ClickHouse是一个开源的面向列式数据的数据库管理系统,能够使用SQL查询并且生成实时数据报告。
优点:
1.并行处理单个查询(利用多核)
2.在多个服务器上分布式处理
3.非常快的扫描,可用于实时查询
4.列存储非常适用于“宽”/“非规格化”表(多列)
5.良好的压缩特性
6.SQL支持(有限的支持)
7.一系列函数的支持,包括对近似计算的支持
8.不同的存储引擎的支持(磁盘存储格式)
9.非常适合结构性日志/事件数据以及时间序列数据(引擎的合并树需要日期字段)
10. 索引支持(仅主键支持,不是所有的存储引擎都支持)
11.漂亮的命令行界面,用户友好的进度条和格式
缺点:
1.不支持实时的删除/更新操作,不支持事物(与Spark和大部分大数据系统一样)
2.不支持二级索引(与Spark和大部分大数据系统一样)
3.只支持自己的协议(不支持MySQL协议)
4.有限的SQL支持,join的实现方式不同。如果您正在从MySQL或Spark迁移数据,那么您必须重新编写包含join的所有查询。
5.没有窗口功能
Group by: in-memory vs. on-disk
内存不足是在ClickHouse中处理大型数据集时可能遇到的潜在问题之一:
SELECT min(toMonth(date)), max(toMonth(date)), path, count(*), sum(hits), sum(hits) / count(*) AS hit_ratio FROM wikistat WHERE (project = ‘en‘) GROUP BY path ORDER BY hit_ratio DESC LIMIT 10 ↖ Progress: 1.83 billion rows, 85.31 GB (68.80 million rows/s., 3.21 GB/s.) ██████████▋ 6%Received exception from server: Code: 241. DB::Exception: Received from localhost:9000, 127.0.0.1. DB::Exception: Memory limit (for query) exceeded: would use 9.31 GiB (attempt to allocate chunk of 1048576 bytes), maximum: 9.31 GiB: (while reading column hits):
默认情况下,ClickHouse会限制group by使用的内存量(它使用 hash table来处理group by)。这很容易解决 - 如果你有空闲的内存,增加这个参数:
SET max_memory_usage = 128000000000; #128G,
如果你没有那么多的内存可用,ClickHouse可以通过设置这个“溢出”数据到磁盘:
set max_bytes_before_external_group_by=20000000000; #20G set max_memory_usage=40000000000; #40G
根据文档,如果需要使用max_bytes_before_external_group_by,建议将max_memory_usage设置为max_bytes_before_external_group_by大小的两倍。
(原因是聚合需要分两个阶段进行:1.查询并且建立中间数据 2.合并中间数据。 数据“溢出”到磁盘一般发生在第一个阶段,如果没有发生数据“溢出”,ClickHouse在阶段1和阶段2可能需要相同数量的内存)
性能对比:
ClickHouse vs. Spark
ClickHouse 和Spark 都是分布式的; 但是为了方便测试我们只进行单节点测试。 测试结果令人震惊
| Size / compression | Spark v. 2.0.2 | ClickHouse |
| 数据存储格式 | Parquet, compressed: snappy | Internal storage, compressed |
| Size (uncompressed: 1.2TB) | 395G | 212G |
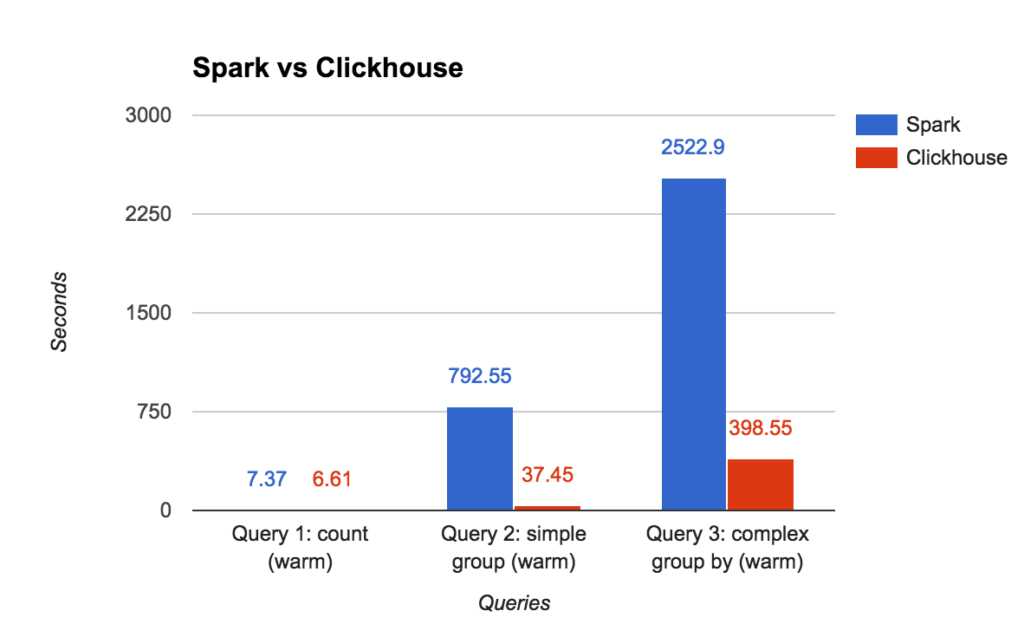
| Test | Spark v. 2.0.2 | ClickHouse | Diff |
| Query 1: count (warm) | 7.37 sec (no disk IO) | 6.61 sec | ~same |
| Query 2: simple group (warm) | 792.55 sec (no disk IO) | 37.45 sec | 21x better |
| Query 3: complex group by | 2522.9 sec | 398.55 sec | 6.3x better |
附录:
硬件
- CPU: 24xIntel(R) Xeon(R) CPU L5639 @ 2.13GHz (physical = 2, cores = 12, virtual = 24, hyperthreading = yes)
- Disk: 2 consumer grade SSD in software RAID 0 (mdraid)
Query 1
select count(*) from wikistat
ClickHouse:
:) select count(*) from wikistat; SELECT count(*) FROM wikistat ┌─────count()─┐ │ 26935251789 │ └─────────────┘ 1 rows in set. Elapsed: 6.610 sec. Processed 26.88 billion rows, 53.77 GB (4.07 billion rows/s., 8.13 GB/s.)
