C# 中的基元类型、值类型和引用类型
1. 基元类型(Primitive Type)
编译器直接支持的类型称为基元类型。基元类型可以直接映射到 FCL 中存在的类型。例如,int a = 10 中的 int 就是基元类型,其对应着 FCL 中的 System.Int32,上面的代码你完全可以写作System.Int32 a = 10,编译器将生成完全形同的 IL,也可以理解为 C# 编译器为源代码文件中添加了 using int = System.Int32。
1.1 基元类型的算术运算的溢出检测
对基元类型的多数算术运算都可能发生溢出,例如
byte a = 200;
byte b = (Byte)(a + 100);//b 现在为 4 上面代码生成的 IL 如下
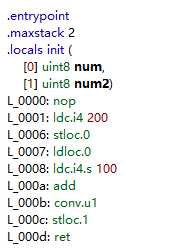
从中我们可以看出,在计算之前两个运算数都被扩展称为了32位,然后加在一起是一个32位的值(十进制300),该值在存到b之前又被转换为了Byte。C# 中的溢出检查默认是关闭的,所以上面的运算并不会抛出异常或产生错误,也就是说编译器生成 IL 时,默认选择加、减、乘以及转换操作的无溢出检查版本(如上图中的 add 命令以及conv.u1都是没有进行溢出检查的命令,其对应的溢出检查版本分别为add.ovf和conv.ovf),这样可以使得代码快速的运行,但前提是开发人员必须保证不发生溢出,或者代码能够预见溢出。
C#中控制溢出,可以通过两种方式来实现,一种全局设置,一种是局部控制。全局设置可以通过编译器的 /checked 开关来设置,局部检查可以使用 checked/unchecked 运算符来对某一代码块来进行设置。进行溢出检查后如果发生溢出,会抛出 System.OverflowException 异常。通过上述设置后编译器编译代码时会使用加、减、乘和转换指令的溢出检查版本。这样生成的代码在执行时要稍慢一些,因为 CLR 要检查这些运算是否发生溢出。
使用溢出检查
checked{
byte a = 200;
byte b = (Byte)(a + 100);
}
//亦可以通过下面的方式来实现
// byte b = checked((Byte)(a + 100));
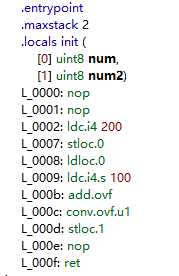
最佳实践: 在开发程序时打开 /checked+ 开关进行调试性生成,这样系统会对没有显式标记为 checked 或 unchecked 的代码进行溢出检查,此时发生异常便可以轻松捕捉到,及时修正代码中的错误 ,正式发布时使用编译器的 /checked- 开关,确保代码能够快速运行,不会产生溢出异常。
2. 值类型和引用类型
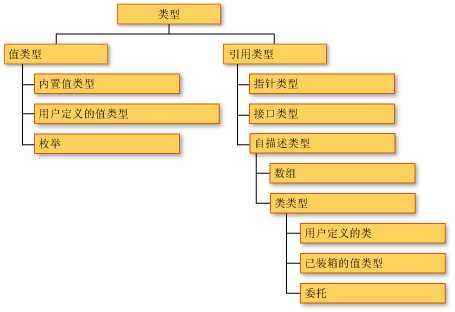
CLR 支持两种类型:值类型和引用类型,下面引用 MSDN 对两者的定义:
2.1 值类型
值类型直接包含它的数据,值类型的实例要么在堆栈上,要么在内联结构中。与引用类型相比,值类型更为"轻",因为它们不需要在托管堆上分配内存,亦不受垃圾回收器的控制,无需进行垃圾回收,C#中的值类型都派生自System.ValueType ,值类型主要包括两种类型:结构 和 枚举, 结构可以分为以下几类:
- 数值类型
- bool 类型
- char 类型
- 用户自定义的结构
值类型的特点:
- 所有的值类型都直接或间接的派生自 System.ValueType
- 值类型都是隐式密封的,即不能从其它任何类型继承,也不能派生出任何的类型,目的是防止将值类型用作其它引用类型的基类型。
- 将值类型赋值给另外一个值类型的变量时,会逐字段进行复制。
- 每种值类型都有一个默认的构造函数来初始化该类型的默认值。
自定义类型时,什么情况下适合将类型定义为值类型?
- 类型具有基元类型的特点,即该类型十分简单,没有成员会修改类型的任何实例字段
- 类型不需要从其它类型继承,亦不派生出任何的类型
- 类型的实例字段较小(16字节或更小)
- 类型的实例较大(大于16字节),但不作为方法的实参传递,也不从方法返回。
对于后两点是因为实参默认以传值的方式进行传递,造成对值类型中的字段进行复制,造成性能上的损害。被定义为返回一个值类型的方法返回时,实例中的字段会复制到调用者的分配的内存中,对性能造成损害。
值类型的装箱和拆箱
装箱:将值类型转换为引用类型的过程称为 装箱(Box).
