参考资料
《算法(java)》 — — Robert Sedgewick, Kevin Wayne
《数据结构》 — — 严蔚敏
Interpolation Search[插值查找] — — 维基百科
Fibonacci Search[斐波那契查找] — — GeeksforGeeks
根据输入的一个关键字(Key), 在一个有序数组内查找与该关键字值相等的元素, 若找到则将该元素的下标返回, 若未查找到则返回 -1。 这是一种很常见的操作。
今天的文章主要介绍在有序数组中的三种查找方法:
- 二分查找
- 插值查找
- 裴波纳契查找
在数据量很小的情况下, 我们可能会选择用顺序查找的方式处理。
顺序查找
顺序查找, 就是逐个遍历数组中的每一个元素,逐个比较它们和关键字是否相等,当查找到相等元素时, 遍历停止。
例如在下面这个数组中查找值为8的元素的下标, 查找成功需要进行9次比较。
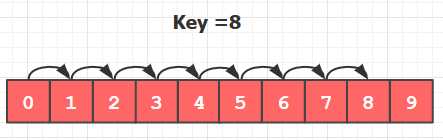

当数组的规模逐渐扩大时候, 因为比较次数太多,顺序查找耗时太长。 所以我们想, 有什么方法能减少比较的次数呢?
二分查找
在介绍二分查找前, 先让我来插一段故事。。。
这个名扬京华的食府, 在一天的多数时辰里,都是坐无虚席。
就在这时,一位慕名前来的食客。在等候许久后,终于等来了他点的菜品。
这位客人,叫做有序数组。
“先生您好, 这是您点的查找套餐”, 店小二终于赶了过来。 摆上了第一道菜。
“二分菜系么”,客人轻语着, 瞧见那盛菜的雪色素瓷上, 清晰的镌刻着 1/2 这个数字。
客人笑了,“仅凭一道家常菜,便能艳压京华众食府, 贵店的厨子果然名不虚传呢”
(未完待续)
咳咳,回到正文——二分查找
二分查找的思想
设置一个循环,不断将数组的中间值(mid)和被查找的值比较,如果被查找的值等于a[mid],就返回mid; 否则,就将查找范围缩小一半。如果被查找的值小于a[mid], 就继续在左半边查找;如果被查找的值大于a[mid], 就继续在右半边查找。 直到查找到该值或者查找范围为空时, 查找结束。


基于数组的有序性, 每次都将当前的数组分为两半, 通过关键字和中间元素的比较, 立即排除掉其中不可能存在和键值相等的元素的那一半。
这样,每次减少的一半元素的比较, 前后叠加起来, 就是二分查找相对于顺序查找提高的性能。
二分查找代码
/** * @Author: HuWan Peng * @Date Created in 22:55 2017/12/7 */ public class BinarySearch { /** * @description: 二分查找 * @param a: 待查找数组 * @param key: 查找的关键字 */ public static int search (int [] a, int key) { int low = 0; int high = a.length-1; int mid; while(low<=high){ mid = (low + high)/2; if(key<a[mid]) { high = mid - 1; } else if(key>a[mid]) { low = mid + 1; } else { return mid; } } return -1; } }
通过mid = (low + high) / 2,并比较Key和a[mid]大小, 根据比较的结果, 用high = mid - 1和low = mid + 1 “丢掉”一半的元素(从mid = (low + high) / 2 可以看出被排除的一半元素不会纳入到下一次的比较中了)
整个过程中,左游标 low 和右游标 high 互相靠近, 最后的结果可能有两个:
1. 在low和high交叉前(low>high) 查找成功,查找结束
2. 数组中没有和关键字等值的元素, 最后low和high交叉(low>high), 跳出while循环, 返回 -1。
二分查找轨迹
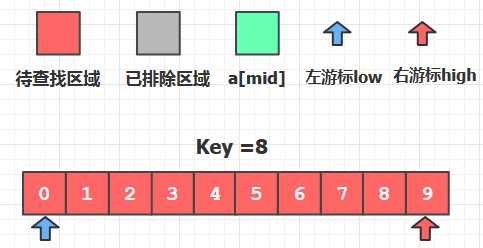
下图所示的是我们在数组中查找关键字为8的元素的过程, 一开始的时候左右游标分别指向数组的首末位置

