二.Apriori算法
上文说到,大多数关联规则挖掘算法通常采用的策略是分解为两步:
频繁项集产生,其目标是发现满足具有最小支持度阈值的所有项集,称为频繁项集(frequent itemset)。
规则产生,其目标是从上一步得到的频繁项集中提取高置信度的规则,称为强规则(strong rule)。通常频繁项集的产生所需的计算远大于规则产生的计算花销。
我们发现频繁项集的一个原始方法是确定格结构中每个候选项集的支持度。但是工作量比较大。另外有几种方法可以降低产生频繁项集的计算复杂度。
- 减少候选项集的数目。如先验(apriori)原理,是一种不用计算支持度而删除某些候选项集的方法。
- 减少比较次数。利用更高级得到数据结构或者存储候选项集或者压缩数据集来减少比较次数。
1.算法分析
Apriori算法是第一个关联规则的挖掘算法,它开创性的使用了基于支持度的剪枝技术来控制候选项集的指数级增长。Apriori算法产生频繁项集的过程有两步:第一,逐层找出当前候选项集中的所有频繁项集:第二,用当前长度的频繁项集产生长度加1的新的候选项集。
首先我们来看一下Apriori算法用到的核心原理用到的两个重要性质:
如果一个项集是频繁的,那么它的所有子集都是频繁的。
如果一个项集是非频繁的,那么它的所有超集都是非平凡的。这种基于支持度度量修剪指数搜索空间的策略称为基于支持度的剪枝,依赖于一个性质,即一个项集的支持度决不会超过它的自己的支持度,这个性质称为反之尺度度量的反单调性(anti-monotone)。
如果一个项集是非频繁项集,那么这个项集的超集就不需要再考虑了。因为如果这个项集是非频繁的,那么它的所有超集也一定都是非频繁的。在项集的超集是指,包含这个项集的元素且元素个数更多的项集。在购物篮事务库中{Milk,Beer}就是{Milk}的其中一个超集。这个原理很好理解,如果{Milk}出现了3次,{Milk,Beer}一起出现的次数一定小于3次。所以如果一个项集的支持度小于最小支持度这个阈值了,那么它的超集的支持度一定也小于这个阈值,就不用再考虑了。
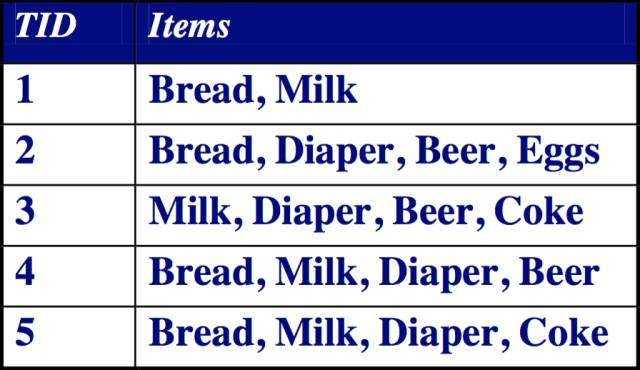
下面简单描述购物蓝事物库例子中,所有频繁项集是如何通过Apriori算法找出的。
首先,我们限定最小支持度计数为3。遍历长度为1的项集,发现{Coke}和{Eggs}不满足最小支持度计数,将它们除去。用剩余4个长度为1的频繁项集产生=6个长度为2的候选集。再次基础上重新计算支持度计数,发现{Bread, Milk}和{Milk, Beer}这两个项集是非频繁,将它们除去之后再产生长度为3的候选集。这里需要注意的是不需要再产生{Milk, Beer, Diaper}这个候选集了,因为它的其中一个子集{Milk, Beer}是非频繁的,根据先验原理这个项集本身一定是非频繁的。
2.优缺点评价:
Apriori算法的优点是可以产生相对较小的候选集,而它的缺点是要重复扫描数据库,且扫描的次数由最大频繁项目集中项目数决定,因此Apriori适用于最大频繁项目集相对较小的数据集中。
用hash树结构提高Apriori算法产生候选集的效率:
在上述的Apriori算法中我们已经知道了这个算法需要不断的进行从频繁项集中产生候选集的过程。首先找到中包含的事务的所有元素,然后在产生长度的候选集。这个过程效率是很低的,为了提高找出所有候选集的效率就要用到哈希树了。