对值类型实例进行装箱时所发生的事情如下所示:
1. 在托管堆中分配内存。分配的内存量是值类型各字段所需的内存量,还要加上托管堆所有对象都有的两个额外成员(类型对象指针和同步块索引)所需的内处量。
2. 值类型的字段复制到新分配的堆内存中
3. 返回对象的地址。现在该地址是对象的引用;值类型变成了引用类型。
注意
由于值类型的装箱需要在托管堆上分配内存,因此是较为耗费性能的,应尽量避免进行过多的装箱操作。因此许多的方法会有多个重载,目的就是减少常用值类型的发生装箱的次数;如果知道自己的代码造成编译器对一个值类型进行多次重复的装箱,可以采用手动方式进行装箱,这样的代码会更小、更快;在定义自己的类型时,可以将类型中的方法定义为泛型,这样方法便可以获取所有的类型,从而不必对值类型进行装箱。
下面通过例子对装箱进行说明
int v = 20;//创建未装箱值类型变量
object o = v;//v 引用已装箱、包含值5的int32
v = 123;//将未装箱的值修改为123
Console.WriteLine(v + "," + (int)o);//输出 "123,5"
正常情况下这里不应该这么写,因为会导致编译器发生一次多余的拆箱和装箱操作,而应该
Console.WriteLine(v+","+o);上面代码编译出的 IL 如下所示:
.entrypoint
.maxstack 3
.locals init (
[0] int32 num,
[1] object obj2)
L_0000: nop
L_0001: ldc.i4.s 20
L_0003: stloc.0
L_0004: ldloc.0
L_0005: box [System.Runtime]System.Int32
L_000a: stloc.1
L_000b: ldc.i4.s 0x7b
L_000d: stloc.0
L_000e: ldloc.0
L_000f: box [System.Runtime]System.Int32
L_0014: ldstr ","
L_0019: ldloc.1
L_001a: unbox.any [System.Runtime]System.Int32
L_001f: box [System.Runtime]System.Int32
L_0024: call string [System.Runtime]System.String::Concat(object, object, object)
L_0029: call void [System.Console]System.Console::WriteLine(string)
L_002e: nop
L_002f: ret 通过观察上述 IL 可以看出 box 指令出现了三次,说明上述代码在编译过程中发生了三次装箱。
首先在栈上创建一个 Int 32 的未装箱值类型实例v,将其初始化为5,再创建 object 类型的变量o,让它指向v,但由于引用类型的变量始终指向堆中的对象,因此 C# 会生成代码对v进行装箱,将v装箱的副本的地址存储到o中。这里进行了第一次装箱。
接着调用 WriteLine 方法,该方法要求一个 string 类型的参数,但这里没有 string 对象,只有三个数据项:未装箱的 Int32 值类型的实例v,一个字符串,一个对已装箱 Int 32 值类型实例的引用o,它要转换为值类型的 Int32,为了创建一个 string 对象,C#编译器调用 String 的 Concat 方法,由于具有三个参数,因此编译器调用 Concat 方法的如下版本的重载:Concat(Object arg0,Object arg1,Object arg2),为第一个参数传递的是v,这是一个未装箱的值参数,因此必须对v进行装箱,这是第二次装箱,第二个参数传递的是“,”,作为String 对象引用传递,对于第三个参数 arg2,o 会被转型为 Int 32,这要求进行拆箱操作,从而获取包含在已装箱的 Int 32 中未装箱的 Int 32 的地址,然后这个未装箱的值类型必须再次被装箱,这是第三次装箱。
注意:虽然未装箱的值类型没有类型对象指针,但仍然可以调用由类型继承或重写的虚方法(如
ToString,GetHashCode,Equals),并且此时并不会对值类型进行装箱操作。但在调用非虚的、继承的方法(GetType 或 MemberwiseClone) 时,无论如何都会对值类型进行装箱。因为这些方法由System.Object 定义,要求 this 实参是一个指向堆对象的指针。此外,将值类型转换为类型的某个接口时要对实例进行装箱。因为接口变量必须包括对堆对象的引用。
拆箱: Object 向值类型或接口类型向实现了该接口的值类型的显式转换称为拆箱(UnBox)
相对装箱,拆箱的代价要比装箱低的多。注意,拆箱并不是装箱的逆过程,拆箱就是获取指针(地址)的过程,该指针指向对象中的原始值类型(数据字段).拆箱时内部发生了如下的事情:
1. 如果包含“对已装箱值类型实例的引用”的变量为 Null 时,抛出 NullReferenceException 的异常。
2. 如果引用的对象不是值类型的已装箱实例,抛出 InvalidCaseException 的异常。
3. 如果前面两步都没有问题,那么将该值从实例复制到值类型的变量中。
2.2 引用类型
C# 中所有的引用类型总是从托管堆分配(初始化新进程时,CLR会为进程保留一个连续的地址空间区域,该区域称为托管堆),C#的 new 运算符返回对象的内存地址-即指向对象数据的内存地址。使用new运算符创建对象的过程如下:
- 计算类型及其所有基类型(直到System.Object)中定义的所有的实例字段所需的字节数。堆上的对象都需要一些额外的成员(OverHead),包括类型对象指针(Type Object Pointer)和同步块索引(sync block index),CLR 利用这些成员管理对象。额外成员的字节数要记入对象的大小。
- 从托管堆中分配对象所需要的字节数。从而分配对象的内存,分配的所有字节都设为0
- 初始化对象的类型对象指针和同步块索引。
- 调用类型的实例构造器。传递在调用new中指定的实参(如果有的话),大多数编译器会在构造器中自动生成代码调用基类的构造器。每个类型的构造器都负责初始化该类型定义的实例字段。最终调用 System.Object 的构造器,该构造器什么都不做,只是简单的返回。
执行完上诉的过程后 new 操作符会返回一个新建对象的引用或指针。