根据左右游标的下标取中间位置下标 mid = (0 + 9)/2 = 4, 而a[mid] = a[4] = 4, Key = 8, 因为Key>a[mid],所以Key必定出现在mid的右半边, 左半边的元素可排除(a[0]~a[4]), 将左半边待比较的元素“丢弃”。 “丢弃”的方法是将左游标 low 移动到当前 mid 右边相邻的位置, 这样左半边的元素就不会出现在下次比较中了。

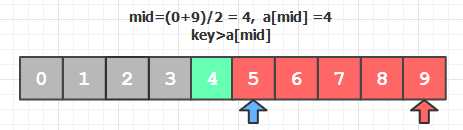
根据左右游标的下标取中间位置下标 mid = (5 + 9)/2 = 7, 而a[mid] = a[7] = 7, Key = 8, 因为Key>a[mid],所以Key还是在数组的右半边, mid左半边的元素可排除(a[5]~a[7]), 丢弃左半边待比较的元素——将左游标low移动到 8 的位置。


根据左右游标的下标取中间位置下标 mid = (8 + 9)/ 2 = 8, 而a[mid] = a[8] = 8, Key = 8, 因为Key == a[mid], 查找成功。


使用了二分查找后, 我们仅仅只比较了3次(比起比较了8次的顺序查找)
插值查找
看到这里你可能有点累了,再来段故事(接上文)
客人并没有像其他食客那样,面对珍馐美味而饕餮一番。
而是浅尝一口后, 用手巾擦擦嘴, 对店小二道:
“《二分》这道菜味道固然不错,软滑香糯,鲜美多汁”
“可这并不是你们大厨最富盛名的菜色吧!”,客人朗声说道, 平静的脸上似有似无地飘着几分愠怒的神色。
店小二一惊, 深知这位客人不是好伺候的主。“请您稍等!”,小二说完后便禀报大厨。
一刻钟后, 第二道菜上来了。
“插值菜系么?” 这位口味刁钻的客人竟面露喜色,又重新拿起了调羹。
(未完待续)
回到正题:
插值查找的思路
上面的二分查找,每次是从数组的中间位置查找的, 让我们把思维发散一下: 查找的位置一定要从中间开始查找吗?
打个比方: 我们在一本英文字典里面查找apple这个单词的时候, 你肯定不会从字典中间开始查找, 而是从字典开头部分开始翻,因为觉得这样的找法才是比较快的。
这给我提供了一个思路: 如果能在查找前较准确地预测关键字在数组中的位置的话,这样设计出的查找方法能比二分查找提高更多的性能! 基于这种思想,我们设计了插值查找的算法。
插值查找和二分查找非常相似, 只要对原代码做少许变动就可以了。
二分查找中关键的一行代码,是mid = (low + high) / 2, 转变一下就是mid = low + (high - low)/2, (high-low)后面乘的这1/2就是二分查找每次查找的位置。要实现插值查找, 只要把这里的1/2替换成我们所预测的关键字的位置占数组总长度的比例就可以了。
这个比例,可以用公式(key - a[low])/ (a[high] - a[low])来计算, 合起来插值查找对mid的计算公式是:
mid = low + (high - low)*(key - a[low])/ (a[high] - a[low])
在元素数值均匀分布的有序数组里面, 用这种方法查找是很快的。特别的,对绝对均匀分布的数组(相邻元素差值相同), 插值查找用一次比较就能查找成功:
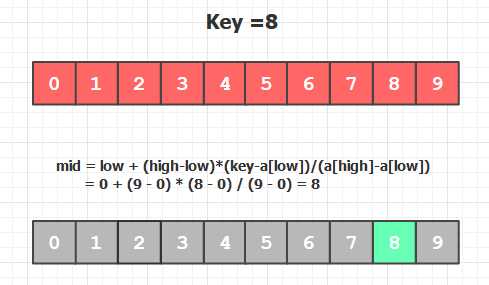

