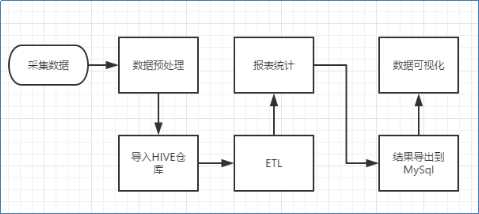
ETL即hive查询的sql;
但是,由于本案例的前提是处理海量数据,因而,流程中各环节所使用的技术则跟传统BI完全不同:
1) 数据采集:定制开发采集程序,或使用开源框架FLUME
2) 数据预处理:定制开发mapreduce程序运行于hadoop集群
3) 数据仓库技术:基于hadoop之上的Hive
4) 数据导出:基于hadoop的sqoop数据导入导出工具
5) 数据可视化:定制开发web程序或使用kettle等产品
6) 整个过程的流程调度:hadoop生态圈中的oozie工具或其他类似开源产品
3:
待续......
标签:images 调度 hive 处理海量数据 其他 com 预处理 完全 mapreduce
原文地址:http://www.cnblogs.com/biehongli/p/7874332.html