Spark:
spark-sql> select count(*) from wikistat; 26935251789 Time taken: 7.369 seconds, Fetched 1 row(s)
Query 2
select count(*), month(dt) as mon from wikistat where year(dt)=2008 and month(dt) between 1 and 10 group by month(dt) order by month(dt);
ClickHouse:
:) select count(*), toMonth(date) as mon from wikistat where toYear(date)=2008 and toMonth(date) between 1 and 10 group by mon; SELECT count(*), toMonth(date) AS mon FROM wikistat WHERE (toYear(date) = 2008) AND ((toMonth(date) >= 1) AND (toMonth(date) <= 10)) GROUP BY mon ┌────count()─┬─mon─┐ │ 2100162604 │ 1 │ │ 1969757069 │ 2 │ │ 2081371530 │ 3 │ │ 2156878512 │ 4 │ │ 2476890621 │ 5 │ │ 2526662896 │ 6 │ │ 2489723244 │ 7 │ │ 2480356358 │ 8 │ │ 2522746544 │ 9 │ │ 2614372352 │ 10 │ └────────────┴─────┘ 10 rows in set. Elapsed: 37.450 sec. Processed 23.37 billion rows, 46.74 GB (623.97 million rows/s., 1.25 GB/s.)
Spark:
spark-sql> select count(*), month(dt) as mon from wikistat where year(dt)=2008 and month(dt) between 1 and 10 group by month(dt) order by month(dt); 2100162604 1 1969757069 2 2081371530 3 2156878512 4 2476890621 5 2526662896 6 2489723244 7 2480356358 8 2522746544 9 2614372352 10 Time taken: 792.552 seconds, Fetched 10 row(s)
Query 3
SELECT path, count(*), sum(hits) AS sum_hits, round(sum(hits) / count(*), 2) AS hit_ratio FROM wikistat WHERE project = ‘en‘ GROUP BY path ORDER BY sum_hits DESC LIMIT 100;
ClickHouse:
:) SELECT :-] path, :-] count(*), :-] sum(hits) AS sum_hits, :-] round(sum(hits) / count(*), 2) AS hit_ratio :-] FROM wikistat :-] WHERE (project = ‘en‘) :-] GROUP BY path :-] ORDER BY sum_hits DESC :-] LIMIT 100; SELECT path, count(*), sum(hits) AS sum_hits, round(sum(hits) / count(*), 2) AS hit_ratio FROM wikistat WHERE project = ‘en‘ GROUP BY path ORDER BY sum_hits DESC LIMIT 100 ┌─path────────────────────────────────────────────────┬─count()─┬───sum_hits─┬─hit_ratio─┐ │ Special:Search │ 44795 │ 4544605711 │ 101453.41 │ │ Main_Page │ 31930 │ 2115896977 │ 66266.74 │ │ Special:Random │ 30159 │ 533830534 │ 17700.54 │ │ Wiki │ 10237 │ 40488416 │ 3955.11 │ │ Special:Watchlist │ 38206 │ 37200069 │ 973.67 │ │ YouTube │ 9960 │ 34349804 │ 3448.78 │ │ Special:Randompage │ 8085 │ 28959624 │ 3581.9 │ │ Special:AutoLogin │ 34413 │ 24436845 │ 710.11 │ │ Facebook │ 7153 │ 18263353 │ 2553.24 │ │ Wikipedia │ 23732 │ 17848385 │ 752.08 │ │ Barack_Obama │ 13832 │ 16965775 │ 1226.56 │ │ index.html │ 6658 │ 16921583 │ 2541.54 │ … 100 rows in set. Elapsed: 398.550 sec. Processed 26.88 billion rows, 1.24 TB (67.45 million rows/s., 3.10 GB/s.)
Spark:
spark-sql> SELECT > path, > count(*), > sum(hits) AS sum_hits, > round(sum(hits) / count(*), 2) AS hit_ratio > FROM wikistat > WHERE (project = ‘en‘) > GROUP BY path > ORDER BY sum_hits DESC > LIMIT 100; ... Time taken: 2522.903 seconds, Fetched 100 row(s)
参考:
https://www.percona.com/blog/2017/02/13/clickhouse-new-opensource-columnar-database/
https://clickhouse.yandex/docs/en/single/#ClickHouse%20features%20that%20can%20be%20considered%20disadvantages