事物是把一些sql语句作为一个原子性操作,就是说我会写好几条sql语句,然后我想把这好几条的sql语句作为一个整体,然后让这个整体一起去运行,不可以拆分开,就像我们用面粉做一个馒头一样,我需要把这些面粉凝聚起来作为一个整体而不是散乱的个体,要是能做成馒头那这些面粉就实验成功了,若不然就失败了,成为试验品,废品,我们的sql语句就要达到这样的效果,那么馒头是面粉通过一定比例的水胶合而成的,我们的sql语句需要使用一个类似于做馒头的水这种中间介质来把它们胶合到一起作为一个整体,那么这个中间介质就是我们所说的---------------------事物.这就是事物的功能以及概念
这些sql语句通过事物这种东西已经胶合到一起成为了一个不可分割的整体了,所以如果可以顺利运行那么就一起运行,否则任何一条有问题都不会运行成功.
所以它一定会有它自己本身的格式,
首先是创建一个事物:
create transaction;
这里接着写sql语句
update count set money=money-800 where id=1;
update count set money=money+300 where id=2;
接下来就是提交事物
commit;
如果不成功就需要使用到回滚功能:
rollback;


create table user( id int primary key auto_increment, name char(32), balance int ); insert into user(name,balance) values (‘wsb‘,1000), (‘egon‘,1000), (‘ysb‘,1000); #原子操作 start transaction; update user set balance=900 where name=‘wsb‘; #买支付100元 update user set balance=1010 where name=‘egon‘; #中介拿走10元 update user set balance=1090 where name=‘ysb‘; #卖家拿到90元 commit; #出现异常,回滚到初始状态 start transaction; update user set balance=900 where name=‘wsb‘; #买支付100元 update user set balance=1010 where name=‘egon‘; #中介拿走10元 uppdate user set balance=1090 where name=‘ysb‘; #卖家拿到90元,出现异常没有拿到 rollback; commit; mysql> select * from user; +----+------+---------+ | id | name | balance | +----+------+---------+ | 1 | wsb | 1000 | | 2 | egon | 1000 | | 3 | ysb | 1000 | +----+------+---------+ rows in set (0.00 sec)
这里我们还需要引用一个概念来更加准确完善的理解事物,那就是空间的问题,我们的事物创建之后会先放在缓存区里面,理论上在mycql中我们每次执行运行操作就会产生一个事物,只要在mycql语句中我们每次运行一个带有分号的句子,系统就会觉得我们已经写完了一个完整的sql语句,然后就会创建一个事物.
在事物中如果你不执行提交commit操作的话你创建的事物就留在了缓存区,缓存区有一个特点就是数据不会永久保存的,你关闭了程序后它会被系统清空的,我们创建了事物后需要提交事物,如果提交过程中出现一部分sql语句可以顺利执行但是有一部分无法顺利执行,那么顺利执行的就会被放入缓存区,由于是一个整体,只有部分执行成功后是无法进行提交操作的,所以我们只能用到回滚功能来回收掉它,以减轻缓存空间的压力.
事物有4个特性:
1 、原子性 (事物内的操作,要么全部成功,要么全部失败)
事务是数据库的逻辑工作单位,事务中包含的各操作要么都做,要么都不做
2 、一致性 (事物之前之后,前后数据的一致性)
事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。因此当数据库只包含成功事务提交的结果时,就说数据库处于一致性状态 如果数据库系统 运行中发生故障,有些事务尚未完成就被迫中断,这些未完成事务对数据库所做的修改有一部分已写入物理数据库,这时数据库就处于一种不正确的状态,或者说是 不一致的状态。
3 、隔离性(多个事物时,相互不能干扰)
一个事务的执行不能被其它事务干扰。即一个事务内部的操作及使用的数据对其它并发事务是隔离的,并发执行的各个事务之间不能互相干扰。(如果事物在执行过程中有并发的事物也在执行同一段sql语句,也就是同样的源文件,那么就会卡主,先执行的事物没有执行完,后面也要执行同一源文件的事物就会被卡主,等在原地,一直到先执行的事物提交或者回滚之后,它才会去执行,这个概念有点类似与网络编程里面的gil锁,有人占着它就需要等到别人把它释放掉之后,其他人才可以去抢到它然后执行自己的程序)
4 、持续性(一旦事物提交(commit)之后,是不可回滚的)
也称永久性,指一个事务一旦提交,它对数据库中的数据的改变就应该是永久性的。接下来的其它操作或故障不应该对其执行结果有任何影响。 (一旦提交后就把结果从缓存区拿出来了放到了硬盘里面,也就是跟缓存区对应的物理区,硬盘存储有一个很大的特点就是数据会永久性存储)
我们这里还需要引用一个锁的功能和概念进来,
我们的数据库访问的时候是支持并发的,同时可以很多人一同访问它,那么同时访问的时候就有问题了,比如A想要查询这个数据,然后B想要删除这个数据,那么就会有故障,这就冲突了,为了解决掉这个冲突,我们需要一个锁来解决这个冲突,让一切的访问顺序化,这样就可以避免出现类似的情况了.
