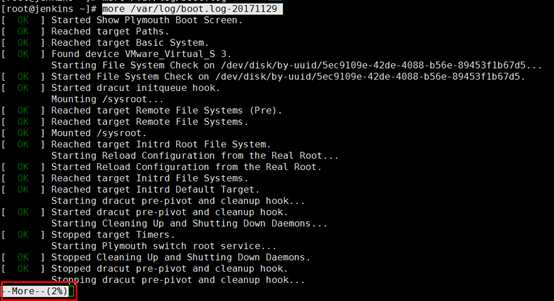
more命令
使用more命令显示more /var/log/boot.log-20171129文件,可以从图中看出,系统在显示满一个屏幕时暂停,使用空格可以翻页,使用Q键可以退出。
split
split命令可以将一个大文件分割成很多个小文件,有时需要将文件分割成更小的片段,比如为提高可读性,生成日志等。
-b:值为每一输出档案的大小,单位为 byte。
-d:使用数字作为后缀。
-a:定义数字位数
测试
[root@OD]# dd if=/dev/zero bs=100k count=1 of=data #生成一个大小为100k的文件
[root@OD]# split -b 10k data
[root@OD]# ls
data xab xad xaf xah xaj
nginx.conf xaa xac xae xag xai
文件被分割成多个小块
[root@OD]# split -b 10k data -d -a 2 ss
[root@OD]# ls
data oldboy4 ss01 ss03 ss05 ss07 ss09
nginx.conf ss00 ss02 ss04 ss06 ss08
file
file命令用来探测给定文件的类型
diff vimdiff
对比命令,文件内容进行对比。

paste
-s 则可以将一个文件中的多行数据合并为一行进行显示
paste会把每个文件以列对列的方式,一列列地加以合并。
[root@jenkins ~]# cat >>a.txt<<EOF > oldboy1 > oldboy2 > oldboy3 > EOF [root@jenkins ~]# cat >>b.txt<<EOF > oldboy4 > oldboy5 > oldboy6 > EOF [root@jenkins ~]# cat >>c.txt<<EOF > oldboy7 > oldboy8 > oldboy9 > EOF [root@jenkins ~]# paste a.txt b.txt c.txt oldboy1 oldboy4 oldboy7 oldboy2 oldboy5 oldboy8 oldboy3 oldboy6 oldboy9 [root@jenkins ~]# paste -s a.txt oldboy1 oldboy2 oldboy3
wc
wc 统计yte数、字数、或是列数
-c或--bytes或--chars 只显示Bytes数。
-l或--lines 只显示行数。
-w或--words 只显示字数
-L 统计单词有几个字母
[root@jenkins ~]# cat a.txt |wc -l 4 [root@jenkins ~]# vim a.txt [root@jenkins ~]# cat a.txt |wc -l 3 [root@jenkins ~]# cat a.txt |wc -c 24 [root@jenkins ~]# cat a.txt |wc -w 3 [root@jenkins ~]# cat a.txt |wc -L 7 [root@jenkins ~]# cat a.txt oldboy1 oldboy2 oldboy3
dos2unix
使用git 的时候碰到git将unix换行符转换为windows换行符的问题,需要使用dos2unix命令将文件转换为unix格式。
sort
管排序sort可针对文本文件的内容,以行为单位来排序。
-u选项它的作用很简单,就是在输出行中去除重复行。
sort的-r选项sort默认的排序方式是升序,如果想改成降序,就加个-r就搞定了。
sort的-o选项
由于sort默认是把结果输出到标准输出,所以需要用重定向才能将结果写入文件,形如sort filename > newfile。
-u
[
root@jenkins ~]# cat seq.txt banana apple pear orange pear [root@jenkins ~]# sort seq.txt apple banana orange pear pear [root@jenkins ~]# sort -u seq.txt apple banana orange pear
-r
[root@jenkins ~]# sort num.txt 1 2 3 4 5 6 7 8 [root@jenkins ~]# sort -r num.txt 8 7 6 5 4 3 2 1
-o
[root@jenkins ~]# sort -r num.txt -o num.txt [root@jenkins ~]# cat num.txt 8 7 6 5 4 3 2 1
uniq
uniq可检查文本文件中重复出现的行列
[root@jenkins ~]# cat seq.txt
banana
apple
orange
pear
pear
pear
pear
pear
-c或--count 在每列旁边显示该行重复出现的次数。
[root@jenkins ~]# uniq -c seq.txt 1 banana 1 apple 1 orange 5 pear
-d或--repeated 仅显示重复出现的行列。
[root@jenkins ~]# uniq -d seq.txt
pear