当然了, 前提是数组中元素数值是均匀分布的, 如果是对 1,2,40,99,1000这种分布很不均匀的数组, 插值查找的计算会起到反效果, 就不如二分查找了。
插值查找代码
代码如下:
/** * @Author: HuWan Peng * @Date Created in 23:09 2017/12/7 */ public class InterpolationSearch { /** * @description: 插值查找 */ public static int search (int [] a, int key) { int low = 0; int high = a.length-1; int mid; while(a[low]!=a[high]&&key>=a[low]&&key<=a[high]){ // 这个判断条件很重要! 不能缺少 mid = low + (high - low)*(key - a[low])/(a[high] - a[low]); if(key<a[mid]) { high = mid - 1; } else if(key>a[mid]) { low = mid + 1; } else { return mid; } } if(key == a[low]) return low; // 如果是 2,2,2,2,2这种全部重复元素,返回第一个2 else return -1; } }
注意, 一定要保证两点:
- a[low]!=a[high] ( 插值公式里分母是a[high] - a[low],不能等于0)
- a[low]<=key<=a[high]
用这两点作为while循环的判断条件。
while循环里的判断条件可以是low<=high吗?
不可以!! 这有可能导致在查找不存在的值时,让代码陷入while死循环
因为插值查找和二分查找很相似, 很多同学可能会想: 那我只要把mid = (low + high) / 2换成插值公式不就可以了嘛? 其他不变就OK啦。
但请注意:
mid = low + (high - low)*(key - a[low])/(a[high] - a[low]);
这个公式里, (key - a[low])在计算过程中是可能出现负值的,这个时候mid的变化就不是mid = low + 一个正值。 而是mid = low + 一个负值, mid会出现意外减少的情况,如果这个时候又刚好key>a[mid]的话, 那么low也会减少,因为:
else if(key>a[mid]) { low = mid + 1; }
然后原本只能增加(向右移动)的左游标low竟然减少(向左移动)了!
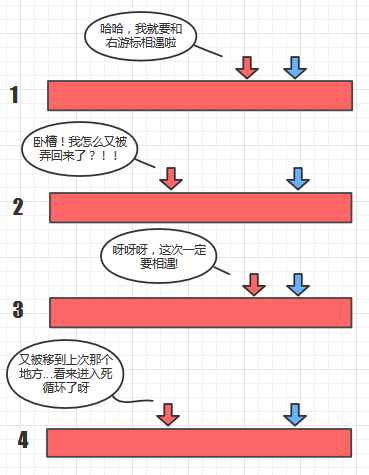

下面用debug测试: 在 1,4,6,9,11,66,78中查找22时, 每一轮的low和hign游标的值

用[low,high]表示,变化如下:
[0,6] [1,6] [2,6] [3,6] [4,6] [5,6] [3,6] // low从5倒退到3的位置, 开始死循环 [4,6] [5,6] [3,6] // 第二轮的死循环..... ......
原因也就是我上面所说的, 因为插值公式的计算里, key - a[low]计算出了负值, 在这个例子中是22 - 66 = -44所导致的。
如果你去百度“插值查找”, 几乎所有博客都告诉你, while循环里的判断条件是while(low<=high)。
对此,我只想说:


更多的可以看看这里:
处理边缘情况:重复元素
A.
有一种很讨厌的边缘情况,那就是输入的数组全部都是重复元素,例如2,2,2,2因为while循环里的a[low]!=a[high]的判断条件,所以它并不会进入while循环并造成可怕的“除0”错误, 但如果这个时候刚好key = 2, 我们总不能返回 -1 吧,所以在while循环下面我们设置了这一段代码:
if(key == a[low]) return low; // 如果是 2,2,2,2,2这种全部重复元素,返回第一个2 else return -1;
B .
你可能还担心一种情况,那就是: 对1,2,2,2,3,5这样的数组, 一开始的时候是能进入while循环的,但万一在循环中发生了a[low] - a[high] = 0 导致“除0”错误怎么办呢? 放心,从逻辑上可以判断这不会发生, 因为low和high并不会同时使a[low]和a[high]等于2, 这一点我们分类讨论:
- 对上面的数组,假设重复元素就是Key,那么当a[low]或a[high]取到该元素时就跳出while循环了
- 假设重复元素不是Key, 例如是3, 这时high不动,low会一直右移直到跳过2
- 假设重复元素不是Key,且Key不存在,例如查4,分析同2
裴波那契查找
能看到这里真是辛苦你了, 继续一段上面的故事
《插值菜系》上桌后, 已经被客人吃完了一半。这时,他却把调羹放下了。小二觉察,漫步前来。
“非常美味的料理,称之为山珍海味也不为过” , “然而, 却仍然不是我最想吃到的那道菜。”
小二愣了, 就算是权倾朝野的显贵登临, 也未曾说过此番言语。
“你们的主厨, 可是姓裴?”
店小二顿时醒悟, “请您再稍等片刻!”, 说完后便前去告知厨子
片刻, 上了第三道菜。 已经很多年没人点这道菜了, 以至于它早在这家食府的菜单上遗失。
这道菜看上去很少, 碗里却好似托着着山与海
那盛菜的青花玉盘的釉面上,清晰地镌刻着“1、1、2、3、5、8、13、21”等一连串数字。
(未完待续)
进入正题
裴波那契查找的来源
裴波那契数列是一串按照F(0)=1,F(1)=1, F(n)=F(n-1)+F(n-2)(n>=2,n∈N*)这一条件递增的一串数字:
1、1、2、3、5、8、13、21 ... ...
两个相邻项的比值会逐渐逼近0.618 —— 黄金分割比值。这个非常神奇的数列在物理,化学等各大领域上有相当的作用, 于是大家想: 能不能把它用在查找算法上嘞??
于是就有了裴波那契查找算法, 裴波那契数列最重要的一个性质是每个数都等于前两个数之和(从第三个数字开始)。 也就是一个长度为f(n)的数组,它能被分成f(n-1)和f(n-2)这两半, 而f(n-1)又能被分为f(n-2)和f(n-3)这两半。。。直到分到1和1为止(f(1)和f(2))。
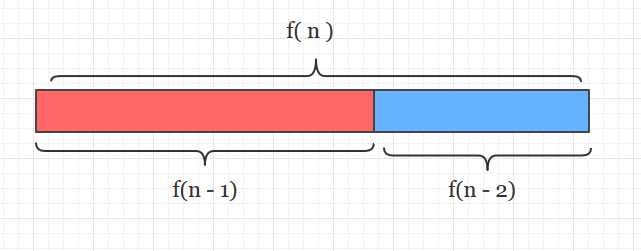

(注意一个细节: 在分割时,可以选择将“大块”的f(n-1)放前面部分,也可以将“小块”的f(n-2)放前面,我下面的分割都是按照“大块”在前进行的)
这里我们发现,二分查找, 插值查找和裴波那契查找的基础其实都是:对数组进行分割, 只是各自的标准不同: 二分是从数组的一半分, 插值是按预测的位置分, 而裴波那契是按它数列的数值分。
三个数组以及它们之间的关系。
了解裴波那契查找的算法实现, 最重要的是理解“三个数组”之间的关系,它们分别是:
- 待查找数组 (a)
- 裴波那契数组(fiboArray)
- 填充后数组(filledArray)
裴波那契数组
要按裴波那契数分割, 我们当然要创建一个容纳有裴波那契数的数组,那么,怎么确定这个数组的长度呢? 或者说, 怎么确定数组里裴波那契数的最大值呢?(最后一个值)
答:只要刚好能满足我们的需要就可以了,裴波那契数组的长度,取的是大于等于待查找数组长度的最小值。原数组长4则取5,长6则取8,长13取13(1、1、2、3、5、8、13、21 )
填充数组
其次我们要考虑的是: 我们的数组长度不可能总是满足裴波那契数的, 例如5、8、13、21等是裴波那契数, 但我们的数组长度可能是6,7,10这些非裴波那契数, 那这时候怎么办呢? 总不能对长度为10的待查找数组按照8和13进行第一次分割吧, 所以我们应该按照上面选定的裴波那契数组的最大值, 创建一个等于该长度的填充数组, 将待查找数组的元素依次拷贝到填充数组中, 剩下的部分用原待查找数组的最大值填满。
我们进行查找操作的并不是原待排序数组, 而是对应的填充数组!
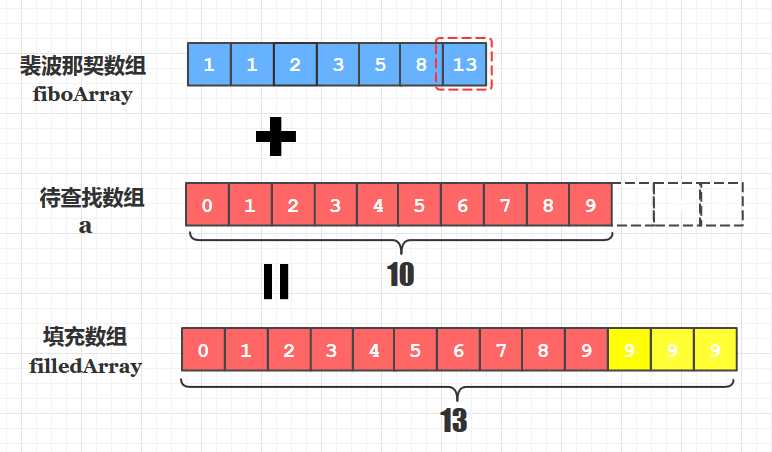