在实用过程中如果多个用户同时访问一个数据然后都是实用的查询的功能,那么就不会产生任何的冲突,只有在修改和删除的时候才会有冲突存在,我们为了更大限度的提高工作效率以及实现并发性能,有两个锁来解决这个问题,悲观锁锁,乐观锁,
3.开发中常见的两种锁:
3.1悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block(阻塞)直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制.
3.2 乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。
2.1 共享锁(Shared Lock,也叫S锁)
共享锁(S)表示对数据进行读操作。因此多个事务可以同时为一个对象加共享锁。(如果试衣间的门还没被锁上,顾客都能够同时进去参观)
2.2 排他锁(Exclusive Lock,也叫X锁)
排他锁也叫写锁。
排他锁表示对数据进行写操作。如果一个事务对对象加了排他锁,其他事务就不能再给它加任何锁了。(某个顾客把试衣间从里面反锁了,其他顾客想要使用这个试衣间,就只有等待锁从里面给打开了)
两种锁各有优缺点:不可认为一种好于另一种,像乐观锁适用于写入比较少的情况下,即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果经常产生冲突,上层应用会不断的进行retry(重试),这样反倒是降低了性能,所以这种情况下用悲观锁就比较合适.
我们使用锁的时候,也是有固定格式的,先来乐观锁的固定格式
-- 乐观锁的概念
需要先建立一个表格,
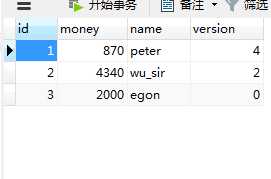
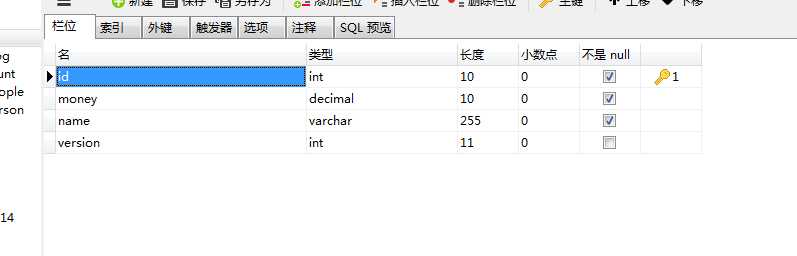
这里需要在表格里面设立一个字段,version,并且给他设立一个默认为0的约束如下sql语句
-- alter table count add version int default 0
这里就开始要使用到乐观锁了:
select * from count where id=2;
在对表格进行修改操作的时候必须要先查询,这是先决条件,
update count set money=money-30,
version=version+1 where id=2 and version=1; --- 这里我们对查询得到的结果进行修改的时候的固定格式,要基于version这个条件来进行修改,因为每次查询的时候version都会有变化,所以每次修改的时候都需要手动改变这里的version的值,这样会麻烦一点但是它省去了锁的开销,加大了整个系统的吞吐量(翻译过来就是数据库不断的被进行查询操作的时候不断的进行自我检索数据,然后不断的输出查询结果的这个过程)效率更高.
再来就是悲观锁的固定格式:
-- start transaction;
-- select * from count where id=2 for update ;
-- update count set money=2000-200 where id=1;
-- commit;
这就是悲观锁的用法格式,跟事物无异.因为事物里面有一个锁的概念,为了避免冲突的存在,它本身就会让多用户同一时间访问同一源文件的数据时有顺序进行,这就是悲观锁的实现.