查找到填充的部分元素如何处理?
当我们在填充数组中查找成功后,该元素可能来源于在原数组的基础上填充的部分元素(上图黄色9), 返回的下标(10,11,12)显然是不准确的,而应该返回原数组的最后一个元素的下标(9) 。
所以,解决方法就是: 在填充数组中查找成功后, 判断返回的元素下标和原数组长度的关系,如果:返回下标 > 原数组长度 - 1, 那么改为返回原数组最后一个元素下标就OK了。
查找过程
OK,有了上面的基础我们总结下查找的过程:
- 根据待查找数组长度确定裴波那契数组的长度(或最大元素值)
- 根据1中长度创建该长度的裴波那契数组,再通过F(0)=1,F(1)=1, F(n)=F(n-1)+F(n-2)生成裴波那契数列为数组赋值
- 以2中的裴波那契数组的最大值为长度创建填充数组,将原待排序数组元素拷贝到填充数组中来, 如果有剩余的未赋值元素, 用原待排序数组的最后一个元素值填充
- 针对填充数组进行关键字查找, 查找成功后记得判断该元素是否来源于后来填充的那部分元素
具体代码
/** * @Author: HuWan Peng * @Date Created in 16:54 2017/12/7 */ public class FibonacciSearch { /** * @description: 创建最大值刚好>=待查找数组长度的裴波纳契数组 * @param a: 待查找的数组 */ private static int[] makeFiboArray(int[] a){ int N = a.length; int first = 1,sec = 1,third=2,fbLength = 2; int high = a[N-1]; while (third<N) { // 使得裴波那契数不断递增,直到值刚好大于等于原数组长度为止 third = first + sec; // 根据f(n) = f(n-1)+ f(n-2)计算 first = sec; sec = third; fbLength++; // 计算最后得到的裴波那契数组的长度 } int [] fb = new int[fbLength]; // 根据上面计算的长度创建一个空数组 fb[0] = 1; // 第一和一二个数是迭代计算裴波那契数的基础 fb[1] = 1; for(int i=2;i<fbLength;i++){ fb[i] = fb[i-1] + fb[i-2]; // 将计算出的裴波那契数依次放入上面的空数组中 } return fb; } /** * @description: 裴波那契查找 */ public static int search (int [] a, int key) { int low, high; int lastA; int [] fiboArray = makeFiboArray(a); // 创建最大值刚好>=待查找数组长度的裴波纳契数组 int filledLength = fiboArray[fiboArray.length-1]; int [] filledArray = new int[filledLength]; // 创建长度等于裴波那契数组最大值的填充数组 for(int i=0;i<a.length;i++) { filledArray[i] = a[i]; // 将原待排序数组的元素都放入填充数组中 } lastA = a[a.length-1]; // 原待排序数组的最后一个值 for (int i=a.length;i<filledLength;i++) { filledArray[i] = lastA; // 如果填充数组还有空的元素,用原数组最后一个元素值填满 } low = 0; high = a.length; // 取得原待排序数组的长度 (注意是原数组!) int mid; int k = fiboArray.length -1; while(low<=high) { mid = low + fiboArray[k-1]-1; if(key<filledArray[mid]) { high = mid-1; // 排除右半边的元素 k= k-1; // f(k-1)是左半边的长度 }else if(key>filledArray[mid]) { low = mid+1; // 排除左半边的元素 k = k-2; // f(k-2)是右半边的长度 }else { if(mid>high){ // 说明取到了填充数组末尾的重复元素了 return high; }else { return mid; // 说明没有取到填充数组末尾的重复元素 } } } return -1; } }
斐波那契查找的轨迹

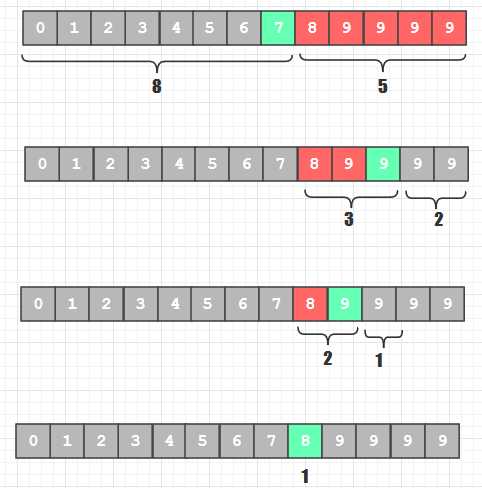
C语言和Java编写裴波那契查找的区别
C和Java语法的一大不同就是: C创建数组时候不能使用变量定义的数组长度,而Java是可以的。
例如:
int n=5; int a[n]; // C语言,会报错
int [] fb = new int[fbLength] // Java, 正常运行
所以, 用C的话就不能像Java这样自由地通过int [] fb = new int[fbLength]创建斐波那契数组了
我百度“斐波那契查找”的时候, 一大部分基于数组实现的代码都是创建了一个长度固定为20的斐波那契数组。
而第20个斐波那契数是6765,所以这样的代码只能处理长度小于等于6765的数组。
于是就有了另一种编写斐波那契数组的方法: 不依赖数组的编码方法,请看:
不依赖数组的斐波那契查找
请点这里:
说一下这种方法和我上面介绍的方法的不同点
- 我上面介绍的Java版本: 先把斐波那契数算出来,再全部用数组存起来, 要用的时候直接从数组里拿就可以了
- 这个C语言的版本: 不用数组存, 只算出来需要的最大的斐波那契数, 要用的时候“临时”计算就可以了
二分,插值和裴波纳契查找的性能比较
二分查找:
二分查找的轨迹可以用一颗判定树来表示,例如:将下面的[20,30,40,50,80,90,100]表示为一颗判定树, 因为一开始查找的是位于整个数组1/2 位置的元素50, 所以将50置于根元素位置, 接下来查找的是30或90,所以放到50的子节点的位置。
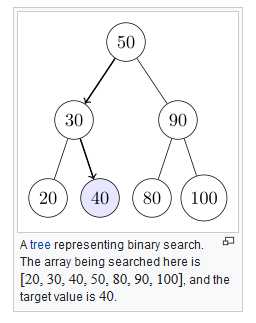

结合一个结论:具有n个节点的判定树的深度为logn2 + 1, 所以二分查找时候比较次数最多为logn2 + 1,
插值查找
上面也说过了,插值查找只适用于关键字均匀分布的表,在这种情况下, 它的平均性能比二分查找好,在关键字不是均匀分布时, 它的性能表现就不足人意了。
斐波那契查找
斐波那契查找的平均性能比二分查找好, 但最坏情况下的性能(虽然仍然是O(logn))却比二分查找差,它还有一个优点就是分割时候只需进行加减运算(二分和插值都有乘/除)
故事结尾
“能品尝到裴先生的手艺,我等食客之幸也”,
说完这句话, 食客便从店小二的视野里消失了
。。。。。。。。。。。。
——“等等! 你TM还没付饭钱就想走!!”
——“哎呀卧槽! 忘带钱了!”
于是这位食客像豪猪一般在京城的街道上奔跑, 在日暮的夕阳之下映出两人的背影, 此乃后话
(全文完)
